Welcome to the Autumn 2010 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter.
In this issue we are pleased to provide another installment of brief articles representing a diversity of views and backgrounds. This issue includes articles from 8 guest contributors, and our own 8 staff reporters and editors.
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions.
Finally, to subscribe the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Jason Williams, Editor-in-chief
Pino Di Fabbrizio, Editor
Martin Russell, Editor
Chuck Wooters, Editor
A farewell, and a look ahead.
A celebration of the life of Fred Jelinek, speech recognition technology pioneer.
The IEEE Signal Processing Society, our parent organization, also produces a monthly newsletter, "Inside Signal Processing".
At SIGDial in Tokyo, a mentoring program was introduced, aimed to help improve papers with interesting core ideas, but problematic presentation..
The article announces a new speech separation and recognition challenge focusing on the problems of recognising speech in the reverberant multisource environments typical of everyday listening conditions.
An overview of COLING 2010, the 23rd International Conference on Computational Linguistics, which included papers, tutorials, workshops and demonstrations covering a broad spectrum of technical areas related to natural language and computation.
Marilyn Walker, one of the keynote speakers from SIGdial 2010, gave a talk on her recent work in dialogue system adaptation. We had a chance to interview Professor Walker about SpyFeet, a project exploring the impact of verbal and nonverbal behavior generation on interactive, outdoor role-playing games.
2010 NIST Speaker Recognition Evaluation or SRE10 (see SLTC Newsletter, July 2010) included a pilot test of human assisted speaker recognition (HASR). This test, which was open to sites whether or not they participated in the main evaluation of fully automatic systems, involved utilizing human expertise in combination with automatic algorithms on a limited set of trials chosen to be particularly challenging. In this evaluation, with specially chosen difficult trials, there was no evidence of human expertise contributing to system performance. But this was only a pilot test on limited numbers of trials, with little overall statistical significance. The possible contributions of human expertise on less challenging trials were not investigated.
This article provides an overview and some useful links to the INTERSPEECH 2010 satellite workshop on Second Language Studies: Acquisition, Learning, Education and Technology (L2WS 2010). The aim of the workshop is for people working in speech science and engineering, linguistics, psychology, and language education to get together and discuss second language acquisition, learning, education, and technology.
Sparse representations (SRs), including compressive sensing (CS), have gained popularity in the last few years as a technique used to reconstruct a signal from few training examples, a problem which arises in many machine learning applications. This reconstruction can be defined as adaptively finding a dictionary which best represents the signal on a per sample basis. This dictionary could include random projections, as is typically done for signal reconstruction, or actual training samples from the data, which is explored in many machine learning applications. SRs is a rapidly growing field with contributions in a variety of signal processing and machine learning conferences such as ICASSP, ICML and NIPS, and more recently in speech recognition. Recently, a special session on Sparse Representations took place at Interspeech 2010 in Makuhari, Japan from March 26-30, 2010. Below work from this special session is summarized in more detail..
We are introducing a new type of parallel corpus - a parallel corpus of dialogue and monologue. The dialogue part of the corpus consists of expository or information-delivering dialogues written by several acclaimed authors. The monologue part of the corpus has paraphrases of these dialogues in monologue form which were manually created..
SLTC Newsletter, November 2010
This is the final SLTC Newsletter of 2010 and this will be my last contribution as Chair of the SLTC since my two year term finishes at the end of this year. Our current vice-Chair John Hansen will take over from me in January 2011 and the newly-elected Doug O'Shaughnessy will be the new vice-Chair. Congratulations to both of them on their new roles, I am sure that the SLTC will be in safe hands.
Whilst there is only two months left of my tenure, there is nevertheless a great deal to do. As soon as the deadline for ICASSP 2011 has passed, our gallant Area Chairs, Pascale Fung, TJ Hazen, Brian Kingsbury and David Suendermann will commence the enormous task of processing 600+ submissions, ensuring that each paper gets 4 good quality reviews and eventually constructing the final programme for our part of ICASSP 2011 in Prague.
My period as chair of the SLTC has been one of considerable change. We have expanded the number of TC members, we now have a vice-Chair to help ensure continuity, and thanks to the efforts of Alex Acero we now have a common set of rules and procedures covering all SPS Technical Committees. This should in the future allow more sharing of best practice amongst TCs. Our newsletter has been rejuvenated thanks to the efforts of Jason Williams and his team, and we now have a more organised approach to ensuring that the more senior members of our community are elected to Fellow grade in a timely fashion. We held a very successful ASRU Workshop in Merano, Italy in 2009 and the forthcoming SLT 2010 workshop in Berkeley also looks set to be a success. None of these things are achieved without effort, of course, and I would like to thank everyone who has worked so hard for our community to make these things happen.
Finally it was a great sadness to learn that my friend, colleague and inspiration, Fred Jelinek, died suddenly on September 14th 2010. The accompanying article {cms_selflink page='662' text='Frederick Jelinek 1932 – 2010 : The Pioneer of Speech Recognition Technology'} has been adapted from a speech I gave at a dinner in Johns Hopkins in 2006 when Fred was elected to the National Academy of Engineering. It was written not as an obituary but as a celebration of his life. Nevertheless, it still seems entirely appropriate to me, and I hope you agree.
Steve Young
October 2010
Steve Young is Chair, Speech and Language Technical Committee.
SLTC Newsletter, November 2010
The speech recognition problem is fascinating because it is so simple to describe yet so astonishingly difficult to do. Humans do it effortlessly yet machine capability is still at an infant stage – and a young infant at that. Indeed, some question whether it can ever be achieved at all. In 1969, John Pierce from Bell Labs famously wrote in the Journal of the Acoustical Society of America that speech recognition was dominated by "mad scientists and untrustworthy engineers" and that "speech recognition will not be possible until the intelligence and linguistic competence of a human speaker can be built into the machine".
Despite this attack from such a leading figure as Pierce, in 1971 ARPA launched a major 5 year $15m program to solve the "speech understanding problem". ARPA saw it as an Artificial Intelligence problem and therefore funded multidisciplinary teams of computer scientists and linguists. The goal was to develop machines which could recognise continuous speech from a 1000-word vocabulary. But the ARPA programme failed and was terminated in 1976 - the problem appeared to be just too difficult.
Meanwhile, a young post-graduate called Fred Jelinek at Cornell was working to extend the PhD work that he had completed in 1962 at MIT on Channel Coding. His goal was to extend our understanding of information theory and explore its application to practical problems. This work bore fruit and he helped to establish Cornell as a major centre for information theory. IBM meanwhile had been working on speech recognition since the late 1960’s, and in the early 70’s in an apparent change of tack, Fred moved from Cornell to IBM to take over the management of their speech and language processing activities.
Not surprisingly but to the bewilderment of many others in the field, Fred’s approach to speech recognition was to view it as a channel coding problem. He asked us to imagine that the "human brain" sends a message (ie what it has in mind to say) down a noisy channel encoded as an acoustic waveform. The receiver i.e. the machine then has to use statistics to find the most probable message given the noisy acoustics. This is a simple enough concept today, but in 1970 casting speech recognition as a channel coding problem seemed pretty far-fetched. After all, Chomsky had written in his seminal 1957 work "Syntactic Structures" that "we are forced to conclude that grammar is autonomous and independent of meaning, and that probabilistic models give no insight into the basic problems of syntactic structure". By 1970, computational linguists regarded Chomsky’s position as axiomatic and so perhaps Pierce was right, perhaps Fred and his followers really were "mad scientists and untrustworthy engineers".
Despite all this, Fred began his attempts to solve the speech recognition problem with an open mind and he did have linguists in his team. However, the story goes that one day one of his linguists resigned, and Fred decided to replace him not by another linguist but by an engineer. A little while later, Fred noticed that the performance of his system improved significantly. So he encouraged another linguist to find alternative employment, and sure enough performance improved again. The rest as they say is history, eventually all the linguists were replaced by engineers (and not just in Fred’s lab) and then speech recognition really started to make progress.
The beauty of Fred’s approach was simply that it reduced the speech recognition problem to one of producing two statistical models: one to describe the prior probability of any given message, and a second to describe the posterior likelihood of an observed speech waveform given some assumed message. No intuition or introspection into the human mind was required, just real speech data to train the models.
In 1976 Fred published a now famous paper in the Proceedings of the IEEE called "Continuous Speech Recognition by Statistical Methods", and eventually his view of the problem entirely reshaped the landscape and set the foundations for virtually all modern speech recognition systems. But Fred did not just set us all in the right direction, in his 20 years at IBM, he and his team invented nearly all of the key components that you need to build a high performance speech recognition system including phone-based acoustic models, N-gram language models, decision tree clustering, and many more.
The story does not end there of course. In 1993, Fred joined Johns Hopkins University and rapidly propelled the Center for Language and Speech Processing into being one of the top research groups in the world. He engaged with the major research programs, and he started the now famous Johns Hopkins Summer Workshops on Language and Speech.
And he focused more of his own time on his own research. In particular, the statistical model of language with which he had so successfully replaced linguistic rules was a simple word trigram – ie a very crude model of three word sequences. Whilst it was obvious to everyone that this model was hopelessly impoverished, in practice it had proved almost impossible to improve on. However, in the year 2000, Fred published a paper with one of his students called "Structured language modeling for speech recognition". It sets out a principled way to incorporate linguistics into a statistical framework and as well as representing a significant step forward in language modeling, it has helped bridge the gap between speech engineers and the hitherto diverging computational linguistics community. In 2002, it received a "Best Paper" award and the citation read "for work leading to significant advances in the representation and automatic learning of syntactic structure in statistical language models". It seemed somehow fitting that 25 years after starting the movement towards statistical approaches, Fred sought to re-engage with aspects of more traditional linguistics. I hope Chomsky read the paper and enjoyed it as much as we speech technologists did.
In nearly five decades of outstanding research, Fred Jelinek made a truly enormous contribution. He was not a pioneer of speech recognition, he was the pioneer of speech recognition. His contribution has been recognized by many awards. He received the IEEE Signal Processing Society award in 1998 and the IEEE Flanagan Award in 2005. He received the ISCA Medal for Scientific Achievement in 1999 and he was made an inaugural ISCA Fellow in 2008. He was awarded an Honorary Doctorate at Charles University of Prague in 2001 and he was elected to the National Academy of Engineering in 2006.
Fred Jelinek was an inspiration to our community. He will be sorely missed by all who knew him.
Steve Young
October 2010
Steve Young is Chair, Speech and Language Technical Committee.
SLTC Newsletter, November 2010
At SIGDial in Tokyo, a mentoring program was introduced. The aim of mentoring was to help improve papers with interesting core ideas, but problematic presentation -- for example, poor English usage, organizational issues, or other reasons. One motivation for offering mentoring is to reduce the risk that innovative work is being turned away because the author(s) do not happen to have strong English language abilities.
The process used was for SIGDial paper reviewers to flag papers which would benefit from mentoring. The technical chairs decided which papers to accept "with recommendation to revise with a mentor". Mentors were not involved until after accept/reject decisions were made. This year, 7 papers were accepted with this recommendation, of a total of 53 papers accepted at SIGDial.
Members of the program committee were invited to volunteer to be mentors. This year, there were 26 volunteers. Mentors were assigned to authors based on the areas of expertise of the mentor. Also, it was ensured that mentors were not reviewers of the paper they were assigned to. One mentor was assigned per paper.
Mentors were assigned at the beginning of the paper revision period. There was a month between the start and end of the paper revision period (for authors or all papers, including papers recommended for mentoring).
Authors were asked to forward their paper and reviewer comments to the mentors. Mentors were asked to work with the author to "improve the accessibility and/or presentation of the paper." While this would probably include suggesting specific changes to the text, mentors were instructed "not to be editors" -- they were "not expected to re-write the paper for the authors." Overall responsibility for the revision and final submission of the paper remained with the author. Because the needs of each paper were different (and because this was the first year of mentoring) instructions were no more specific than this, by design.
After completion of mentoring, authors and mentors were sent a short, anonymous survey. Of the 7 lead authors and 7 mentors, 5 authors and 5 mentors responded to the survey. Of mentors, 4 of 5 felt their mentoring improved the paper (the fifth didn’t see the final copy, so couldn’t answer), and 4 of 5 felt mentoring should be offered in future SIGDial conferences. Of authors, all felt that mentoring improved their paper, and all felt that mentoring should be offered again in future SIGDial conferences.
In designing the mentoring program, other conferences and workshops were consulted to ask about their experiences (ACL, SemDial 2010, CoNLL 2010, Interspeech 2010, ASRU 2009, UAI, ICASSP 2010, IJCAI 2009, AAAI 2010, Chi 2010). Only ACL offers mentoring, although it provides it as a service to some of its affiliated events. In the ACL program, authors desiring mentoring submit 6 weeks in advance of the paper deadline, and a mentor volunteer works with the authors before the paper is sent to reviewers. 11 (of ~500 submissions to the main ACL conference) sought mentoring. The main benefit of offering mentoring before submission is that papers are presented to reviewers in the best possible light. The downside is that the deadline for mentoring is earlier, and that some papers will be mentored which will be rejected, consuming mentoring resources.
Overall, it appears mentoring accomplished its aims and was a successful addition to SIGDial 2010. It is hoped future organizers will make mentoring a regular part of SIGDial conferences.
Jason Williams was mentoring coordinator at SIGDial 2010. He is Principal Member of Technical Staff at AT&T Labs Research. His interests are dialog systems and planning under uncertainty. Email: jdw@research.att.com
SLTC Newsletter, November 2010
The article announces a new speech separation and recognition challenge focusing on the problems of recognising speech in the reverberant multisource environments typical of everyday listening conditions.
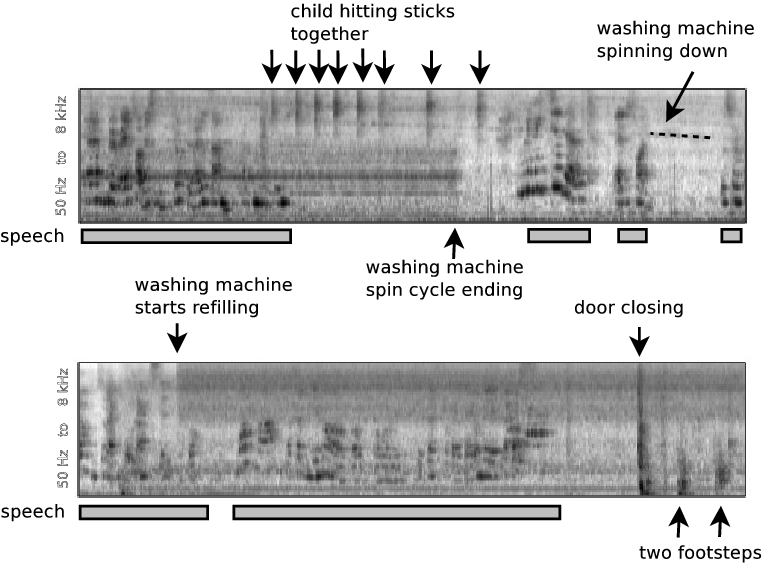
One of the chief difficulties of building distant-microphone speech recognition systems for use in 'everyday' applications, is that we live our everyday lives in acoustically cluttered environments. A speech recognition system designed to operate in a family home, for example, must contend with competing noise from televisions and radios, children playing, vacuum cleaners, outdoors noises from open windows ‒ an array of sound sources of enormous variation. Further, the noise background is essentially 'multisource', i.e. it is composed of multiple simultaneously active sound sources. The figure below, showing a time-frequency representation of 20 seconds worth of audio captured in a family living room, illustrates some of the difficulties presented by everyday listening conditions. Such domains may be complex and seemingly unpredictable but nevertheless they contain structure that can be learnt and exploited given enough data.
The central problem of recognising speech in noise backgrounds, both simple and complex, has been long studied and there are many partial solutions: systems may either attempt to filter out the effects of the noise (in either the signal domain or the feature domain), model the combination of the noise and the speech (either precisely or in terms of masking), or they may use signal-level cues such as location and pitch to un-mix the sources (scene analysis and blind source separation approaches). In narrowly specified conditions all of these approaches have been shown to be useful; but in conditions closer to real application scenarios, no one solution has yet been shown to be a clear winner.
The PASCAL 'CHiME' challenge aims to encourage the development of more flexible approaches to noise robust ASR that succeed by combining the strengths of source separation techniques with those of speech and noise modelling. It is a successor to the first PASCAL speech separation challenge, and uses the same underlying recognition task (Grid corpus utterances [1]), but it extends the earlier challenge's instantaneously-mixed speech-on-speech problem in several significant directions.
First, the noise backgrounds come from uncontrolled recordings made in an everyday listening environment. Specifically, the data comes from the Computational Hearing in Multisource Environments (CHiME) corpus that consists of around 40 hours of recordings made in a family home over a period of several weeks [2]. The target speech utterances have been embedded in these recordings in a manner that will reward approaches that attempt to model and track the various sources occurring in the acoustically cluttered background.
Second, whereas the first separation challenge employed a single audio channel, the new challenge employs recordings made using a binaural manikin. We hope that by providing binaural data we will encourage approaches that attempt to take human-like advantage of spatial source separation cues.
Third, in contrast to the instantaneous mixtures employed by many robust ASR tasks, the target utterances have been added to the backgrounds after convolution with genuine binaural room impulse responses. This convolutive noise significantly increases the difficulty of reliably extracting pitch and location-based separation cues. Artificial mixing, although removing some sources of variability that occur in a real distant microphone ASR application, allows the effective SNR to be controlled through the temporal positioning of the target utterances. In this way a range of test conditions representing SNRs from -9 dB to +6 dB has been produced. An important feature of the test set is that it employs conditions defined in terms of naturally occurring SNRs rather than in terms of SNRs that have been artificially controlled by arbitrarily scaling the level of either the signal or the noise.
In common with the first PASCAL speech separation challenge, human listener performance will be measured on the same recognition task. The human data will provide a useful benchmark for assessing the state of the art in robust speech recognition.
A full description of the challenge, including details of the source separation and recognition tasks, the construction of the noisy speech data sets, and the rules for participation can be found on the challenge web site.
Evaluation will be through speech recognition results, but in order that the challenge is accessible to the widest possible audience, participants will be allowed to submit either separated signals (to be processed by a provided recogniser), robust speech features or the outputs of complete recognition systems. We are interested in measuring the performance of emerging techniques, but we are also keen to benchmark more established approaches.
Results of the Challenge will be presented at a dedicated one-day workshop that will be held on 1st September 2011 as a satellite event of Interspeech 2011 in Florence, Italy. Participants will be invited to submit abstracts or full papers for presentation at this event.
Thanks to Heidi Christensen, Ning Ma and Phil Green for providing input to this article. We would also like to acknowledge financial support from the PASCAL network and the EPSRC.
For more information, see:
Jon Barker is Senior Lecturer in the Department of Computer Science at the University of Sheffield. His research interests include machine listening and speech recognition in challenging acoustic environments. Email: j.barker@dcs.shef.ac.uk
Emmanuel Vincent is an Experienced Research Scientist at INRIA, Rennes, France. His research interests include bayesian modeling of audio signals and audio source separation. Email: emmanuel.vincent@inria.fr
SLTC Newsletter, November 2010
COLING 2010 was recently held on August 23-27, 2010 in Beijing China. The program contained tutorials, keynote speeches, oral and poster presentations of full papers (8 pages plus 1 for references) and short demonstration papers (4 pages including references), and workshops. There was a special panel session entitled as RING (RefreshINGenious Ideas) Session, where experts of the field led insightful discussions on three controversial topics. For a look at the conference program, please see the program .
Six tutorial sessions were held on August 22nd spanning conventional computational linguistic topics, neurolinguistics and design of natural language applications.
Three keynote speeches were given during the conference. Two of them are related to how human brain processes languages. The three keynote topics are listed as follows:
This year 339 full and 15 short demonstration papers were accepted for the conference. These papers were organized into the following session topics (The number in the brackets indicates the number of sessions for the corresponding topic.): Semantics (6), Translation (6), Sentiment (3), Information Extraction (3), Summarization (2), Information Retrieval (2), Parsing (2), Grammar and Parsing (2), Text Mining (2), Morphology (2), Natural Language Generation (1), Language Resources (2) Discourses (2), Multilingualism: Parallel and Comparable Corpora (1), Statistical and Machine Learning Models(1), Demo Sessions (3), Poster Sessions (6), and the Best Paper Finalists session.
Translation and Semantics were the two most popular topics. There are 6 oral sessions on Translation and 6 on Semantics. This was similar to previous Coling conferences. Sentiment analysis was emerging as a new research trend. There were 3 oral sessions and 1 poster session on sentiment analysis this year, which totals 12 oral papers and 9 poster papers, while there was only one oral paper on sentiment analysis on Coling 2008. Most research on sentiment analysis were conducted on online reviews and social media messages. The proposed approaches were based on machine learning. A few papers focused on exploring linguistic features for sentiment analysis.
There were 4 papers selected to be presented at the Best Paper Finalists session. The first one concerns Dialogue using POMDP, Controlling Listening-oriented Dialogue using Partially Observable Markov Decision Processes. The second one was a Translation paper titled as Nonparametric Word Segmentation for Machine Translation. The other two fell into the text understanding category: Recognition of Affect, Judgment and Appreciate in Text and Measuring the Non-compositionality of Multiword Expressions. Measuring the Non-compositionality of Multiword Expressions by Fan Bu, XIaoyuan Zhu and Ming Li won the best paper award.
Electronic versions of the papers from the main conference, short papers on demonstrations, papers from the Workshops, and Tutorial abstracts can be found at the ACL anthology .
Expert researchers from the Computation Linguistics led three inspiring discussions. For each topic, there are two or three speakers who presented their arguments either in favor or opposed to the statement. The three topics are as follow:
Nine workshops were held before, during and after the conference. The workshops are listed below:
COLING conference, organized by the International Committee on Computational Linguistics (ICCL), has a history that dates back to the mid-Sixties of the last century. The 1st conference was held in New York, 1965. Since then, the conference was held every two years. The previous four conferences were held in Taipei (Coling2002), Geneva (Coling2004), Sydney (Coling-ACL2006) and Manchester(Coling2008).
Junlan Feng is a Principal Member of Technical Staff at AT&T Labs Research. Her interests are natural language understanding, web mining, and speech processing. Email: junlan@research.att.com
SLTC Newsletter, November 2010
Marilyn Walker, one of the keynote speakers from SIGdial 2010, gave a talk on her recent work in dialogue system adaptation. We had a chance to interview Professor Walker about SpyFeet, a project exploring the impact of verbal and nonverbal behavior generation on interactive, outdoor role-playing games.
This year, Tokyo was host to the 11th Annual SIGdial Meeting on Discourse and Dialogue (SIGdial 2010). The conference had two very memorable keynotes. Dr. Hiroshi Ishiguro of Osaka University presented his work on developing androids for human-robot interaction. Dr. Marilyn Walker of the University of California, Santa Cruz gave a talk on her work on dialogue system adaptation. One of her current projects at UCSC, SpyFeet, is exploring the impact of verbal and nonverbal behavior generation on interactive, outdoor role-playing games. We had a chance to interview Walker about SpyFeet.
SpyFeet is a role-playing game where the player is part of a mystery story where they must explore the outdoors and interact with characters on a smartphone. The SpyFeet project's aim, Walker says, is to "explore how techniques for language generation and dialogue management in NLP can be incorporated into the narrative structures of games, providing novel approaches for game authoring that we hypothesize will eventually lead to more compelling and engaging games, appealing to a much wider segment of the population, and usable for a much wider range of purposes." Ultimately, the project should develop techniques that encourage people, particularly girls, to exercise more outdoors.
Developing language technologies for games is an emerging field of research given the potential impact on game design and human-computer interaction in general. With SpyFeet, Walker and her colleagues can explore the intersection of dialogue management, natural language generation (NLG), and game design, with the added benefit of understanding what motivates people to have fun outdoors. Players interact with the real world via augmented reality on a smartphone, in the context of the game - a mode of interaction that is rapidly growing with the pace of smartphones. Popular apps on many smartphones demonstrate the usefulness of augmented reality by integrating the phone's camera (which can overlay information to the user) and its GPS (which grounds the phone in a location).
"Because mystery stories naturally involve characters with wide ranging personalities and intentions," Walker says, "the mystery genre allows us to explore NLG techniques for characters with a wide range of dialogue styles, personalities, characterizations and intentions." She continues, "the complexity of mystery stories supports exploration of the narrative structures of the game and provides a challenging context for techniques for language generation and dialogue management."
UCSC researchers will design the game for the UCSC campus. "Players of Spy Feet will walk or cycle around the UCSC campus to investigate a mystery and find clues electronically placed at game locations on the campus," said Walker. "While playing the game, the user’s movements will be tracked with GPS, and GPS locations will be part of the logic controlling game play. Multiple players can play different roles simultaneously."
SLTC: What kind of evaluation do you have planned for the game? What are some objective analyses?
Marilyn Walker:
Of course we want to look at enjoyability and effect on motivation to exercise and self-efficacy for exercise. But we can just count steps. We would hope we could increase the number of daily steps to 12K regular daily steps.
SLTC: The idea of adjusting the personalities of characters in the game is very interesting - what are your plans for seeing what works best? Do you foresee some customization happening before starting the game with players?
MW:
Initially we just want to get the capability of having non player characters (NPCs) be able to have different personalities. The main focus of this project is not on adapting to the user, but rather to the quest structure and the context.
This project is in the early stages of development. We look forward to hearing more about this work in the near future!
SLTC Newsletter, November 2010
The 2010 NIST Speaker Recognition Evaluation or SRE10 (see SLTC Newsletter, July 2010) included a pilot test of human assisted speaker recognition (HASR). This test, which was open to sites whether or not they participated in the main evaluation of fully automatic systems, involved utilizing human expertise in combination with automatic algorithms on a limited set of trials chosen to be particularly challenging. In this evaluation, with specially chosen difficult trials, there was no evidence of human expertise contributing to system performance. But this was only a pilot test on limited numbers of trials, with little overall statistical significance. The possible contributions of human expertise on less challenging trials were not investigated.
The 2010 NIST Speaker Recognition Evaluation or SRE10 (see SLTC Newsletter, July 2010) included a pilot test of human assisted speaker recognition (HASR). This test, which was open to sites whether or not they participated in the main evaluation of fully automatic systems, involved utilizing human expertise in combination with automatic algorithms on a limited set of trials chosen to be particularly challenging.
Because of the sizable human effort necessary for participants to process trials within the evaluation timeframe, the number of trials had to be limited. Participants could choose between a 15 trial set (HASR1) and a 150 trial superset (HASR2). All HASR trials were also included in the main test of the SRE10 automatic system evaluation.
Participants were required to process the trials independently and in a fixed order. Each trial was composed of two English-language speech audio recordings, one an interview recorded over a microphone channel, and the other a phone conversation recorded over a telephone channel. For each trial, a participant was required to produce a decision (“true” or “false”) on whether the same speaker was present in both recordings and a confidence score (with higher scores indicating greater confidence that the speakers were the same).
In order to obtain informative evaluation results with a limited number of trials, a decision was made to seek out particularly difficult trials. A pre-pilot experiment was conducted on speech segments from an earlier evaluation to gauge how such trials might be selected. The trial selection process for HASR involved running an automatic system on the 2010 data, and then selecting the most difficult trials for this system. (We thank Howard Lei at the International Computer Science Institute for providing the system.) For the 15 HASR 1 trials, human listening was then applied to choose from within these the trials that appeared most challenging for humans. For HASR1, 6 of the 15 trials were target (same-speaker) trials and 9 were non-target (different speaker). For the 150 HASR2 trials, 51 were target and 99 non-target.
The HASR1 trials were completed by 20 systems from 15 different sites. Of these, 8 systems from 6 sites also completed the full set of HASR2 trials.
Most of these HASR sites also participated in the main SRE10 evaluation of automatic systems. The participants included academic, commercial, and government organizations from six nations.
Most systems combined human and automatic processing in some manner; a few utilized only human processing. Several participants otherwise involved in forensic work used one or several linguists or other experienced professionals in decision making; others utilized panels of up to 43 people with unspecified credentials, sometimes students, to make either collective or majority vote decisions. It should be noted that for many systems the humans involved were not native English speakers.
Automatic and human processing were combined in several different ways. Most systems used automatic pre-processing to clean up the signal and/or extract speech-rich segments; some included humans in this process. Some automatically estimated certain parameters, such as pitch or formant frequencies, and then relied on human judgements based on these. Others produced automatic system scores either for humans to consider in making final decisions or to be automatically fused with human scores. At least one system decided some trials fully automatically while relying on humans for others. Several systems utilized human confidence scores on a separate development set of trials to automate or partially automate confidence score generation on the HASR trials.
The selected trials proved to be very challenging overall. Indeed, for 5 of the 15 HASR1 trials the majority of the 20 systems had an incorrect decision. The cumulative system error rates for target and non-target trials are listed in Table 1. Note that the eight systems doing all trials had greater difficulty with the HASR1 trials, in particular the non-target ones, than with the remaining trials, as expected.
|
Table 1: Cumulative system percentage error rates on target and non-target trials |
||||
|
Trials |
15 HASR1 |
135 non-HASR1 |
||
|
Target |
Non-target |
Target |
Non-target |
|
|
8 doing all trials |
38 |
69 |
35 |
41 |
|
20 doing HASR1 trials only |
38 |
47 |
||
The HASR and automatic systems' decisions on the HASR trials may not be directly compared, because the automatic system decisions were based on a specified very small prior probability of a target trial. But these systems may be compared in terms of their possible decision operating points for target and non-target trial error rates based on thresholding the trial scores provided by each system. It turned out that for both the HASR1 and HASR2 trial sets the best automatic systems had operating points as good as or better than those of the HASR systems. Most of the HASR2 participating sites also submitted automatic system results, and each such site's automatic system had better performance curves than its HASR systems
Thus in this evaluation, with specially chosen difficult trials, there was no evidence of human expertise contributing to system performance. But this was only a pilot test on limited numbers of trials, with little overall statistical significance. The possible contributions of human expertise on less challenging trials were not investigated.
The SRE10 Workshop in Brno, Czech Republic in June included a session on HASR, where a number of the participants described their efforts. The immediately following Odyssey 2010 international workshop also had a number of papers on HASR and on other work involving people in the recognition process.
A special ICASSP session entitled “Investigations in Combining Human Expertise with Automatic Processing for Successful Speaker Recognition” will be held in Prague in May 2011. It will include papers on HASR and the HASR systems, as well as other efforts to include human expertise, including in forensic applications. One presentation will address using internet marketplaces such as Mechanical Turk to study the use of non-expert human effort to accomplish speaker recognition tasks.
Plans remain to be developed to include a follow-up to the HASR pilot test and other ongoing human-in-the-loop investigations in NIST evaluations in 2012 and beyond.
George Doddington and Jack Godfrey were major contributors to the HASR work.
More information on the HASR performance results and a list of participating sites is available at http://nist.gov/itl/iad/mig/hasr.cfm .
If you have comments, corrections, or additions to this article, please contact the authors: alvin.martin@nist, craig.greenberg@nist.gov
SLTC Newsletter
This article provides an overview and some useful links to the INTERSPEECH 2010 satellite workshop on Second Language Studies: Acquisition, Learning, Education and Technology (L2WS 2010). The aim of the workshop is for people working in speech science and engineering, linguistics, psychology, and language education to get together and discuss second language acquisition, learning, education, and technology.
The workshop was held on 22nd to 24th September, 2010 at the international conference hall in Waseda University, Tokyo, Japan. Four communities co-organized this workshop: AESOP, SLaTE, NICT, and LASS. In 2007 and 2009, ISCA workshops on Speech and Language Technology in Education (SLaTE) were held and these two workshops mainly focused on the use of speech and language technologies for education. The co-organization of L2WS 2010 stimulated non-technical researchers and the workshop received many papers from teachers and scientists as well as engineers. Also, L2WS 2010 accepted many proposals of demonstration systems. Finally, 43 papers (18 orals + 25 posters) of high scientific and/or technical quality were presented and 15 demonstration systems using state-of-the-art speech and language technology were displayed. 126 participants attended the workshop from all over the world.
In addition to paper presentation and demonstration system presentation, a special panel session was held on "Primary English Education in Asia". In 2011, English education will start in every public primary school in Japan. This is a drastic reform of the English education curriculum in Japan because English education started at middle schools before. Similar reforms were already carried out in China, Taiwan, and Korea. In the panel, invited educators from China, Taiwan, Korea, and Japan reported the current situation of primary English education, problems, and future directions. One day before L2WS 2010, an open symposium on Primary English Education in Asia was also held in Waseda University.
The Workshop was organised as follows:
Oral session-1 : Perception of a second language
Poster session-1 : Teaching and learning environment
Oral session-2 : Automatic pronunciation assessment
Oral session-3 : Production of a second language
Demo session-1 : New technologies and methodologies help language learning
Poster session-2 : Science and technology of speech and language for education
Special session : Primary English education in Asia
Oral session-4 : Prosodic training and corrective feedback
Demo session-2 : New technologies and methodologies help language learning
You can download all the papers presented at the workshop from
this site.
The call for papers for SLaTE 2011 has been already posted using Internet. The SLaTE 2011 workshop will be held in Venice, Italy. Check here for details of SLaTE 2011.
Nobuaki Minematsu is an Associate Professor at the Graduate School of Information Science and Technology, The University of Tokyo, Tokyo, Japan. Email: mine@gavo.t.u-tokyo.ac.jp.
SLTC Newsletter, November 2010
Sparse representations (SRs), including compressive sensing (CS), have gained popularity in the last few years as a technique used to reconstruct a signal from few training examples, a problem which arises in many machine learning applications. This reconstruction can be defined as adaptively finding a dictionary which best represents the signal on a per sample basis. This dictionary could include random projections, as is typically done for signal reconstruction, or actual training samples from the data, which is explored in many machine learning applications. SRs is a rapidly growing field with contributions in a variety of signal processing and machine learning conferences such as ICASSP, ICML and NIPS, and more recently in speech recognition. Recently, a special session on Sparse Representations took place at Interspeech 2010 in Makuhari, Japan from March 26-30, 2010. Below work from this special session is summarized in more detail.
Yang et al. present a method for image-based robust face recognition using sparse representations [1]. Most state-of-the art face recognition systems suffer from limited abilities to handle image nuisances such as illumination, facial disguise, and pose misalignment. Motivated by work in compressive sensing, the described method finds the sparsest linear combination of a query image using all prior training images, where the dominant sparse coefficients reveal the identity of the query image. In addition, extensions of applying sparse representations for face recognition also address a wide range of problems in the field of face recognition, such as dimensionality reduction, image corruption, and face alignment. The paper also provides useful guidelines to practitioners working in similar fields, such as speech recognition.
In Sainath et al. [2], the authors explore the use of exemplar-based sparse representations (SRs) to map test features into the linear span of training examples. Specifically, given a test vector y and a set of exemplars from the training set, which are put into a dictionary H, y is represented as a linear combination of training examples by solving y = H&beta subject to a spareness constraint on &beta . The feature H&beta can be thought of as mapping test sample y back into the linear span of training examples in H.
The authors show that the frame classification accuracy using SRs is higher than using a Gaussian Mixture Model (GMM), showing that not only do SRs move test features closer to training, but also move the features closer to the correct class. A Hidden Markov Model (HMM) is trained on these new SR features and evaluated in a speech recognition task. On the TIMIT corpus, applying the SR features on top of our best discriminatively trained system allows for a 0.7% absolute reduction in phonetic error rate (PER). Furthermore, on a large vocabulary 50 hour broadcast news task, a reduction in word error rate (WER) of 0.3% absolute, demonstrating the benefit of these SR features for large vocabulary.
Missing data techniques are used to estimate clean speech features from noisy environments by finding reliable information in the noisy speech signal. Decoding is then performed based on either the reliable information alone or using both reliable and unreliable information where unreliable parts of the signal are reconstructed using missing data imputation prior to decoding. Sparse imputation (SI) is an exemplar-based reconstruction method which is based on representing segments of the noisy speech signal as linear combinations of as few as possible clean speech example segments.
Decoding accuracy depends on several factors including the uncertainty in the speech segment. Gemmeke et al. propose various uncertainty measures to characterize the expected accuracy of a sparse imputation based missing data method [3]. In experiments on noisy large vocabulary speech data, using observation uncertainties derived from the proposed measures improved the speech recognition performance on features estimated with SI. Relative error reductions up to 15% compared to the baseline system using SI without uncertainties were achieved with the best measures.
Garimella et al. introduce a sparse auto-associative neural network (SAANN) in which the internal hidden layer output is forced to be sparse [4]. This is done by adding a sparse regularization term to the original reconstruction error cost function, and updating the parameters of the network to minimize the overall cost. The authors show the benefit of SAANN on the TIMIT phonetic recognition task. Specifically, a set of perceptual linear prediction (PLP) features are provided as input into the SAANN structure, and a set of sparse hidden layer outputs are produced and used as features. Experiments with the SAANN features on the TIMIT phoneme recognition system show a relative improvement in phoneme error rate of 5.1% over the baseline PLP features.
The ability to adapt language models to specific domains from large generic text corpora is of considerable interest to the language modeling community. One of the key challenges is to identify the text material relevant to a domain in the generic text collection. The text selection problem can be cast in a semi-supervised learning framework where the initial hypothesis from a speech recognition system is used to identify relevant training material. Sethy et al [5] present a novel sparse representation formulation which selects a sparse set of relevant sentences from the training data which match the test set distribution. In this formulation, the training sentences are treated as the columns of the sparse representation matrix and the n-gram counts as the rows. The target vector is the n-gram probability distribution for the test data. A sparse solution to this problem formulation identifies a few columns which can best represent the target test vector, thus identifying the relevant set of sentences from the training data. Rescoring results with the language model built from the data selected using the proposed method yields modest gains on the English broadcast news RT-04 task, reducing the word error rate from 14.6% to 14.4%.
Given the superior performance of SRs compared to other classifiers for both image classification and phonetic classification, Sainath et al. extends the use of SRs for text classification [6], a method which has thus far not been explored for this domain. Specifically, Sainath et al. show how SRs can be used for text classification and how their performance varies with the vocabulary size of the documents. The research finds that the SR method offers promising results over the Naive Bayes (NB) classifier, a standard baseline classifier used for text categorization, thus introducing an alternative class of methods for text categorization.
This article presented an overview about sparse representation research in the areas of face recognition, speech recognition, language modeling and text classification. For more information, please see:
[1] A. Yang, Z. Zhou, Y. Ma and S. Shankar Sastry, "Towards a robust face recognition system using compressive sensing", in Proc. Interspeech, September 2010.
[2] T. N. Sainath, B. Ramabhadran, D. Nahamoo, D. Kanevsky and A. Sethy, “ Exemplar-Based Sparse Representation Features for Speech Recognition ," in Proc. Interspeech, September 2010.
[3] J. F. Gemmeke, U. Remes and K. J. Palomäki, "Observation Uncertainty Measures for Sparse Imputation", in Proc.
Interspeech, September 2010.
[4] G.S.V.S. Sivaram, S. Ganapathy and H. Hermansky, "Sparse Auto-associative Neural Networks: Theory and Application to Speech Recognition", in Proc. Interspeech, September 2010.
[5] A. Sethy, T. N. Sainath, B. Ramabhadran and D. Kanevsky, “ Data Selection for Language Modeling Using Sparse Representations," in Proc. Interspeech, September 2010.
[6] T. N. Sainath, S. Maskey, D. Kanevsky, B. Ramabhadran, D. Nahamoo and J. Hirschberg, “ Sparse Representations for Text Categorization," in Proc. Interspeech, September 2010.
If you have comments, corrections, or additions to this article, please contact the author: Tara Sainath, tsainath [at] us [dot] ibm [dot] com.
Tara Sainath is a Research Staff Member at IBM T.J. Watson Research Center in New York. Her research interests are mainly in acoustic modeling. Email: tsainath@us.ibm.com
SLTC Newsletter, November 2010
Parallel corpora are widely used in Natural Language Processing. In particular, parallel multilingual corpora are used in machine translation, and parallel monolingual corpora are used for paraphrasing. We are introducing a new type of parallel corpus - a parallel corpus of dialogue and monologue. The dialogue part of the corpus consists of expository or information-delivering dialogues written by several acclaimed authors. The monologue part of the corpus has paraphrases of these dialogues in monologue form which were manually created.
The starting point is a collection of dialogues written by professional authors. These are manually "translated" to monologues. The monologues and dialogues are aligned and annotated. The dialogues are expository, i.e., information-delivering rather than dramatic. We chose four authors from 18th, 19th and 20th century literature, philosophy, and computer science: George Berkeley, Mark Twain, David Lewis, and Yuri Gurevich. Each of them wrote some of their work in the form of a dialogue. Our selection of authors and dialogues was guided by three principles:
The corpus was constructed by
Dialogues are segmented and annotated with dialogue acts. The dialogue act annotation includes three main types: Initiating (e.g. yes/no question, factoid question, clarification request), Responding (e.g. positive/negative answer, agreement, contradiction), and Explaining dialogue acts. The set of dialogue acts is based on the DAMSL [1] and Dialogue Games [2] annotation schemes. The monologue side is annotated with discourse structure based on RST theory [3,4]. The annotator (a researcher on the project) converted dialogue into monologue. Groups of one or more dialogue segments, e.g. a question followed by an answer or an explanation, are translated into declarative sentences. The annotator is instructed to keep the lexical and syntactic content of monologue translations as close as possible to the corresponding dialogue segments. The Figure below shows an example from the corpus, a monologue fragment that is aligned with a dialogue fragment, with dialogue act annotations for the dialogue side and discourse structure for the monologue side.
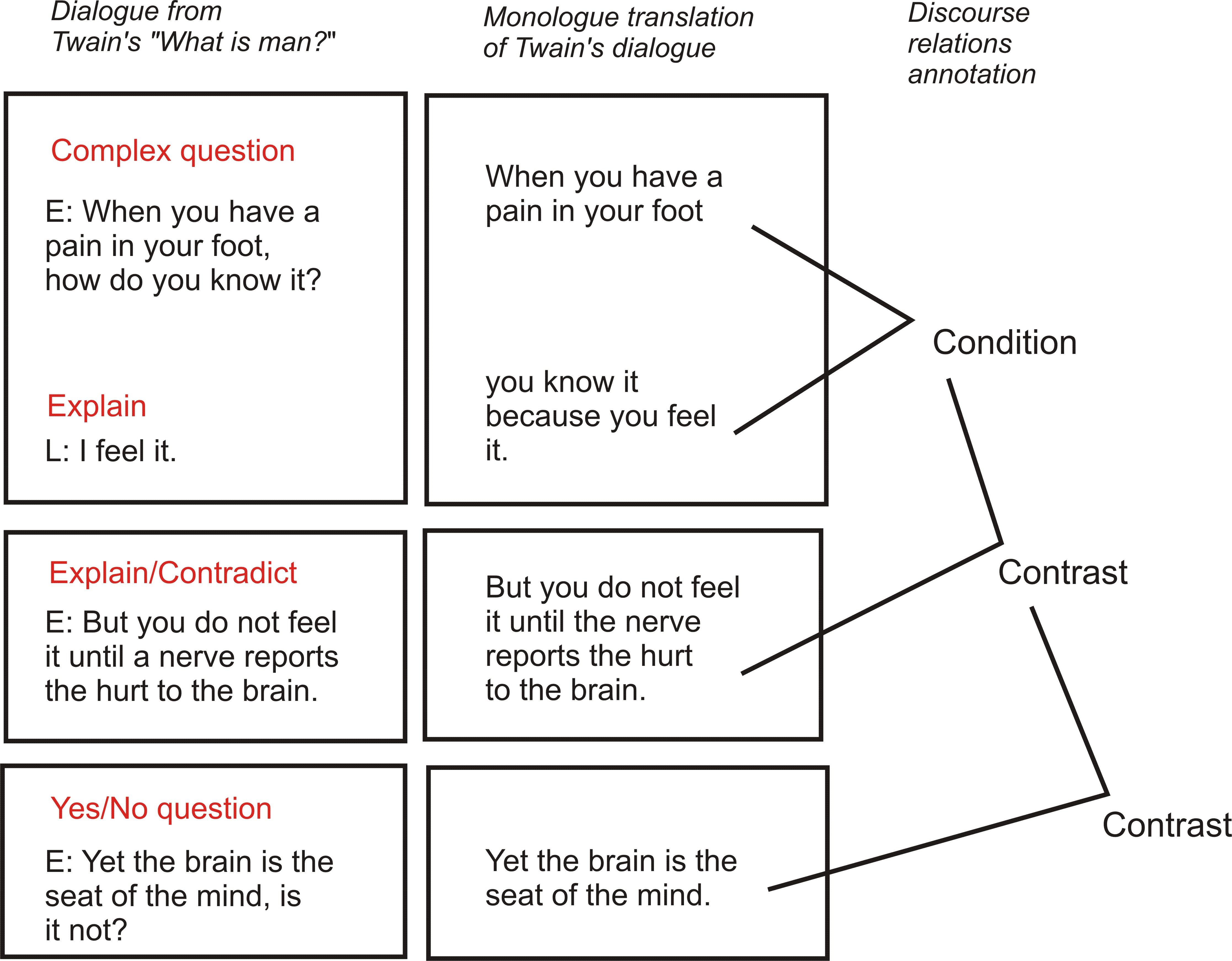
A more detailed description of the corpus construction and the annotation scheme can be found in [5].
T and S are having a conversation over lunch in a University cafeteria. Occasionally, they have to speak loudly so their conversation is not drowned out by the clatter of cutlery.
S: Why do you need a corpus of parallel dialogue and monologue?
T: In our CODA project -
S: CODA?
T: It stands for Coherent Dialogue Automatically generated from text.
S: Generating dialogue from text, why would you want to do that?
T: Research has shown that observing dialogue, rather than listening to a monologue can help students have a deeper understanding of a subject. It also causes them to ask more profound questions.
S: Sure, but how can you observe a generated dialogue?
T: The automatically generated dialogues can be animated into virtual character conversation like this one
S: Nice!
T: We hope that presenting information in videos can attract the viewer's attention and help them learn new information.
S: These movies must be difficult to make.
T: Not at all. Using the MPML3D scripting language and automatic gesture generation software the animated conversations can be created almost automatically.
S: So I can start with a text description and automatically convert it to a video presentation of a conversation between two virtual characters?
T: That's right!
S: Sounds great, but you still haven't explained why you need the corpus?
T: Good point. The parallel corpus is used as a resource for learning mappings from monologue to dialogue, similar to the use of parallel corpora in machine translation. We're building on the work by Piwek et al. [6] where the monologue-to-dialogue rules were handcrafted. By using the corpus to learn the mapping rules we hope to create a system that generates more diverse and engaging dialogues from text.
S: So the corpus was created with a very specific application in mind?
T: Yes, but we hope that it will prove to be useful for other purposes as well.
S: Such as?
T: Well, perhaps
The first release of the corpus contains 700 annotated and translated dialogue turns. It is available for free at http://computing.open.ac.uk/coda/data.html under a Creative Commons Attribution-NonCommercial-ShareAlike license.
Our recent publications on the CODA corpus and project are accessible at here.
If you have comments, corrections, or additions to this article, please contact the author: Svetlana Stoyanchev, s.stoyanchev [at] open [dot] ac [dot] uk.
References:
Svetlana Stoyanchev is Research Associate at the Open University. Her interests are in dialogue systems, natural language generation, discourse, and information presentation.
Paul Piwek is a lecturer in Computing at the Open University. He works in the areas of computational semantics and pragmatics, focusing on multimodal generation in dialogue.