
Welcome to the Fall 2013 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter! This issue of the newsletter includes 11 articles and announcements from 18 contributors, including our own staff reporters and editors. Thank you all for your contributions! This issue includes news about IEEE journals and recent workshops, SLTC call for nominations, and individual contributions.
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions.
To subscribe to the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Dilek
Hakkani-Tür, Editor-in-chief
William Campbell, Editor
Haizhou Li, Editor
Patrick Nguyen, Editor
A workshop on Deep Learning for Audio, Speech and Language Processing was held on June 16, 2013 in Atlanta, Georgia as part of the International Conference on Machine Learning (ICML) 2013.
Deep learning techniques have enjoyed enormous success in the speech and
language processing community over the past few years, beating previous state-of-the-art
approaches to acoustic modeling, language modeling, and natural language
processing. The focus of this workshop was on deep learning approaches to
problems in audio, speech, and language. A variety of talks and papers on new
models and learning algorithms that can address some of the challenges of these
tasks were presented.
On August 2nd 2013, IEEE and ACM announced that the IEEE Transactions on Audio, Speech, and Language Processing (TASLP) and the ACM Transactions on Speech and Language Processing (TSLP) will be published jointly as the IEEE/ACM Transactions on Audio, Speech, and Language Processing, starting January 2014. As the VP Publications of the IEEE Signal Processing Society and as the editors-in-chief of the two merging transactions, we are all delighted with the agreement that has led to these new, merged transactions.
Speech and language corpora are often created in an open-loop fashion, without continuous unit testing. This article describes a tool available on the SProSIG website that allows investigators creating small corpora to practice test-first corpus development, and to easily publish the result.
Have you ever felt impatient to see an idea published and archived? Perhaps, at the same time, you may have struggled with the decision of submitting that very paper to the Signal Processing Letters. The submission could have prevented you from sharing the ideas, live, in a ICASSP presentation for example, or in a thematic workshop.
Both of us, Dilek Z. Hakkani-Tür, as Senior Area Editor, and Anna Scaglione, as Editor in Chief of the Signal Processing Letters, thought of writing this short editorial to specifically target researchers in the areas of Speech and Language Processing to inform you about some significant changes the IEEE Signal Processing Letters has undergone, that can help prospective authors faced with this dilemma.
In May 2013, Proceedings of the IEEE published a Special Issue (Vol. 101, No. 5) which is dedicated to Speech Information Processing: Theory and Applications. The Special Issue includes 10 Invited Papers, contributed by an international cadre of 26 technical leaders in this field. The electronic version is now available at IEEE Xplore.
The NIST Open Keyword Search 2013 (OpenKWS13) Evaluation Workshop was the first in a series of community-wide evaluations to test research systems that search for keywords in audio of a "surprise" language whose identity is unveiled at the beginning of the evaluation period. OpenKWS13 made use of the surprise language data set developed for IARPA's Babel Program [1] that was made available to the wider research community. During the past 15 months, the four Babel teams were given four development language build packs to develop keyword search capabilities across languages. This was followed up by an evaluation on a surprise language that was held from March 25 to May 1, 2013; participants had four weeks to build their systems and one week to return keyword search results once the keywords were provided by NIST. While only the Babel teams worked with and were evaluated on the four development language packs, the Surprise Language Evaluation was open to the entire speech research community. The ultimate goal of the Babel program is to be able to rapidly develop keyword search spoken language technologies for ANY language, especially for under-resourced languages where linguistic resources such as word transcriptions are limited [1]. Currently, most spoken language technologies are only extensively investigated using a few resource-rich languages such as English. The Babel initiative is particularly meaningful given that there are over 7,000 languages in the world, of which over 300 have more than one million speakers.
Information and communication technologies for development (ICT4D for short) are software tools designed for societies in the developing world. A common feature of developing societies is the lack of a literate population, which can prevent people from taking full advantage of today’s modern technologies. Agha Ali Raza and his colleagues have developed a speech-based technology that has reached tens of thousands of people in the developing world.
SLTC Newsletter, August 2013
In this third newsletter of 2013, I would like to draw your attention to the upcoming election to renew our Speech and Language Technical Committee (SLTC). The SLTC represents all speech and language researchers in the IEEE Signal Processing Society (SPS). It supervises the review process for speech and language papers at our ICASSP meeting as well as for the ASRU and SLT workshops. The SLTC also gives advice on numerous issues that concern our research. In large measure, we are the main body that people may turn to for matters dealing with speech and language, especially in an engineering context. As such, it is important to maintain a solid representation of our community from academia and industry around the world.
In September each year, the SLTC is renewed by the election of 17-18 new members, for a 3-year term. (As the areas of speech and language constitute the largest single grouping in the SPS, the SLTC has the most members of any TC: 52 regular members and 2 officers.) If you know of someone you think would want to run for a position on the SLTC, or if you yourself would like to, please contact the SLTC Election subcommittee (Larry Heck, Hermann Ney, Fabrice Lefevre, Bhiksha Raj). (The email address is larry.heck@ieee.org.) Applying simply requires filling out a short form. Following the rules of SPS, the existing SLTC members (those not running themselves for re-election to a 2nd term) will vote to approve the new members from among the nominees. Anyone can nominate. Nominees must be current SPS members.
The major event of the last few months was surely ICASSP (the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing) in Vancouver, where we had a record attendance for ICASSP. It was held in the spacious and comfortable Convention Center, with a lovely view of the harbor and mountains. Right downtown and with numerous hotels nearby, this locale was superb. By all accounts, the meeting was a great success.
Of particular note were tutorials on Features for Robust Speech and Speaker Recognition, Speech Translation, and Graph-based Learning Algorithms for Speech & Spoken Language Processing.
Also of great interest was the special session on deep neural network learning for speech recognition and related applications. This topic was clearly popular among attendees, with the room being filled to overflow capacity. The ICASSP keynote talk also dealt with this new "hot topic."
Continuing the trend in recent years in our field, most work presented dealt with automatic analysis and recognition of speech and speakers. Dealing with speech distorted by reverberation and noise, whether for human listening or for automatic recognition, was also of great interest. Given the breadth and diversity of speech and language, there were many other related areas in which advances were noted at this year's ICASSP.
For next year's ICASSP (May 2014 in Florence, Italy), Special Session and Tutorial Proposals are due August 30th and Regular Papers due by October 27th. Our other meeting this year will be in December 2013 for the ASRU (IEEE Automatic Speech Recognition and Understanding) workshop in Olomouc, Czech Republic. As for 2014, the SLTC very recently decided to hold SLT-2014 (the IEEE Spoken Language Technology Workshop) in South Lake Tahoe, California on Dec. 6-9. Finally, it is not too soon to start thinking about where to hold ASRU-2015. If you have any interest in helping to organize this important meeting, let us know. The SLTC will consider bids early next year.
In closing, I hope you will consider submitting a nomination to join the SLTC this year, as well as participating at our meetings of ASRU-2013 and ICASSP-2014. We look forward to meeting friends and colleagues in beautiful Olomouc and Florence.
Best wishes,
Douglas O'Shaughnessy
Douglas O'Shaughnessy is the Chair of the Speech and Language Processing Technical Committee.
SLTC Newsletter, August 2013
The Member Election Subcommittee of the SLTC is seeking nominations for new SLTC Members. Nominations should be submitted to the Chair of the Member Election Subcommittee at larry.heck@ieee.org, with cc to ney@informatik.rwth-aachen.de, bhiksha@cs.cmu.edu, and Fabrice.Lefevre@univ-avignon.fr. Please provide the name, contact information and biography with the nomination.
New member candidates can be self-nominated or nominated by current SLTC members. Members will serve a term of three years. Past SLTC members are eligible to be nominated for a second term. Current SLTC members may also be nominated for a second consecutive term, but would then not be eligible to vote in this new member election. Additional terms are allowed after leaving the SLTC, but at least a 3-year gap in service is required.
New members must be willing to review papers that are submitted to the Society's conferences within the area of the SLTC, review papers for workshops owned or co-owned by the SLTC, serve in the subcommittees established by the SLTC, and perform other duties as assigned. SLTC members will be elected by the members of the SLTC itself based on the needs of the SLTC. The election results will be finalized by 15 November 2013.
Please use the nomination form outlined below and submit a completed nomination form no more than one page in length:
The rights and duties of an SLTC member are described here: http://www.signalprocessingsociety.org/technical-committees/list/sl-tc/
The following are nominee requirements:
The nomination deadline is set as 15 September 2013.
SLTC Newsletter, August 2013
The Member Election Subcommittee is seeking nominations from the SLTC members for the position of Vice Chair of the SLTC. Nominations should be submitted to the Chair of the Member Election Subcommittee at larry.heck@ieee.org, with cc to ney@informatik.rwth-aachen.de, bhiksha@cs.cmu.edu , and Fabrice.Lefevre@univ-avignon.fr.
Vice Chair candidates can be self-nominated or nominated by current SLTC members. Current SLTC members may also be nominated for Vice Chair. Interested candidates may run for both SLTC Vice Chair and a regular Member position and would choose one position if successful in both. The winner of the Vice Chair post will move up to the Chair post in 2015-16. Each nominee for Vice Chair must confirm in writing their willingness to serve and perform the duties described in the Society's Bylaws and Policies and Procedures if elected. Each nominee must also submit a one-page position statement and/or vitae.
The nomination deadline is set as 15 September 2013.
SLTC Newsletter, August 2013
A workshop on Deep Learning for Audio, Speech and Language Processing was held on June 16, 2013 in Atlanta, Georgia as part of the International Conference on Machine Learning (ICML) 2013.
Deep learning techniques have enjoyed enormous success in the speech and language processing community over the past few years, beating previous state-of-the-art approaches to acoustic modeling, language modeling, and natural language processing. The focus of this workshop was on deep learning approaches to problems in audio, speech, and language. A variety of talks and papers on new models and learning algorithms that can address some of the challenges of these tasks were presented.
First, Ivan Titov from Saarland University discussed work related to Inducing Cross-Lingual Semantic Representations of Words, Phrases, Sentences and Events. The main approach in this work is to regard a parallel corpus as a source of indirect supervision for learning, and to construct nonparametric Bayesian models that can exploit this supervision via mechanisms such as a disagreement penalty when learning semantic roles.
Second, Stephane Mallat from Ecole Polytechnique discussed work on Scattering Transforms. The talk proposes a methodology to reduce the variance in the signal representation by scattering data in high dimensional spaces using wavelet filters. Mallat shows that the proposed scattering coefficient methodology offers state of the art results on the TIMIT phonetic classification task.
Third, Tomas Mikolov from Google discussed some of the latest research in using Neural Networks for Language Modeling (LM). Mikolov showed that using Recurrent Neural Networks (RNNs) for LM produced state-of-the art results on both Wall Street Journal and English Broadcast News tasks compared to traditional, state-of-the-art LM techniques, including n-gram methods and Model M. In addition, Mikolov discussed using RNNs to obtain a distributed representation of words.
Fourth, James Martens from Toronto presented work on how depth in Neural Networks effects representational efficiency. The emphasis in this more theoretically oriented talk was on understanding what sort of functions neural networks can and cannot represent, and whether or not increasing depth expands the class of representable functions.
Fifth, Yann LeCun from NYU talked about Deep Convolutional Neural Networks. Convolutional neural networks are a biologically-inspired type of neural network that consists of multiple states of filter banks, non-linear operations, and spatial pooling operations, analogous to the simple cells and complex cells in the mammalian visual cortex. LeCun discusses various sparse coding techniques to pre-train CNNs, along with gradient-based supervised fine-tuning learning methods. CNNs have produced state of the art results across a variety of computer vision tasks.
Finally, Richard Socher from Stanford University discussed using Deep Learning techniques for Natural Language Processing (NLP) problems. Deep learning methods perform very well across various NLP tasks such as language modeling, POS tagging, named entity recognition, sentiment analysis and paraphrase detection, among others. In addition, deep learning methods for NLP do not require external hand-designed resources or time-intensive feature engineering.
In addition to the six invited talks, a poster session showcased work from 8 researchers across a variety of audio and NLP fields. Two spotlight talks from these 8 papers were selected as well.
Navdeep Jaitly, from the University of Toronto, presented one spotlight talk. Jaitly discussed a technique to augment speech datasets by transforming spectrograms, using a random linear warping along the frequency dimension. This is potentially more powerful than commonly used vocal tract length normalization (VTLN) techniques, as now warp factor is randomly generated for each training instance, rather than having one warp factor for training or test speaker. Results on TIMIT using the proposed method are promising using both DNNs and CNNs.
Mengqui Wang of Stanford University presented another spotlight talk. Wang talked about the Effect of Non-linear Deep Architecture in Sequence Labeling. Specifically, a comparison between Conditional Random Field (CRF) and neural network sequence models is performed. While CRF models use a linear architecture and discrete feature representation, neural network models use a non-linear architecture and a distributional representation. An empirical investigation between the two methods is done on two sequence labeling tasks. Results show that while a non-linear model are highly effective in low-dimensional distributional spaces, a non-linear architecture offers no benefits in a high-dimensional discrete feature space.
For more information regarding the talks and papers at the workshop, please visit the following website: http://sites.google.com/site/deeplearningicml2013/
If you have comments, corrections, or additions to this article, please contact Tara Sainath, tsainath [at] us [dot] ibm [dot] com.
Tara Sainath is a Research Staff Member at IBM T.J. Watson Research Center in New York. Her research interests include deep neural network acoustic modeling. Email: tsainath@us.ibm.com
Brian Kingsbury is a Research Staff Member at IBM T.J. Watson Research Center in New York. His research interests include deep neural network acoustic modeling, large-vocabulary speech transcription, and keyword search. He is currently co-PI and technical lead for IBM's efforts in the IARPA Babel program. Email: bedk@us.ibm.com
SLTC Newsletter, August 2013
On August 2nd 2013, IEEE and ACM announced that the IEEE Transactions on Audio, Speech, and Language Processing (TASLP) and the ACM Transactions on Speech and Language Processing (TSLP) will be published jointly as the IEEE/ACM Transactions on Audio, Speech, and Language Processing, starting January 2014. As the VP Publications of the IEEE Signal Processing Society and as the editors-in-chief of the two merging transactions, we are all delighted with the agreement that has led to these new, merged transactions.
IEEE's TASLP is a very well-established publication, strong in both quality and quantity. It is closely linked to ICASSP and to a number of workshops, such as ASRU and SLT. The language area is a more recent addition to TASLP, incorporated in 2006. ACM's TSLP is a more recent publication. The quality has been very high, but the quantity only sustains a quarterly publication. There is no ACM Special Interest Group (SIG) or conference connection in this area, so a sustained direct link to the research community has been more difficult.
A key motivation for the merger is that IEEE's TASLP does not yet have a strong profile in the language processing community, and this is reflected in the submissions received and the composition of the Editorial Board. ACM's TSLP has a stronger profile and Editorial Board membership in this area. Thus we believe that a joint transactions will be stronger than either publication on its own.
As part of the merger, we have taken the opportunity to restructure the editorial board. In addition to the role of Editor-in-Chief, there will be six Senior Area Editors to advise the Editor on the full range of topics covered by the journal. Li Deng will continue as Editor-in-Chief of the merged Transactions, and ACM TSLP editors Steve Renals and Marcello Federico will serve as Senior Area Editors, along with Hermann Ney, Haizhou Li, Sharon Gannot and George Tzanetakis.
Papers from the new Transactions will appear in both IEEE Xplore and the ACM Digital Library. Publication will be managed by IEEE as a hybrid journal, allowing either traditional or open access manuscript submission. The new journal welcomes novel contributions in all areas covered by the two journals, which includes audio, speech, and language processing and the sciences that support them. Later this month we shall announce an expanded editorial board to include representations from the ACM community, particularly in the area of language processing. We have also revised the EDICS of the joint transactions, notably with the expansion of the previous Spoken Language Processing category in the IEEE TASLP to the new category of Human Language Technology in the joint IEEE/ACM TASLP which covers both spoken and written language processing. For more information on paper submission, see http://www.signalprocessingsociety.org/publications/periodicals/taslp/.
SLTC Newsletter, August 2013
Speech and language corpora are often created in an open-loop fashion, without continuous unit testing. This article describes a tool available on the SProSIG website that allows investigators creating small corpora to practice test-first corpus development, and to easily publish the result.
Speech and language corpora are susceptible to error, just like any other technical product. In the LREC 2004 workshop on Speech Corpus Production and Validation, Florian Schiele recommended a three-step method for minimizing the number of errors in a speech corpus: those producing the corpus should first negotiate a Corpus Specification, then Pre-Validate the first small data subset to ensure it meets the specification, then finally submit the entire corpus for final Validation before distribution.
Software engineering has pioneered a method called test-driven development (TDD) that may be considered complementary to the specify/validate framework. In TDD, each coder first writes a unit test (a piece of code that tests the desired functionality), then writes code that satisfies the unit test. TDD is complementary to the specify/validate framework because the unit test is responsive to the state of the project on the date of its authorship, therefore a unit test is both more precise and more adaptive than an advance specification. TDD is not a replacement for the specify/validate framework; each unit test is written with reference to the overall project specification.
The SProSIG Corpus Tool implements a model of test-driven development for small speech corpora. In the jargon of the tool, a corpus consists of four types of objects: documentations, waveforms, lexicons, and annotations. Any user (after filling out a registration form) can create a corpus and upload an annotation. If he or she has not previously created a lexicon, then one is automatically created; if a waveform corresponding to the annotation is uploaded, then it may be linked to the annotation.
In the model implemented by the Corpus Tool, the lexicon is analogous to a unit test, and the annotation is analogous to the software being tested. A test failure is detected whenever the annotation contains a word not present in the lexicon. As in test-driven development, a failure does not necessarily mean that the annotation is at fault, but merely that the annotation and lexicon fail to coincide: the user is given the ability to either add the flagged word to the lexicon, or to revise the annotation. In case the correct decision is not obvious from the text of the annotation, a link is provided that lets the user listen to the corresponding segment of the waveform.
Current implementation of the Corpus Tool was publicly funded. Anybody can read public corpora; corpus creation is available for the use of any SProSIG member (SProSIG membership is free, and is available by self-nomination using a registration form on the SProSIG server). Any corpus can be defined to be publicly visible by its creator at any time, by checking the appropriate radio box. In making a corpus publicly available, the corpus owner must specify the copyright holders, and the license terms under which the corpus is released; available license terms include the six standard Creative Commons licenses.
Because the units of manipulation are individual waveform and annotation files, the tool is only well suited for the development and validation of relatively small corpora, e.g., a few dozen files. A small publicly visible sample corpus is available on the server, and the authors of the tool are currently using it to validate other small corpora that may be made publicly visible after validation.
Limitations of the current implementation include speed (waveforms are manipulated in ruby!), and a limited variety of supported file formats. At present, waveforms must be 16-bit WAV files, and annotations must be ELAN transcription files without a controlled vocabulary. Arabic text has been tested only using UTF-8 encoding.
Functionality similar to the Corpus Tool can be implemented directly in many transcription tools. In ELAN, for example, it is possible to limit the words used in any particular transcription tier to the items of a ``controlled vocabulary,'' and to expand that vocabulary during the annotation process as necessary. The unit testing philosophy of the Corpus Tool differs slightly from the philosophy of a controlled vocabulary. The Corpus Tool assumes that annotations are drawn from an effectively infinite vocabulary (effectively infinite: the Google N-Grams contain 13 billion distinct English words), but that both the producer and the consumer of a speech corpus are able to effortlessly notice entries in the lexicon that should be considered to be ``mistakes.'' In this respect the Corpus Tool is intermediate between the philosophy of controlled vocabulary specification, and that of corpus validation. One of the goals of the Corpus Tool's deployment is to promote discussion of the complementary merits of specification, unit testing, and final validation of speech and language corpora, even for small corpora.
The Corpus Tool was created using funds from the Qatar National Research Fund (QNRF). It is currently deployed on the server of the Speech Prosody Special Interest Group (SProSIG) of the International Speech Communication Association (ISCA). Bugs are the fault of the tool's authors, and not of QNRF or SProSIG.
Mark Hasegawa-Johnson is Professor of Electrical and Computer Engineering at the University of Illinois. His research interests include multimedia analytics, opportunistic sensing, signal understanding for social science research, multi-dialect and multilingual speech recognition and translation, articulatory features in automatic speech recognition, and multi-party spoken dialog systems. Email: jhasegaw@illinois.edu.
SLTC Newsletter, August 2013
Have you ever felt impatient to see an idea published and archived? Perhaps, at the same time, you may have struggled with the decision of submitting that very paper to the Signal Processing Letters. The submission could have prevented you from sharing the ideas, live, in a ICASSP presentation for example, or in a thematic workshop.
Both of us, Dilek Z. Hakkani-Tür, as Senior Area Editor, and Anna Scaglione, as Editor in Chief of the Signal Processing Letters, thought of writing this short editorial to specifically target researchers in the areas of Speech and Language Processing to inform you about some significant changes the IEEE Signal Processing Letters has undergone, that can help prospective authors faced with this dilemma.
Even if you never thought much of the Signal Processing Letters, and felt that the normal process was to go through a conference paper first and then flesh the content out in a long paper for a long journal article, we think you might reconsider your options in light of the new opportunities that publishing a letter can offer you.
Specifically, the changes are as follows:
It is impossible to say if these changes or other factors have had an impact already, but there are clear signs that SPL is sailing in the right direction. The impact factor is growing steadily and the journal submissions have grown significantly.
However, while the Speech and Language Processing community submits wonderful short papers for ICASSP, we have not seen a significant interest in SPL so far from this group. We hope that advertising these changes will influence prospective authors to submit their work to the Signal Processing Letters for consideration.
The papers can be published electronically much faster than with any other journal, without depriving the authors of the opportunity to share their new ideas to a live audience. Even if we are selective than most conferences, we feel this option opens a lot of opportunities for the authors.
Quoting the editorial [1], we ``really wish for the Signal Processing Letters to be what it was meant to be: the rapid vehicle for innovation in all the areas that fall under the wide umbrella of Signal Processing.''
Both of us hope that the Speech community will contribute more to elevate the level of the letters and we look forward to be handling your papers.
[1] Scaglione, A., "A letter or a conference paper? Conundrum resolved," Signal Processing Letters, IEEE , vol.19, no.6, pp.323,323, June 2012.
Dilek Hakkani-Tür is with Microsoft Research, CA, USA. Her research interests include spoken language processing.
Anna Scaglione is with the Department of Electrical and Computer Engineering, UC Davis, CA, USA.
SLTC Newsletter, August 2013
In May 2013, Proceedings of the IEEE published a Special Issue (Vol. 101, No. 5) which is dedicated to Speech Information Processing: Theory and Applications. The Special Issue includes 10 Invited Papers, contributed by an international cadre of 26 technical leaders in this field. The electronic version is now available at IEEE Xplore.
It has been 13 years since we saw the last special issue on speech processing in the Proceedings, which focused on the lower level, signal processing aspects. In this Special Issue, authors pay special attention to the recent progress on the higher level, information processing aspects.
In the past decade, we have seen tremendous progress in speech information processing technology that has helped people gain access to information (e.g., voice-automated call centers and voice search) and overcome information overload (e.g., spoken document retrieval, speech understanding and speech translation). The research has been spurred by initiatives such as international benchmarking and standardization, and by increasingly fast and affordable computing facilities. The scope of speech information processing has gone beyond the basic techniques such as speech recognition, synthesis and dialogue and has been extended to semantic understanding, translation and ranked information retrieval. The industry has made significant headway in speech technology adoption as well, leveraging the recent advances to address the real-world problems.
This Special Issue includes tutorial style articles that have the breadth and depth that graduate students, researchers, scientists and engineers need to understand the research problems and to implement the specific algorithms. The articles also provide intensive literature review and future perspectives on the important aspects of speech information processing. Next we catch a glimpse of the Special Issue.
This paper presents the theory and practice for methods of speech analysis, as used for automatic speech recognition.
This paper provides a tutorial overview of conditional random fields -a discriminative sequence model - and their applications in audio, speech, and language processing.
Analysis of data on human auditory processing suggests machine recognition paradigm, in which parallel processing streams interact to deal with unexpected input signals.
This paper presents an integrated detection and verification approach to information extraction from speech that can be used for speech analysis, and recognition of speech, speakers, and languages.
The authors present a statistical framework for the end-to-end system design where the interactions between automatic speech recognition and downstream text-based processing tasks are fully incorporated and design consistency established.
This paper provides an introductory tutorial on the fundamentals and the state-of-the-art solutions to automatic spoken language recognition, from both phonological and computational perspectives. It also gives a comprehensive review of current trends and future research directions.
This paper presents the theory and practice of belief tracking, policy optimization, parameter estimation, and fast learning.
The author takes a unique and unified perspective for key structure, learning, and decoding problems of statistical machine translation (SMT) models, noting connections and contrasts to automatic speech recognition (ASR), to help the understanding of SMT and catalyze tighter integration of ASR and SMT.
Computational techniques are presented to analyze and model expressed and perceived human behavior-variedly characterized as typical, atypical, distressed, and disordered-from speech and language cues and their applications in health, commerce, education, and beyond.
This paper gives a general overview of hidden Markov model (HMM)-based speech synthesis; it has great flexibility in changing speaker identities, emotions, and speaking styles.
Douglas O'Shaughnessy is the Chair of the Speech and Language Processing Technical Committee.
Li Deng is a Principal Researcher at Microsoft Research and Editor in Chief of IEEE Trans. Audio, Speech, and Language Processing.
Haizhou Li is the Head of the Department of Human Language Technology at Institute for Infocomm Research, Singapore. He is a Board Member of International Speech Communication Association.
SLTC Newsletter, August 2013
The NIST Open Keyword Search 2013 (OpenKWS13) Evaluation Workshop was the first in a series of community-wide evaluations to test research systems that search for keywords in audio of a "surprise" language whose identity is unveiled at the beginning of the evaluation period. OpenKWS13 made use of the surprise language data set developed for IARPA's Babel Program [1] that was made available to the wider research community. During the past 15 months, the four Babel teams were given four development language build packs to develop keyword search capabilities across languages. This was followed up by an evaluation on a surprise language that was held from March 25 to May 1, 2013; participants had four weeks to build their systems and one week to return keyword search results once the keywords were provided by NIST. While only the Babel teams worked with and were evaluated on the four development language packs, the Surprise Language Evaluation was open to the entire speech research community. The ultimate goal of the Babel program is to be able to rapidly develop keyword search spoken language technologies for ANY language, especially for under-resourced languages where linguistic resources such as word transcriptions are limited [1]. Currently, most spoken language technologies are only extensively investigated using a few resource-rich languages such as English. The Babel initiative is particularly meaningful given that there are over 7,000 languages in the world, of which over 300 have more than one million speakers.
The surprise language of OpenKWS13 is Vietnamese. Vietnamese is the language with the most speakers (~76million) in the Austroasiatic language family. Vietnamese is a challenging language - it is a monosyllable-based, tonal language, with regional dialects that might not always be mutually intelligible.
Participants of the OpenKWS13 Evaluation are given two language packs: (1) Full Language Pack (FullLP), consisting of 20 hours of word-transcribed scripted speech, 80 hours of word-transcribed conversational telephone speech, and a pronunciation lexicon; and (2) Limited Language Pack (LimitedLP), which consists of a 10-hour subset of FullLP plus the remaining audio without transcription. The contrast between the Full and Limited language pack conditions requires researchers to tackle out-of-vocabulary search terms and enables the exploration of unsupervised methods. There are three language resource (LR) conditions: (1) BaseLR: LRs limited to the supplied language pack, (2) BabelLR: LRs include non-test languages, Babel-supplied language packs, (3) OtherLR: LRs not mentioned in (1) and (2). In addition, there are two audio conditions: (1) No test audio reuse (NTAR), and (2) Test audio reuse (TAR). The contrast between TAR and NTAR is whether or not the keyword search system is allowed to reprocess the audio after obtaining the search keywords. In the NTAR condition, a system is constructed so that it processes the audio one time only without knowing all possible keywords that could be framed by future users; whereas, in the TAR condition, the audio can be reprocessed after the keywords are known to support keyword-specific indexing methods. Participants are encouraged to submit results for as many different conditions as possible, but the minimum submission requirement is FullLP+BaseLR+NTAR. In addition to this condition, the Babel teams are also required to submit results on the LimitedLP+BaseLR+NTAR condition to help investigate how much algorithmic advantage is achieved from the amount of transcribed data.
During the final week of the evaluation, the participants are given 75 hours of un-segmented conversational speech and a list of 4,065 keywords in orthographic format. Systems returned the time region of each detected keyword along with an estimate how likely the keyword was to occur and a detection decision.
There were 12 participating teams, four of which are members of the IARPA's Babel program (namely: BABELON, LORELEI, RADICAL, SWORDFISH). The remaining eight teams were from around the world including China, Israel, Singapore, and the USA. Participating teams were from both academia and industry. The organizers of the workshop expressed gratitude for the efforts of all the participating teams, including the 8 non-Babel teams, who participated as volunteers in the evaluation.
The OpenKWS13 results on the required submission of FullLP+BaseLR+NTAR are plotted in Fig. 1, which shows the detection error trade-off curves of the submitted keyword search (KWS) systems. Most participants used automatic speech recognition (ASR) as the backbone of the keyword search engine. Acoustic modeling was crucial in achieving superior ASR performance, as there is limited text data to train good language models. Most top performing teams incorporated deep neural networks to enhance their ASR capabilities. Robust acoustic features were also found to be helpful in obtaining good ASR and KWS results. Most top-performing teams integrated tonal features. In addition to traditional pitch features, the RADICAL team (led by CMU) also included other novel features such as fundamental frequency variation (FFV) spectrum [2, 3].
Misses are detrimental to KWS systems. This is especially true for languages like Vietnamese, where many words are only one syllable in length, and thus very short in duration. The LORELEI team (led by IBM) exploited cascaded search, which first searches the word index for a particular keyword, and continues to search the phonetic index if no result is returned in the first stage [4]. Score normalization was also shown to be crucial in improving performance and reducing the probability of missing rare search terms [5, 6]. The BABELON team (lead by BBN) showed that with proper score normalization, results can improve by 10% absolute or more. In addition, they showed that the effect of normalization is greater if applied earlier in the pipeline (e.g., before system combination.)
Many participants expressed interest in continuing related research inspired from the OpenKWS13 Evaluation. For example, the SINGA team (led by I2R) is extending their Vietnamese transliteration system to other under-resourced Southeast Asian languages to help resolve out-of-vocabulary issues; the STAR-SRI team (led by SRI) is exploring articulatory features derived from synthesized Vietnamese; and the Swordfish team (led by ICSI) is working on injecting higher-level linguistic structure into their KWS system.
Due to the success of this year's Open Keyword Search Evaluation, NIST is planning to continue organizing Open Keyword Search Evaluations to the public in the following years. Potentially interested participants are welcome to visit a href="http://www.nist.gov/itl/iad/mig/openkws13.cfm">http://www.nist.gov/itl/iad/mig/openkws13.cfm to familiarize themselves with this year's evaluation information and to join the mailing list by sending an email to openkws-poc@nist.gov.
Disclaimer: Certain commercial equipment, instruments, software, or materials are identified in this article in order to specify the experimental procedure adequately. Such identification is not intended to imply recommendation or endorsement by the (NIST), nor is it intended to imply that the equipment, instruments, software or materials are necessarily the best available for the purpose.
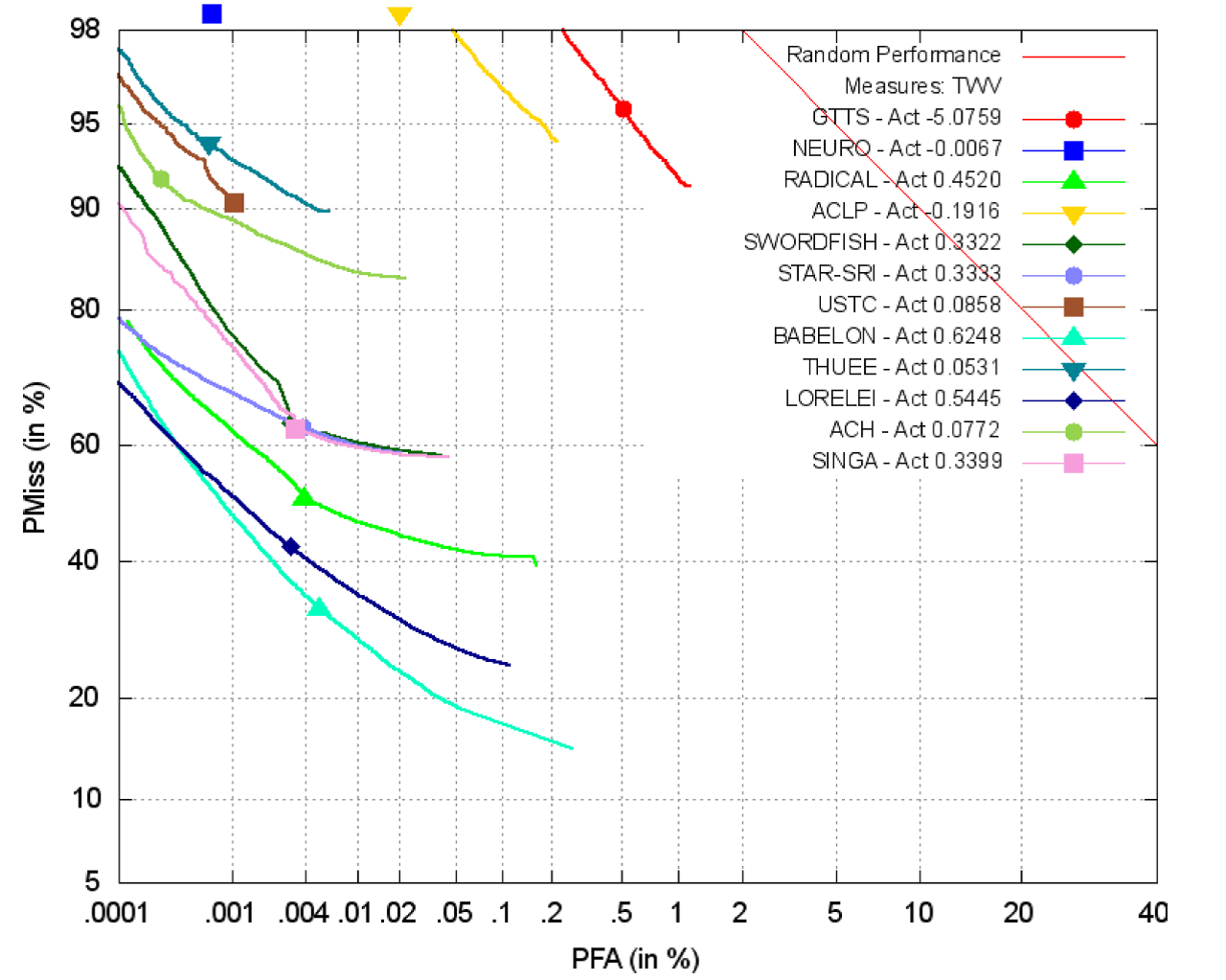
Fig. 1. Detection error trade-off curves of the 12 participating teams of OpenKWS13 Evaluation on the FullLP+BaseLR+NTAR condition.
[1] "IARPA broad agency announcement IARPA-BAA-11-02," 2011, https://www.fbo.gov/utils/view?id= ba991564e4d781d75fd7ed54c9933599.
[2] K. Laskowski, J. Edlund, and M. Heldner, "An Instantaneous Vector Representation of Delta Pitch for Speaker-Change Prediction in Conversational Dialogue Systems," Proceedings of ICASSP, 2008.
[3] K. Laskowski, J. Edlund, and M. Heldner, "Learning Prosodic Sequences Using the Fundamental Frequency Variation Spectrum", Proceedings of Speech Prosody, 2008.
[4] M. Saraclar and R. Sproat, "Lattice-Based Search for Spoken Utterance Retrieval", Proceedings of ACL, 2004.
[5] J. Mamou, et. al., "System Combination and Score Normalization for Spoken Term Detection," Proceedings of ICASSP, 2013.
[6] B. Zhang, R. Schwartz, S. Tsakalidis, L. Nguyen, and S. Matsoukas, "White listing and score normalization for keyword spotting of noisy speech," Proceedings of INTERSPEECH, 2012. Nancy F. Chen is a scientist at the Institute for Infocomm Research (I2R), Singapore. Her current research interests spoken language processing for under-resourced languages, speech summarization, and dialect/accent recognition. For more information: http://alum.mit.edu/www/nancychen. Jonathan Fiscus is a computer scientist at the National Institute of Standards and Technology. His research focuses on developing technology performance assessment methods for speech, text and video content extraction technologies. Email: jfiscus@nist.gov
SLTC Newsletter, August 2013
Information and communication technologies for development (ICT4D for short) are software tools designed for societies in the developing world. A common feature of developing societies is the lack of a literate population, which can prevent people from taking full advantage of today’s modern technologies. Agha Ali Raza and his colleagues have developed a speech-based technology that has reached over 165,000 people in the developing world.
Many disadvantaged users in developing countries have a low or non-existent level of literacy. There is a general fear that today’s technologies leave these users woefully behind, as many of them (for example, tablet computers and smartphones) assume the user can read. Enter the ICT4D community: a worldwide group of researchers focused on designing technologies specifically for societies in developing countries. Not only does this community need to consider problems like deployment in places with outdated infrastructures, they must also take into account the cultural and socioeconomic impact of the technologies they intend to deploy. How would a member of a developing country use the Internet, for example? Why would they use it? How can we make it easy to access if the user is illiterate?
A joint project between researchers at Carnegie Mellon University (CMU) in Pittsburgh, Pennsylvania, USA and at Lahore University of Management Services (LUMS) in Lahore, Pakistan aims to design information technology specifically for a developing society. They deployed a speech application, called "Polly", to Pakistan that allows users to access entertainment and information just by using voice over a simple (not smart) phone. Their work, recently published at the ACM SIGCHI Conference on Human Factors in Computing Systems (CHI), has received critical acclaim, including a Best Paper award at the conference [1]. SLTC interviewed two of the lead researchers on the project, Agha Ali Raza, a doctoral student in the Language Technologies Institute at CMU, and Roni Rosenfeld, a Professor in the School of Computer Science at CMU.
SLTC: Can you tell me about the goals of ICT4D (Information and Communication Technologies for Development? How does Polly relate to ICT4D?
The goal of ICT4D research is to find ways for Information and Communication Technology to aid socio-economic development around the world. Polly is designed to spread speech-based information access among low-literate mobile phone users. It employs simple entertainment to motivate its users to train themselves in the use of Interactive Voice Response (IVR) systems and viral spread to advertise these services.
SLTC: What is Polly and where does it operate?
Polly is a telephone-based speech service that allows its users to make a short recording of their voice; modify it using a variety of funny sound effects; and forward the resulting recording to friends. This simple voice game serves as a conduit for introducing more core development-related services to its users and for training them in the use of IVR systems. It has operated for over a year in Pakistan and has been recently deployed in India as well. In Pakistan it successfully spread the use of a job-audio-browsing service among some 165,000 users.
SLTC: How did you get Polly to go viral? After going viral, what were next steps for the project?
Polly provides attractive and simple-to-understand entertainment, for free. We believe that these factors played a pivotal role in its viral spread among our target audience, where there is a lot of pent up demand for entertainment. After going viral, our next steps were to advertise an audio-job-browsing service, and to test our users’ sensitivity to cellular charges (air-time credits).
SLTC: Who were your target users?
Low to middle socioeconomic status (SES) mobile phone users in Pakistan.
SLTC: Is Polly just an entertainment tool?
No, the entertainment part is used to help the service spread virally, and to train people in the use of IVR systems. The ultimate goal of Polly is to disseminate many different types of voice-based information services to users of mobile phones in poor countries around the world. Many such users are illiterate or low-literate, and voice-based communication in their preferred language over their simple mobile phones is our best hope of serving their information needs.
SLTC: Congratulations on the CHI Best Paper Award! What was the study you investigated in that work? How did you use Polly?
In the paper, we demonstrated a dramatic viral spread of Polly to some 165,000 people all over Pakistan (and even beyond). We also:
SLTC: What do you think CHI's recognition of your work means for the ICT4D Community? The Speech and Language Processing community?
It highlights the potential of virally spreading speech based information services, and their potential value to illiterate people throughout the world. It hopefully will attract others in the speech processing community to create many such services in diverse countries and a variety of languages. We will be very pleased to facilitate such efforts.
SLTC: How did you measure Polly's growth? Who was using it?
We measure Polly’s growth by the number of people who use it, the number of times they call it, and the number of times they accessed our information services (the job opportunities). Polly was used overwhelmingly by low- and mid-SES Pakistanis, most of them young men in their 20s and 30s.
SLTC: What were the greatest challenges?
Like most technology projects in developing countries, the greatest challenges were logistic in nature: e.g. procuring the 30 telephone lines and setting them up properly for smooth operation; dealing with infrastructure failures of various types, managing overloads on the system, etc.
SLTC: What did you find when Polly went "live" in Pakistan?
We found that it spread exceedingly fast, even faster than we had hoped for. We launched a pilot test in 2011 using a single phone line. That single line was overwhelmed within one week. So we shut it down, and re-launched in 2012 using a bank of 30 telephone lines. It took 10 days for these lines to saturate at full capacity. When two weeks later our telecom partner fixed a bug in their system, our capacity doubled overnight but was again saturated within days. It seemed there is tremendous pent-up demand in developing countries for these types of entertainment and information services.
SLTC: Were there any particularly useful lessons you learned from deploying a dialogue system in a developing nation?
Our two main lessons were:
SLTC: What kind of impact do you foresee this work having on the dialogue community? On developing countries?
We hope that our success will inspire many young researchers and developers in the dialog community to develop and deploy speech-based services for poor people throughout the world.
SLTC: Finally, where do you see this work headed? What services are next?
The biggest impact will be achieved when many developers try many types of information services in many countries and in many different languages. For now, we have been focusing on expanding the connection between entertainment, job opportunities, and job and skill training. We have been hard at work interfacing Polly to existing private and government-affiliated job services in Pakistan and India.
For more details, please visit: http://www.cs.cmu.edu/~Polly/
Thanks to Ali and Roni for their time! We look forward to seeing how their work continues to impact developing societies.
If you have comments, corrections, or additions to this article, please contact the author: Matthew Marge, mrma...@cs.cmu.edu.
Matthew Marge is a doctoral student in the Language Technologies Institute at Carnegie Mellon University. His interests are spoken dialogue systems, human-robot interaction, and crowdsourcing for natural language research.
SLTC Newsletter, August 2013
2014 IEEE Spoken Language Technology Workshop (SLT 2014) will be held at South Lake Tahoe Resort Hotel in South Lake Tahoe, California, on Dec 6-9, 2014. We expect the time and location to attract participants in academia and industry from different countries. The main theme of the workshop will be “machine learning in spoken language technologies”. Also in SLT 2014, one of the goals is to increase both intra and inter community interaction. For inter community interaction, one of our target communities is NIPS, from which we plan to invite keynote/guest speakers towards this goal. Towards the goal of increased “intra-community interaction”, panel discussions will be initiated online before/during the conference to capture attendees’ interests/questions/comments, and this will make panel discussions more effective. Towards the same goal, in addition, we plan to organize miniSIGs (mini special interest groups) which will be small discussion groups to get organized before & after the panel discussions or as independent SIG meetings. This will allow SLT attendees to organize themselves in smaller groups and have more involved discussions. After the workshop, we plan to collect and publish (online) summary reports from panel discussions as well as from miniSIGs. There will be also highlight sessions where 3-5 best papers will be presented in an oral format to highlight and bring to the communities attention, as well as provide broader feedback and discussion regarding their impact. Following tradition from the last two SLT workshops in 2010 (Berkeley, CA) and 2012 (Miami, FL), we are looking forward to hosting challenges and themed sessions. Stay tuned for more information!.
