Speech and Language Processing Technical Committee Newsletter
November 2012
Welcome to the Winter 2012 edition of the IEEE Speech and Language
Processing Technical Committee's Newsletter! In this issue we are
focusing on news from recent conferences (such as MLSLP and SANE) and
workshops (such as Telluride and NIST TRECVID). This issue of the
newsletter includes 9 articles from 9 guest contributors, and our
own staff reporters and editors. Thank you all for your contributions!
We believe the newsletter is an ideal forum for updates, reports,
announcements and editorials which don't fit well with traditional
journals. We welcome your contributions, as well as calls for papers,
job announcements, comments and suggestions. You can submit job
postings here, and reach us at speechnewseds [at] listserv (dot) ieee
[dot] org.
We'd like to recruit more reporters: if you are still a
PhD student or graduated recently and interested in contributing to
our newsletter, please email us (speechnewseds [at] listserv (dot)
ieee [dot] org) with applications. The workload includes helping with
the reviews of submissions and writing occasional reports for the
Newsletter. Finally, to subscribe to the Newsletter, send an email
with the command "subscribe speechnewsdist" in the message body to
listserv [at] listserv (dot) ieee [dot] org.
Dilek
Hakkani-Tür, Editor-in-chief William Campbell, Editor
Patrick Nguyen, Editor Martin Russell, Editor
From the SLTC and IEEE
From the IEEE SLTC chair
John Hansen
Speech and Language Processing for Educational Applications
Klaus Zechner
This article provides a brief overview of the history, current state-of-the-art, and anticipated future trends in the areas of speech and language technology for educational applications. It also provides some examples of seminal applications in the field.
MLSLP 2012 brings together speech, natural language processing, and machine learning researchers
Karen Livescu
The 2nd Symposium on Machine Learning in Speech and Language
Processing (MLSLP) was recently held as a satellite workshop of
Interspeech 2012 in Portland on September 14.
Increasing
Popularity of Speech and Audio Event Recognition in Unconstrained Multimedia
Data
Case Study: NIST TRECVID Multimedia Event Detection Evaluations
Murat Akbacak
Due to the popularity of online user-submitted videos, multimedia content analysis and event modeling for the purposes of event detection and retrieval is getting more and more attention from the speech and audio processing communities. As the amount of online multimedia data is increasing every day, and the users' search needs are changing from simple content search (e.g., find me today's Giants videos) to more sophisticated searches (e.g., find me this week's Giants home-run video snippets), speech and audio components are becoming more important as they convey complimentary and richer information to image/video content. In this article, we will talk about the increasing popularity of speech recognition and audio event recognition technologies for multimedia content analysis. We will also present the challenges as well as the ongoing research efforts in these two fields by using Multimedia Event Detection (MED) track of NIST TRECVID evaluations as our case study.
A Glimpse of IEEE SLT 2012
Ruhi Sarikaya and Yang Liu
The fourth biannual IEEE SLT workshop will be in Miami, Dec 2-5, 2012. Full preparation for the workshop is currently underway, and the conference program has been finalized. The accepted papers cover a wide range of topics in spoken language technology, ranging from speech recognition to various language understanding applications.
Pay Attention, Please:
Attention at the Telluride Neuromorphic Cognition Workshop
Malcolm Slaney
The role of attention is growing in importance as speech recognition moves into more challenging environments. This article briefly describes recent projects on attention at the Telluride Neuromorphic Cognition Workshop. These projects have studied different parts of attention in a short, focused, working workshop, using EEG signals to "listen" to a subject's brain and decode which of two speech signals s/he was attending.
The 10th Information Technology Society Conference on Speech Communication
David Suendermann
This article provides a short review of the 10th Information Technology Society Conference on Speech Communication held in Braunschweig, Germany, September 26 to 28. Organized by a primarily German scientific committee, the conference has grown very selective with a good number of major contributors in the field (e.g. the keynote speaker Steve Young and at least five more SLTC members involved as organizers, chairs, etc.). Sessions spanned a wide range of domains such as Spoken Language Processing, Speech Information Retrieval, Robust Speech Recognition, or Automotive Speech Applications, and were hosted at the Braunschweig University of Technology, well-known for Carl Friedrich Gauss, former professor at this university.
SANE Conference Overview
Tara N. Sainath
The Speech and Audio in the Northeast (SANE) Conference was held on October 24, 2012 at Mitsubishi Electric Research Laboratories (MERL) in Cambridge, MA. The goal of this meeting was to gather researchers and students in speech and audio from the northeast American continent.
Unfamiliar applications of some familiar techniques
Martin Russell, Chris Baber, Manish Parekh and Emilie Jean-Baptiste
This article considers applications in other domains, of techniques that are familiar in the context of speech and language processing. The focus is the EU CogWatch project, although there are many other examples. Do technique such as hidden Markov models (HMMs) lend themselves naturally to these new domains, or is it just an instance of Maslow's hammer, or perhaps (apologies to Maslow) a variant that should be referred to as Maslow's HMMer - "I suppose it is tempting, if the only tool you have is a HMM, to treat everything as if it were speech recognition"? This article briefly explores this issue and argues that this is not the case, that these methods are appropriate because of the nature of the problems, that these new applications can benefit from the experience and investment of the speech and language research community, and that, conversely, challenges in these new areas might give new insights into difficult speech and language processing problems.
Grounding and Levels of Understanding in Human-Computer Dialogue
Matthew Marge
Spoken dialogue system researchers have adopted theoretical models of human
conversation; this article describes one theory of human-human communication
and its adaptation to human-computer communication.
From the SLTC Chair
John H.L Hansen
SLTC Newsletter, November 2012
Welcome to the last installment of the SLTC Newsletter for 2012. The next IEEE ICASSP conference is approaching, with due dates for papers now set for Nov. 30th (see this link: http://www.icassp2013.com/). This promises to be a very engaging ICASSP meeting, especially for researchers, students, and engineers/scientists in the speech and language processing domain. The country of Canada has a rich diversity of indigenous/Inuit languages, with over 30 languages, especially in the pacific northwest of Canada, spoken by native peoples, while English and French are the first languages of 58% and 23% of Canadians respectfully.
Canadian federal law requires all government services to be bilingual. Also, while all government proceedings are in English and French, all proceedings are also simultaneously translated into a number of the native Inuit languages as well. I hope you consider submitting a paper to ICASSP-2013 (Due Date is Nov. 30, 2012), and/or consider attending this conference which promises to be as technically enriching as past ICASSP meetings.
ICASSP-2013 5-Page Format
Another aspect which I would like to raise in this installment is the notion of citations and connecting ones research contributions to past work. The organizers of this upcoming IEEE ICASSP-2013 have proposed and are experimenting with a new 5 page format for the conference papers. Since the first ICASSP conference in 1976 in Philadelphia (40 years ago!), the paper format has always been a four page format. For those of you who are old enough to remember some of the earlier ICASSPs (a summary of which is included below), we submitted extended abstracts with initial results, and TCs met at IEEE Headquarters in New Jersey to make decisions after an initial review process.
If accepted, authors were sent large paper mattes which were used to lay out the text and figures of your paper (something like what is shown above). The notion of planning the space "real-estate" planning for your paper was a core task! Authors would be required to print out hard copies of their text, which were then pasted onto the paper mattes, and when completed mailed to IEEE where photo offsets were produced for the final hard copy proceedings.
As such, there has been a strong history and motivation to not expand from this 4 page option, primarily because of the known number of papers and available page count for printing the proceedings. However, with advancements in page layout and electronic media and dissemination, the motivation for maintaining the 4 page format is being questioned.
A sample of ICASSP Conference Logos over the years!
One overriding reason for this is a slow and steady decline in referencing past work. The IEEE Signal Processing Society has made a consorted effort to transition past journal papers into electronic format, however the quality of some of these are not at the level currently seen in today's digital media. For whatever reason, there is a growing trend in ICASSP papers for authors to sacrifice reference/citation space in order to include more technical content including figures/results. A probe study by IEEE ICASSP-2013 organizers showed a reduction in ICASSP paper citations over the past few years, with a total of 11020 citations in 2006 (resulting in 5.8 citations per paper), to 7664 citations in 2008 (resulting in 4.0 citations per paper). So, the new format allows for only references to appear on the fifth page, and in theory allow authors to emphasize and connect their research contributions more clearly with past research publications. On behalf of the SLTC, we feel that authors should maybe focus on better space management to include the references necessary to project their contribution within the context of the past research field. However, adding this fifth page does in fact encourage and remove any excuse for not including a fair and balanced set of references to the proposed research contributions contained in the manuscript, and the SLTC membership welcomes this opportunity to see if the resulting papers will be stronger because of this change!
SLTC 2013 New Members
Next, the SLTC recently completed the election process of new SLTC members. We had 55 nominations for 17 positions, and we wish to thank all those who were nominated and participated in the election process. I would therefore like to welcome the following newly elected members for 2013:
Satoshi Nakamura (Nara Institute of Science and Technology, Japan)
Alexandros Potamianos (Technical University of Crete)
Haizhou Li (Institute for Infocomm Research, Singapore)
Najim Dehak (MIT Computer Science and Artificial Intelligence Lab, USA)
Pedro A. Torres-Carrasquillo (MIT Lincoln Laboratory, USA)
Kay Berkling (Baden-Wuerttemberg Cooperative State University, Germany)
Björn Schuller (Technische Universität München, Germany)
Tom Bäckström (International Audio Labs Erlangen, Fraunhofer IIS, Germany)
Israel Cohen (Technion - Israel Institute of Technology, Israel)
Malcolm Slaney (Microsoft Research, USA)
Takayuki Arai (Sophia University, Japan)
Dong Yu (Microsoft Research, USA)
Mike Seltzer (Microsoft Research, USA)
Bhuvana Ramabhadran (IBM T.J. Watson Center, USA)
Ananth Sankar (Cisco, USA)
Michiel Bacchiani (Google, USA)
Junichi Yamagishi (CSTR, University of Edinburgh, Scotland)
SLTC 2012 Retiring Members
The SLTC is a completely voluntary committee which makes advancements and oversees the review process of approximately 700 ICASSP papers each year. The extensive work done by SLTC is intended to reflect and represent the IEEE Signal Processing Society membership with interests in the speech and language processing disciplines. Without the tireless efforts of many of these volunteers, it would not be possible to effectively represent the wishes of the IEEE SPS members. As such, I wish to extend a sincere thanks to the following members who are completing their three-year term in the SLTC and will retire Dec. 31, 2012 (but will still be part of one last ICASSP review process!).
David Suendermann (SpeechCycle Inc, USA)
Olivier Pietquin (Supelec, France)
Junlan Feng (AT&T Research, USA)
Carol Espy-Wilson (Univ. Maryland, USA)
Douglas Reynolds (MIT Lincoln Labs, USA)
Seiichi Nakagawa (Toyohashi University of Technology, Japan)
Tom Quatieri (MIT Lincoln Labs, USA)
Bastiaan Kleijn (KTH, Sweden)
Les Atlas (Univ. Washington, USA)
Takayuki Arai (Sophia University, Japan)
Olov Engwall (KTH, Sweden)
Bhuvana Ramabhadran (IBM T. J. Watson Research Center, USA)
Dirk Van Compernolle (K. Univ. Leuven, Belgium)
Hong-Kwang Jeff Kuo (IBM T. J. Watson Research Center, USA)
Kate Knill (Toshiba Cambridge, UK)
Martin Russell (Univ. Birmingham, UK)
Simon King (Univ. Edinburgh, UK)
Many thanks for your dedication and support of the SLTC over these past three years!
Finally, as SLTC Chair, this will be my last "Note from the Chair" in our SLTC Newsletter. I will be stepping down and serve as "Past Chair" in 2013. I will therefore welcome Douglas O'Shaughnessy, who has served as Vice-Chair and will become TC Chair in January 2013. Doug has been an outstanding colleague and gives extensively of his time and advice for the SLTC, and I know he will serve in an exemplary manner as TC Chair!
I look forward to seeing you all in Vancouver, Canada for the next IEEE ICASSP-2013 conference! Best wishes…
John H.L. Hansen
November 2012
John H.L. Hansen is SLTC Chair (Speech and Language Processing Technical Committee).
Summary of ICASSP Conferences (thanks to [1])
ICASSP 2013, Vancouver, British Columbia, Canada, March 26-31, 2013 (www)
ICASSP 2012, Kyoto, Japan, March 25-30, 2012 (www)
ICASSP 2011, Prague, Czech, May 22-27, 2011, 2011 (www)
ICASSP 2010, Dallas, Texas, USA, March 15-19, 2010 (www)
ICASSP 2009, Taipei, Taiwan, April 19-24, 2009 (www)
ICASSP 2008, Las Vegas, Nevada, USA, March 30 - April 4, 2008 (www)
ICASSP 2007, Honolulu, Hawaii, USA, April 15-20, 2007 (www)
ICASSP 2006, Toulouse, France, May 14-19, 2006 (www)
ICASSP 2005, Philadelphia, Pennsylvania, USA, March 18-23, 2005 (www)
ICASSP 2004, Montreal, Quebec, Canada, May 17-21, 2004
ICASSP 2003, Hong Kong, Hong Kong, April 6-10, 2003 (www)
ICASSP 2002, Orlando, Florida, USA, May 13-17, 2002
ICASSP 2001, Salt Lake City, Utah, USA, May 7-11, 2001
ICASSP 2000, Istanbul, Turkey, June 05-09, 2000 (www)
ICASSP 1999, Phoenix, Arizona, USA, March 14-18, 1999 (www)
ICASSP 1998, Seattle, Washington, USA, May 12-15, 1998
ICASSP 1997, Munich, Bavaria, Germany, April 21-24, 1997
ICASSP 1996, Atlanta, Georgia, USA, May 07-10, 1996
ICASSP 1995, Detroit, Michigan, USA, May 08-12, 1995
ICASSP 1994, Adelaide, South Australia, Australia, April 19-22, 1994
ICASSP 1993, Minneapolis, Minnesota, USA, April 27-30, 1993
ICASSP 1992, San Francisco, California, USA, March 23-26, 1992
ICASSP 1991, Toronto, Ontario, Canada, May 14-17, 1991
ICASSP 1990, Albuquerque, New Mexico, USA, April 03-06, 1990
ICASSP 1989, Glasgow, Scotland, May 22-25, 1989
ICASSP 1988, New York, New York, USA, April 11-14, 1988
ICASSP 1987, Dallas, Texas, USA, April 06-09, 1987
ICASSP 1986, Tokyo, Japan, April 08-11, 1986
ICASSP 1985, Tampa, Florida, USA, March 26-29, 1985
ICASSP 1984, San Diego, California, USA, March 19-21, 1984
ICASSP 1983, Boston, Massachusetts, USA, April 14-16, 1983
ICASSP 1982, Paris, France, May 03-05, 1982
ICASSP 1981, Atlanta, Georgia, USA, March 30 - April 01, 1981
ICASSP 1980, Denver, Colorado, USA, April 09-11, 1980
ICASSP 1979, Washington, District of Columbia, USA, April 02-04, 1979
ICASSP 1978, Tulsa, Oklahoma, USA, April 10-12, 1978
ICASSP 1977, Hartford, Connecticut, USA, May 9-11, 1977
ICASSP 1976, Philadelphia, Pennsylvania, USA, April 12-14, 1976
Speech and Language Processing for Educational Applications
Klaus Zechner
SLTC Newsletter, November 2012
This article provides a brief overview of the history, current state-of-the-art, and anticipated future trends in the areas of speech and language technology for educational applications. It also provides some examples of seminal applications in the field.
History and current state-of-the-art
Since their early days in the 1960s, computers have been used for a variety of educational applications, including to support language learning and literacy development. Speech and language processing technologies came into play much later in the 1990s, when both ASR (Automated Speech Recognition) and NLP (Natural Language Processing) had sufficiently matured as scientific disciplines to be utilized for solving practical problems in the educational domain, and when desktop and multimedia computers became available to a broad population.
One example of such an early application is Project LISTEN at Carnegie Mellon University (Project LISTEN home page), which is still being actively developed, improved and evaluated after some 20 years. LISTEN is a reading tutor that uses ASR technology to follow a student's oral reading along a text passage displayed on the screen, and which detects a variety of errors and provides different kinds of feedback to the student. Its effectiveness in improving children's reading skills has been demonstrated in several studies (Project LISTEN Research Basis).
In the late 1990s, workshops focusing on speech and language technology for language learning were held (e.g., "Integrating Speech Technology in Language Learning" (InSTiLL)). In 2006 the International Speech Communication Association (ISCA) founded a Special Interest Group on Speech and Language Technologies in Education (SLaTE), which has held four meetings so far (2007, 2009, 2010 and 2011), with the next meeting to be held in Grenoble, France, adjacent to InterSpeech 2013 (SLaTE 2013 home page).
A closer look at the 50-some papers, posters and demonstrations presented at the most recent SLaTE conference of 2011 provides a good overview of the current state of this field and its major active areas of research. With 17.5%, papers on games for language learning were in strong focus, indicating one of the more recent trends in the field. Two other very active areas are, with 13.2% of papers each, tutoring and dialogue systems, and approaches for generating learner materials and corpora exploitation for language learning. The more traditional areas of pronunciation training and prosodic analysis each also had similar weights at this SLaTE conference, while ASR and synthesis, as well as scoring and error detection in text were the smallest classes of presented papers. Finally, 17.5% of papers had a more generic computer-assisted language learning (CALL) focus (see, e.g., Hubbard (2009) for a collection of seminal articles on CALL). A recent overview article on spoken language technology in education, based on contributions to the first SLaTE conference in 2007, can be found in (Eskenazi, 2009).
It is interesting to observe that only a small number of publications fall outside the domains of computer-assisted language learning and literacy development both in SLaTE, as well as in other related venues, such as the North American Association for Computational Linguistics (NAACL) workshop series "Innovative Use of Natural Language Processing for Building Educational Applications" (BEA 2012 workshop home page). The main reason may be related to the fact that the most obvious use of both ASR and NLP technology seems to be in support of language learners and language learning systems, but another reason may also be just the historic development of the field.
Some notable exceptions are intelligent tutoring and dialog systems that are not aimed at language learners but rather at students of other disciplines, mostly the sciences. Two recent examples of large systems that have received widespread attention in the community are the Rimac tutoring system for physics, developed at the University of Pittsburgh (Katz et al., 2011), and the ARIES trialog system for developing reasoning skills in the social and physical sciences, developed at the university of Memphis (ARIES home page). In both systems, speech and/or language technologies are used for many different aspects of these intelligent learning agents. One common feature of most speech and language processing based systems for educational applications is that they try to identify certain errors or error patterns of the system user, in most cases, the language learner. Because of this, an obvious application of these technologies is systems that automatically score written and spoken responses. In the written domain, the automated scoring of essays has a long tradition, with e-rater® (Attali and Burstein, 2006) and IntelligentEssayAssessor™ (Foltz et al., 1999) being two widely known and used examples. As for speech, two highly developed automated scoring systems are Versant™ (Bernstein and Cheng, 2007) and SpeechRaterSM (Zechner et al., 2009).
Challenges and outlook
For the most part, speech and language technologies in education have been used in the domains of computer-assisted language learning, literacy development. as well as in tutoring and dialogue systems geared towards learning in different science domains. As for language learning, the major focus has been on "low-level" aspects of language, i.e., fluency, pronunciation and prosody for spoken language, and orthography, grammar and style for written language. One large area of research is still to improve the automated understanding of both spoken and written language in terms of its intended meaning, while not being restricted to a limited context, such as in most tutoring systems that exhibit some capabilities of higher-level language analysis.
Another area where improvements are needed is the ASR of non-native spontaneous speech. While restricted speech, such as reading aloud, can be transcribed automatically with a high accuracy, this is not the case for less predictable speech.
In terms of emerging trends, it can already be observed that systems that offer more interactivity and choice to students, such as intelligent dialog systems or games, are receiving more attention. Further, it can be expected that many applications will transition to portable devices, such as smart phones, and will engage social media, as well as peer-to-peer learning with much stronger emphasis than is the case today.
Finally, it should be pointed out that research and innovations in the educational domain should always be guided by pedagogical considerations and evidence based on students using the technology in question. It is not always feasible to conduct large-scale studies due to difficulties in obtaining participants or funding, as well as in having to cope with ever-changing software (which may be out of date by the time the study is complete). However, efforts for objective evaluations should always be considered a high priority to increase acceptance in the educational community.
Katz, S., Jordan, P., and Litman, D. (2011). Rimac: A Natural-Language Dialogue System that Engages Students in Deep Reasoning Dialogues about Physics. SREE (Society for Research on Educational Effectiveness), Spring Conference, Washington, DC, March.
Attali, Y., and Burstein, J. (2006). Automated essay scoring with e-rater® V. 2. The Journal of Technology, Learning and Assessment, 4(3).
Foltz, P.W., Laham, D., and Landauer, T.K. (1999). The Intelligent Essay
Assessor: Applications to Educational Technology. Interactive Multimedia Electronic Journal of Computer-Enhanced Learning, 1.
Bernstein, J. and Cheng, J. (2007). Logic and validation of fully automatic spoken English test. In M. Holland & F.P. Fisher (Eds.): The path of speech technologies in computer assisted language learning: From research toward practice. Florence, KY: Routledge.
Zechner, K., Higgins, D., Xi, X, & D. M. Williamson (2009). Automatic scoring of non-native spontaneous speech in tests of spoken English. Speech Communication, 51(10), October.
Klaus Zechner is a Managing Senior Research Scientist in the NLP & Speech Group at Educational Testing Service, Princeton, NJ, USA. He can be reached at kzechner@ets.org.
MLSLP 2012 brings together speech, natural language processing, and machine learning researchers
Karen Livescu
SLTC Newsletter, November 2012
The 2nd Symposium on Machine Learning in Speech and Language
Processing (MLSLP) was recently held as a satellite workshop of
Interspeech 2012 in Portland on September 14. The workshop was the
second meeting of the ISCA Special Interest Group on Machine Learning,
and was supported by both ISCA and Google. Like the first such
Symposium held last year in conjunction with ICML and ACL, the goal
was to foster interaction among researchers in speech, language, and
machine learning and provide a focused, relaxed forum for exchanging
current ideas from these fields.
MLSLP 2012 included three talk sessions with 10 invited speakers
and a poster session with 9 submitted papers. The talks and posters
included recent applications of machine learning research to speech
and language processing, as well as topics in machine learning that
may have applications to, or give perspective on, issues in speech and
language.
The invited talk topics in speech processing included structured
discriminative models (Mark Gales), exemplar-/template-based speech
recognition (Dirk Van Compernolle, Georg Heigold), analysis and
generalization of discriminative speech recognition training criteria
(Erik McDermott), and deep learning architectures with kernel modules
(Li Deng). Natural language processing topics included unsupervised
semantic parsing (Hoifung Poon) and transfer learning (Hal Daume III).
At the intersection of speech and language processing was a talk on
discriminative language modeling with hallucinated data (Brian Roark).
Machine learning topics included theoretical analysis of domain
adaptation (Shai Ben-David) and sparse inverse covariance matrix
estimation (Inderjit Dhillon).
The poster session included submissions on adaptation,
semi-supervised learning, boosted features, exemplar methods,
multi-view learning, and low-resource spoken term detection.
Judging by audience participation and attendee feedback, the format
and content were very successful. A third MLSLP with a similar format
is planned for next year, again in conjunction with a speech or
machine learning conference.
Karen Livescu is Assistant Professor at TTI-Chicago in Chicago, IL, USA. Her main interests are in speech and language processing, with a slant toward combining machine learning with knowledge from linguistics and speech science. Email: klivescu@ttic.edu.
Increasing
Popularity of Speech and Audio Event Recognition in Unconstrained Multimedia
Data
Case Study: NIST
TRECVID Multimedia Event Detection Evaluations
Murat Akbacak
SLTC Newsletter, November 2012
Abstract
Due to the popularity of online user-submitted videos, multimedia content
analysis and event modeling for the purposes of event detection and retrieval
is getting more and more attention from the speech and audio processing
communities. As the amount of online multimedia data is increasing every day,
and the users' search needs are changing from simple content search (e.g., find
me today's Giants videos) to more sophisticated searches (e.g., find me this
week's Giants home-run video snippets), speech and audio components are
becoming more important as they convey complimentary and richer information to
image/video content. In other words, video imagery features play a significant
role in determining the multimedia content; however, audio and speech components
for a video can also be critical. When we consider the above example of
detecting a home run in baseball game videos, analysis of the frame-level
imagery may determine that the setting is a baseball game and players are
running in the scene being analyzed, but without the capability to capture
cheering in the audio or the spoken comments, it would be significantly more
difficult to discriminate between an uneventful game and one with a home run.
In this article, we will talk about the increasing popularity of speech
recognition and audio event recognition technologies for multimedia content
analysis. We will also present the challenges as well as the ongoing research
efforts in these two fields by using Multimedia Event Detection (MED) track of
NIST TRECVID evaluations as our case study.
Introduction
In the last two decades, there have been great advancements in speech
recognition field. Due to these advancements, speech recognition became part of
larger applications where speech-to-speech translation, spoken document
retrieval, and voice search are just couple of them. One area of advancement
was moving from limited-vocabulary tasks to large-vocabulary tasks. Another
important advancement was moving from clean acoustic conditions to noisy
conditions by using robust modeling approaches as well as robust front-end
extraction algorithms. Another area of research has focused on multilingual
aspects of speech recognition as the speech data became available in a rapidly
increasing number of languages. All of these studies have been evaluated in
domains like conversational telephone speech, broadcast news, or meetings, on
somewhat constrained data. National Institute of Standards and Technology
(NIST) presents the history of automatic speech recognition evaluations in the
last two decades [1]. More recently, speech researchers are exploring more
unconstrained domains (e.g., historical archives, internet data, and
user-generated videos) where both acoustic and language content are much
broader and varying than previously evaluated domains.
In parallel to modeling advancements in speech recognition field, there has
been good amount of work, mostly published in conferences like ICASSP and
INTERSPEECH, on recognizing acoustic events or conditions to characterize the
non-spoken content of audio material. Similar to speech recognition, audio
event recognition was initially evaluated in controlled settings and/or with
limited number of classes (e.g., CLEAR evaluations [2] where data was collected
in meeting rooms in a controlled way). There has been some work done to use
acoustic condition information to improve performance of automatic speech
recognition (e.g., [3]) or to improve spoken document retrieval (e.g., [4]) in
historical archives, but these two technologies, namely automatic speech
recognition and acoustic event recognition, have been mostly employed in
separate applications until recently when both of these technologies gain
importance to characterize multimedia content under NIST TRECVID Multimedia
Event Detection (MED) evaluations. This is an exciting research area for speech
and audio processing communities, not only because it is bringing together
researchers from these areas presenting opportunities to leverage algorithms
and approaches, but also because it takes these two technologies to a different
level where they are exposed to unconstrained data presenting new research
problems for these communities.
TRECVID Multimedia
Event Detection Task
The Text Retrieval Conference (TREC) series is sponsored by the National
Institute of Standards and Technology (NIST) with additional support from other
U.S. government agencies. The goal of the conference series is to encourage
research in information retrieval by providing a large test collection, uniform
scoring procedures, and a forum for organizations interested in comparing their
results. In 2001 and 2002, the TREC series sponsored a video "track"
devoted to research in automatic segmentation, indexing, and content-based
retrieval of digital video. Beginning in 2003, this track became an independent
evaluation, called TRECVID, with a workshop taking place just before TREC.
Starting in 2010, the Multimedia Event Detection (MED) evaluation track started
under TRECVID. The purpose of the MED evaluation [5] is to characterize the
performance of multimedia event detection systems, which aim to detect
user-defined events involving people in massive, continuously growing video
collections, such as those found on the Internet. This is an extremely
challenging problem, because the contents of the videos in these collections
are completely unconstrained, and the collections include varying qualities of
user-generated videos, which are often made with handheld cameras. From an
automatic speech recognition and acoustic event recognition perspective, this
presents a challenging scenario due to different recording environments or
devices.
In the MED evaluation, each event is defined by an event kit which consists
of an event name, definition, explication (textual exposition of the terms and
concepts), evidential descriptions, and illustrative video exemplars. Systems
in the MED evaluation use the event kit to generate an event agent, which
identifies videos in the target video collection that contain the specified
event. The event agent is executed on metadata that has been pre-computed from
the video collection. The goal of a MED system is to achieve event detection
performance with low miss and false-alarm rates and to achieve an operating
point that corresponds to a ratio of miss and false-alarm rates near a
specified target error ratio (TER).
The number of video exemplars used for training event agents affects system
performance. This year's MED evaluation specifies two levels of exemplars to be
used: EKFull, which uses the actual event definition and about 130 videos; and
EK10Ex, which uses a specified set of ten positive and ten related video
exemplars. In addition, other videos that are not positives or related to other
events can be used as negatives for training. The MED evaluation uses the HAVIC
video data collection, which is a large corpus of Internet multimedia files
collected by the Linguistic Data Consortium and distributed as MPEG-4 (MPEG-4,
2010) formatted files containing H.264 (H.264, 2010) encoded video and MPEG-4's
Advanced Audio Coding (ACC) (ACC, 2010) encoded audio. The training material
consisted of 1200 hours of HAVIC material (about 47,000 videos), and the
evaluation was run on 2500 hours of HAVIC material (about 99,000 videos).
Twenty five event kits were used in this year's evaluation. For the list of
this year's events, please visit the NIST MED website [6].
Spoken and Audio
Concept Extraction Approaches for MED Task
To handle this challenging problem, systems typically extract a set of
heterogeneous low-level audio, visual, and motion features, as well as
higher-level semantic content in the form of audio and visual concepts, spoken
text, and video text. Each type of feature or semantic content is extracted by
one or more event classifiers that are trained with examples from the training
set. Some approaches involve early fusion methods that combine low-level visual
and audio features [7]. Final event detection results are typically generated
by combining the results for the multiple event classifiers using a variety of
decision-based fusion methods. Papers which describe the approaches used in the
last year's TRECVID MED evaluation can be found at [8], and very soon papers for
this year's systems will be posted on the same website once the workshop takes
place in November 2012. Research groups at SRI International, Columbia
University, ICSI Berkeley, Carnegie Mellon University, University of Illinois
at Urbana Champaign, Georgia Institute of Technology, and Raytheon BBN, have
been working on extracting and modeling spoken and/or audio concepts for MED
task. Most of these research sites, if not all, are sponsored under the IARPA
Aladdin program to participate at these evaluations, and collaborate with
researchers from image and video processing fields.
Spoken concepts (e.g., words) are extracted using an ASR engine. The main
challenges in extracting ASR output on MED dataset are mismatches in acoustic
and language models as the data is so heterogeneous in terms of acoustic
conditions (e.g., different recording conditions and equipment, varying quality
of speech, background noise or sounds overlapped with speech, etc.) and topical
content, as well as different languages being spoken in the videos. To recover
from recognition errors, either 1-best or N-best hypothesis are used as
features for MED classifiers, along with some keyword expansion techniques [9].
In addition to word hypothesis, some studies (e.g., [10]) explore using multilingual
phone recognizers to model spoken content, especially because spoken content in
MED12 dataset contains speech from different languages, not just English. On a
historical side note, in 2002, TRECVID Spoken Document Retrieval (SDR) track
was concluded by considering SDR a solved problem. Yes, SDR might be a solved
problem for Broadcast News domain, however there are still many challenges to
employ ASR for tasks like MED, especially on unconstrained data like
user-generated videos. Given the level of challenge being faced, it would be
interesting to see more ASR researchers using this kind of data for their
research.
Audio concept extraction approaches explored under MED task can be grouped
into: (1) supervised and (2) unsupervised approaches. In the first group, one
popular approach for modeling the audio component is referred to as the
bag-of-audio-words (BoAW) method. The BoAW method has the advantage of being an unsupervised
approach and therefore does not require laborious human annotation efforts. The
method is inspired by the well-established techniques, such as bag-of-words (BoW) for text documents and bag-of-visual-words (BoVW) for document images. In this approach, all
frame-level features are clustered (e.g., via vector quantization), and then VQ
indices are used as features within a classifier (e.g., SVM classifier with
histogram kernel) to model audio content for MED task. [11] presents the
results on MED11 dataset by exploring different configurations. Other
unsupervised approaches focused on segmenting the audio track, and then either
cluster the segments to form atomic sound units and then word-like units
[12,13], or model the segments with GMM super-vectors [14,10], or I-vectors
[15] which are commonly used in speaker recognition community. In the second
group of approaches, audio concept/event models are trained using annotated
data [16,17]. For example, in [17], segments are represented with segmental-GMM
vectors, and then a signature matrix is extracted from all the segmental-GMM
vectors from the video document. Although first group of approaches have the
advantage of not requiring labeled acoustic event data, they do not present
semantic labels to allow semantic searches, which might be critical for ad-hoc
MED evaluation which started taking place in MED12.
As we mentioned, these supervised approaches rely on the availability of
annotated data. The content and quality of the audio in user-generated videos
differ from those of audio from other sources. There is a dearth of data sets
of user-generated videos annotated with audio concepts [16,17]. A few teams who
have submitted systems for the MED evaluation have begun their own audio
annotation efforts. However, organizing a cooperative community-wide annotation
effort that distributes the effort and shares the resulting annotated data
across research teams would benefit the research community as a whole and
enable further research in the use of higher level semantic concepts for
multimedia event detection. Research groups working on speech and audio concept
extraction under TRECVID MED evaluation have already created a working group to
coordinate this effort. On the ASR side, NIST is continuing transcription
effort on MED videos, and as more data is transcribed, it would be useful for
ASR researchers to focus on evaluating robust techniques on this dataset. We
believe that ASR would benefit from the progress in acoustic event recognition
field to better compensate the impact of background sounds or noise on speech
recognition by knowing more about the characteristics of the acoustic
conditions. TRECVID MED task has the potential to embrace other speech
processing technologies, such as language, emotion, or speaker identification
which would be useful features to detect higher-level events for MED or to
assist ASR (e.g., employing the right language-specific recognizer via LID).
This would allow rich transcription of speech and audio. In some ways this will
be similar to NIST Rich Transcription evaluations, but this time much richer
information will be extracted in more unconstrained data.
Acknowledgements
Author would like to thank Gregory K. Myers from SRI International, Stephanie
Pancoast from Stanford University, and Diego Castan from University of Zaragoza
for helping with this article.
[3]M. Akbacak, J.H.L. Hansen,
"Environmental Sniffing: Noise Knowledge Estimation for Robust Speech
Systems," in IEEE Transactions on Audio, Speech and Language Processing,
vol. 15, no.2, pp. 465-477, Feb. 2007.
[4]M. Akbacak, "Robust
spoken document retrieval in multilingual and noisy acoustic
environments", Ph.D. Thesis, University of Colorado at Boulder, 2007.
[9]S. Tsakalidis,
X. Zhuang, R. Hsiao, S. Wu, P. Natarajan,
R. Prasad, P. Natarajan, "Robust Event Detection
From Spoken Content In Consumer Domain Videos", Interspeech
Conference, 2012.
[10]Qin
Jin, Peter F. Schulam, ShourabhRawat, Susanne Burger, Duo Ding, and Florian Metze, "Event-based Video Retrieval Using Audio",
Interspeech 2012.
[11]S.
Pancoast and M. Akbacak, "Bag-of-audio-words approach for multimedia event
classification", in Interspeech2012, 2012.
[12]B.
Byun, I. Kim, S.M. Siniscalchi,
C.H. Lee , "Consumer-level multimedia event detection through unsupervised
audio signal modeling", Interspeech Conference,
2012.
[13]S.
Chaudhuri, R. Singh, B. Raj, "Exploiting
Temporal Sequence Structure for Semantic Analysis of Multimedia", Interspeech Conference, 2012.
[14]R.
Mertens, H. Lei, L. Gottlieb, G. Friedland, and A. Divakaran, "Acoustic super models for large scale
video event detection", in Proceedings of the 2011 joint ACM workshop on
Modeling and representing events. ACM, 2011.
[15]X.
Zhuang, S. Tsakalidis, S.
Wu, P. Natarajan, R. Prasad, P. Natarajan,
"Compact Audio Representation for Event Detection in Consumer Media",
Interspeech Conference, 2012.
[16]Y.G.
Jiang, X. Zeng, G. Ye, S. Bhattacharya, D. Ellis, M.
Shah, S.F. Chang, "Columbia-UCF TRECVID2010 Multimedia Event Detection:
Combining Multiple Modalities, Contextual Concepts, and Temporal
Matching", Proceedings of TrecVid 2010,
Gaithersburg, MD, December 2010.
[17]S.
Pancoast, M. Akbacak, and M. Sanchez, "Supervised acoustic concept
extraction for multimedia event detection", in ACM Multimedia Workshop,
2012.
Murat Akbacak is a Senior Scientist at Microsoft. His interests are
mainly in robust audio search, voice search, speech recognition, conversational
understanding, and multimedia analysis. Email: Murat.Akbacak@microsoft.com.
A Glimpse of IEEE SLT 2012
SLTC Newsletter, November 2012
The fourth biannual IEEE SLT workshop will be in Miami, Dec 2-5, 2012. Full preparation for the workshop is currently underway, and the conference program has been finalized. The accepted papers cover a wide range of topics in spoken language technology, ranging from speech recognition to various language understanding applications.
We have tried to improve the SLT experience on several fronts this year. We have organized three tutorials (free of charge), running in sequence, on very hot research topics. We are privileged to have Sanjeev Khudanpur talk about "Statistical Language Modeling Turns Thirty-Something: Are We Ready To Settle Down?", Timothy Hazen on "The Theory and Application of Latent Topic Models", and Paul Crook on "Statistical Dialogue Management for Conversational Spoken Interfaces: How, Why and Scaling-up".
We also have two panel discussions on topics of interest to the research community. One panel is "The Future of SLT Academic Research" and the other is: "Beyond Siri: Next Generation Information Services". These topics will be debated and discussed from the perspective of academia, industry, and government. We hope these panel discussions will be informative to the workshop attendees.
We are privileged to have a set of invited talks illustrating many new research, technologies and applications: "The Conversational Web" (Larry Heck), Structure Transformation for Machine Translation: Strings, Trees, and Graphs" (Kevin Knight), "Language as influence(d)" (Lillian Lee) and "Deep Neural Networks for Large Vocabulary Speech Recognition" (Andrew Senior).
We look forward to seeing you at SLT in Miami!
General Chairs
Ruhi Sarikaya (Microsoft) and Yang Liu (University of Texas at Dallas)
Pay Attention, Please:
Attention at the Telluride Neuromorphic Cognition Workshop
Malcolm Slaney
SLTC Newsletter, November 2012
The role of attention is growing in importance as speech recognition
moves into more challenging environments. Attention is not a factor
when we speak into a close-talking microphone with a push-to-talk
button. But the acoustic world in which we live is not so simple;
multiple sources add together in a confusing mixture of sound, making
it difficult to analyze any one source. In such settings, attention
serves two important purposes: 1) It helps us to focus our
computational resources on the problem at hand, and 2) it helps us to
piece together portions of our environment to solve a single task.
Understanding how attention works may be the critical advance that
allows us to build speech-recognition machines that cope with complex,
everyday settings robustly and flexibly, just as a human listener
does.
My interest in attention stems from a realization that we cannot solve
the speech recognition problem using a purely bottom-up engineering
approach. As an engineer I am trained to build a system starting with
fundamental principles, a solid foundation. This tendency by the
entire field leads to models where all the information flow is
directed in one direction, from the ears or microphone to the final
linguistic output. This approach has served us well, so far....
Yet, our acoustic world is too complicated for such a simple approach.
Many years ago I attended a conference on binaural hearing. Most of
the world's experts on binaural perception were in attendance and
there was much serious discussion about how we localize sounds and the
cues necessary to make this work [1]. But whenever the discussion
got difficult, somebody would stand up and say "We can't do that, it's
the c-word!!!" The c-word was either cognition or cortex, which at
the time seemed like an impossibly hard problem to tackle. We no
longer have this luxury. We must understand the role cognition plays
in speech understanding, if for no other reason than our machines must
"play" in this world. Attention is one important part of this puzzle.
I've had the privilege to help lead three recent projects on attention
at the Neuromorphic Cognition Workshop [2]. These projects have studied
different parts of attention in a short, focused, working workshop.
During the summer of 2011 we studied and built a complete
cocktail-party system, with both top-down and bottom-up signals. In
the summer of 2012 we used EEG signals to "listen" to a subject's
brain and decode which of two speech signals he was attending. I will
describe the Neuromorphic Engineering Workshop, and then the two
latest attention projects.
What is Neuromorphic Cognition?
The Telluride Neuromorphic Cognition Workshop brings together
engineers, biologists, and neurophysiologists to study problems
related to human cognition. It is held for three weeks every summer in
the western Colorado mountain town of Telluride. It is a real working
workshop, in the sense that people bring their VLSI chips,
oscilloscopes, prototype robots, and measurement equipment and do real
work. In past years we have had scientists measuring the neural spikes
from the visual cortex of a (locally caught) dragonfly; sitting next
to the technologist that designed the Robosapien [3] line of walking
robotic toys; sitting next to modelers that are building models of
learning in cortical systems, using both computational and VLSI
models.
The biggest strength of the workshop is bringing a range of faculty
and young researchers together, from many different institutions
around the world, to actually work on problems of joint interest.
There are usually about 30 faculty members presenting their research
and leading projects. About 40 young researchers, Ph.D. students and
post-docs, are in Telluride to learn and work. Some of the projects
are related to their area of expertise, while other projects are not.
A typical day starts with lectures and discussions in the morning, and
project meetings and work from noon till late at night. The small town and
surrounding mountains give us enough room to explore, but keep us
close enough so we are always working.
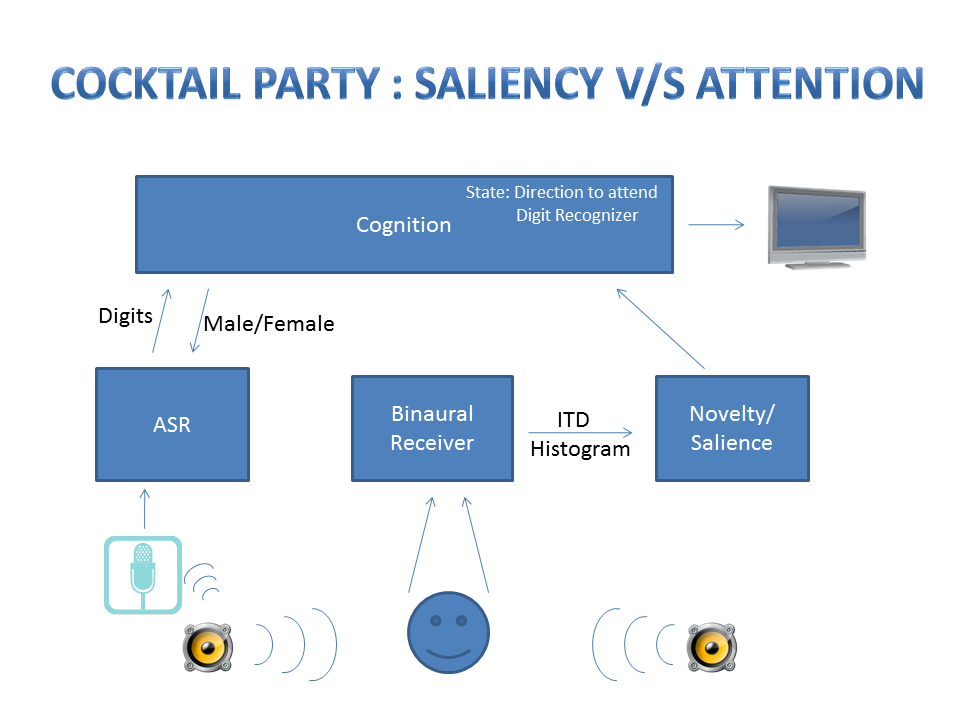
A Cocktail Party
Our project during the summer of 2011 aimed to model the cocktail
party effect by building a real-time system for understanding speech
with two speakers [4]. A key aspect of this problem
is having a way to describe and build both bottom-up and top-down
signal-processing pathways.
The bottom-up pathway is easy. Our current recognizers look at an
acoustic signal, and under the constraint of a language model,
recognize the speech that is heard. Creating a useful top-down pathway
is harder. What does our cortex tell the speech recognizer to make it
easier to understand speech and reach our goals?
We built a real-time cocktail party analyzer by combining bottom-up
processing for speech recognition and binaural localization, with a
"cognitive" model that directs attention to the most important signal.
In a real cocktail party we shift our attention, sampling different
audio streams, looking for the signal with the highest "information"
content. With a tip of the hat to Claude Shannon, information content
is difficult to define in this scenario. You might be nodding
pleasantly as the person in front of you talks about their vacation to
Kansas, while listening to the woman behind you talk about where to go
for dinner after the party. Both are forms of information.
Both exogenous and endogenous processes are important to a model of
attention. Exogeneous (or external) signals redirect our attention
when we hear new sounds. We are especially sensitive to such signals,
perhaps because sudden auditory onsets warned us of approaching
predators. Now exogenous signals (bottom-up) are used to alert us to
new speakers and to higher-level information such as changes in
topics.
Modeling endogenous (or internal) processes is harder. Endogenous
signals come from within, and are goal directed. I really need to
listen to Bob, but if Susan starts talking about me I'll listen to
that instead. This is where the informational goals of the listener
meet the road. Do I keep listening to Bob drone on, or do I switch to
Susan? Our "cognitive" model embodied this decision process.
In the real world, we use lots of information to judge the potential
value of a signal. We know the past history of a speaker and his or
her value to us. We know that some subjects are more interesting than
others. And our priorities change with time. We operate in an
information-foraging mode [5], sampling different parts of
the cocktail party, as we learn and change from our environment.
In our Telluride model, we replaced the dirty real world with
two-digit numerical strings from two different speakers. This made it
trivial to assign information content to the signal---the value of the
signal is the numerical value of the two-digit string. Our cocktail
party analyzer's problem was then to choose the speaker that is most
likely to give the highest value digit strings. We had a binaural
cochlear model, implemented in VLSI, and we used the output from this
chip, along with a simple energy-change detector to prime exogeneous
attention. When new energy is detected from some direction in the
sound field, we sent a signal to the cognition model to get its
attention. The cognition model also had access to the output from a
speech recognizer that was listening to just one direction at a time.
The cognition model's goal was to direct the speech-recognition system
to listen to the one stream, over time, that would maximize the
received information. In our case, that was the sum of the values of
the correctly received two-digit sentences.
To demonstrate the value of a cognitive model, even a primitive one,
we implemented several different information-gathering strategies. In
the simplest model that we labeled as "distracted," the cognition
module switched the speech recognizer to a new direction every time a
new speaker started speaking. The "smart" cognitive model received the
same inputs, but only switched to the new speaker when the information
content of the current speaker was judged to be low. This was based on
the value of the first digit received. If the first digit of the
sentence is less than 5, then the entire signal is likely to be low
value, and we might more profitably use our resources to listen to the
new direction.
This model is valuable because it demonstrates all the pieces of a
real cocktail party analyzer in one place. While we "cheated" in many
ways---for example using digit strings instead of semantically rich
signals, or using a DTW-based recognizer instead of a full HMM---the
system has all the right pieces, and demonstrates both exogenous and
endogenous, both top-down and bottom-up processing [6]. We
hope future cocktail-party analyzers will build upon this model of
attention to do even better.
Decoding Attention in Real Time
Our project during the summer of 2012 aimed to decode human attention
[7]. Attention is a latent signal. While your eyes
might be looking at me, you are really thinking about lunch---we can't
always tell from external signals. Thus, we want to measure a signal
from a human brain, decode it, and then decide to which signal the
subject is listening. From a scientific point of view, this will tell
us more about how the auditory system decodes speech in a noisy
environment. From a practical point of view, having a machine that
knows what you are attending to will make it easier for the machine to
complement human behavior.
An auditory attention-decoding experiment has been done using
electrodes implanted over auditory cortex [8]. These
patients are being monitored for seizures, but in the mean time some
are available for experiments. Mesgarani and Chang use
system-identification techniques to correlate the speech information
with a cortical neuron's output. They invert this model to estimate
the speech that generated a given spike train. At the locations from
which they are recording spikes, they discovered that the neural
responses best correspond to the speech signal to which the subject
was told to attend.
We can do a lot of research in Telluride, but surgically implanting
electrodes in human subjects is difficult. Instead, we used EEG
(electroencephalography) to measure brain responses, and thus infer
the direction of attention. We believe this is the first time this has
been done in real time, on any kind of subject.
EEG is a very rough measurement technique compared to direct neural
recordings. The received signal represents the combined response to
hundreds of thousands of neurons over centimeters of space. But yet
over time, and with sufficient averaging, EEG signals do contain
information about the internal state of a subject.
We used a system-identification scheme to model the auditory to EEG
pathway. Our subject first listened to audio, while we recorded 32
channels of EEG signals. We could then build models that correlate the
attended audio and EEG signals, to create forward and the inverse
models. In the online experiment we moved the subject to a different
room and presented two speech signals to the subject, both diotically
and dichotically. The subject was told to attend to one or the other
signal, and then we decoded the resulting EEG signals. We could use
the inverse system model to predict the incoming audio, and then
compare the prediction to the two known input speech signals. In the
best case, we could determine the attended signal with 95% accuracy
using a 60-second long decision window.
Conclusions
Telluride and the Neuromorphic Cognition Workshop are a wonderful
venue to foster new collaborations on cutting edge topics related to
human perception and cognition. Project proposals are submitted
towards the end of the year, and a small number of them are chosen as
focus areas for the coming summer. The project leaders choose their
faculty. Student applications are accepted in the early part of the
year, and about 40 students are selected and given housing assistance
for the three-week workshop. I enjoy the collaboration and chance to
meet and work with new people. But the experience is intense---I have
pulled more all-nighters, preparing for the final Telluride demos,
than I have for any other reason since graduate school. I hope to meet
you in Telluride.
Acknowledgements
The attention work described in this report is due to the contributions of
many, many participants, but I do want to thank my co-leaders: Shihab
Shamma, Barbara Shinn-Cunningham, Ed Lalor, Adrian KC Lee, Mounya Elhilali
and Julio Martinez-Trujillo. The project participants are listed in an
appendix to this column. We appreciate the financial support of the NSF, ONR
and EU ERC. We are grateful for the equipment support we received from
BrainVision and software support from Mathworks.
Appendix
A large number of people contributed to these two projects. I would like to acknowledge their contributions, both big and small.
Adam McLeod, Adam O'Donovan, Adrian KC Lee, Andreas Andreou, Asha Gopinathan, Barbara Shinn-Cunningham, Bruce Bobier, Ching Teo, Claire Chamers, Connie Cheung, Daniel B. Fasnacht, Diana Sidtis, Dimitris Pinotsis, Edmund Lalor, Fabio Stefanini, Francisco Barranco, Fred Hamker, Inyong Choi, James Wright, Janelle Szary, Jeffrey Pompe, Jennifer Hasler, Jonathan Brumberg, Jonathan Tapson, Jongkil Park, Julio Martinez-Trujillo, Kailash Patil, Lakshmi Krishnan, Magdalena Kogutowska, Malcolm Slaney , Mathis Richter, Matthew Runchey, Mehdi Khamassi, Merve Kaya, Michael Pfeiffer, Mounya Elhilali, Nai Ding, Nils Peters, Nima Mesgarani, Nuno Vasconcelos, Ozlem Kalinli, Roi Kliper, Ryad Benjamin Benosman, Sahar Akram, Samuel Shapero, Shihab Shamma, Shih-Chii Liu, Siddharth Joshi, Siddharth Rajaram, Sudarshan Ramenahalli, Theodore Yu, Thomas Murray, Timmer Horiuchi, Tobi Delbruck, Tomas Figliolia, Trevor Agus, Troy Lau, Yan Wu, Yezhou Yang, Ying-Yee Kong, Yulia Sandamirskaya
References
[1] Robert H. Gilkey and Timothy R. Anderson, eds. Binaural and Spatial
Hearing in Real and Virtual Environments. Lawrence Erlbaum Associates,
Mahwah, NJ, 1997.
[5] P. Pirolli and S. Card. Information foraging. Psychological
Review,
106, 643-675, 1999.
[6] Malcolm Slaney, Trevor Agus, Shih-Chii Liu, Merve Kaya, Mounya
Elhilali. "A Model of Attention-Driven Scene Analysis." Proceedings of
the International Conference on Acoustics, Speech and Signal
Processing, Kyoto, Japan, March, 2012.
[8] Nima Mesgarani and Edward F. Chang. Selective cortical representation
of attended speaker in multi-talker speech perception. Nature, 485,
pp.
233-236, 2012.
Malcolm Slaney is a Principal Researcher in the Conversational Systems Research Center at Microsoft Research, and a (Consulting) Professor at Stanford CCRMA. He is interested in all aspects of auditory perception. Email: malcolm@ieee.org
The 10th Information Technology Society Conference on Speech Communication
David Suendermann
SLTC Newsletter, November 2012
This article provides a short review of the 10th Information Technology Society Conference on Speech Communication held in Braunschweig, Germany, September 26 to 28. Organized by a primarily German scientific committee, the conference has grown very selective with a good number of major contributors in the field (e.g. the keynote speaker Steve Young and at least five more SLTC members involved as organizers, chairs, etc.). Sessions spanned a wide range of domains such as Spoken Language Processing, Speech Information Retrieval, Robust Speech Recognition, or Automotive Speech Applications, and were hosted at the Braunschweig University of Technology, well-known for Carl Friedrich Gauss, former professor at this university.
Being part of the VDE Association for Electrical, Electronic and Information Technologies, one of Europe's largest technical and scientific associations (founded in 1893, thereby 70 years older than the IEEE), the Information Technology Society organizes its Speech Communication conference roughly every two years. The first of these conferences was held in Munich in 1986, the founding year of the SLTC. The 10th anniversary conference took place from September 26 to 28 in Braunschweig (aka Brunswick), Germany. Chaired by the SLTC member Tim Fingscheidt, the conference was supported by a scientific committee of 20 respected researchers in the field of speech processing and acoustics (including four SLTC members).
75 papers were accepted for publication at the conference after a review process similar to that of IEEE conferences and workshops. In fact, the proceedings were published on IEEE Xplore requiring a strict format and quality standard of the accepted papers and the publication language to be English. The program consisted of the following eight sessions (two oral; one booster, that is a poster session complemented by a very short oral presentation; and five mixed oral/poster):
Noise & Echo Control
Multi-X Recognition and Localization
Automotive Speech Applications
Topics in Spoken Language Processing
Speech and Audio Information Retrieval
Speech Perception and Quality Assessment
Robust and Distant Speech Recognition
Hearing Aids Speech Processing
These sessions were complemented by four keynotes:
Emanuel Habets (University of Erlangen-Nuremberg): Microphone Array Processing: Perspectives and Challenges
Steve Young (University of Cambridge): EURASIP Seminar on Recent Developments in Statistical Spoken Dialogue Systems
David Suendermann (DHBW Stuttgart): 25 Years of Voice Conversion: Where Are We Heading Now?
Hugo Fastl (Technical University Munich): Prof. Paulus 75th Birthday Keynote on Psychoacoustic Aspects of Speech Communication
Assembly in front of the university's main building
As the oldest technical university in Germany, the Braunscheig University of Technology (founded in 1745) has a traditional focus on automotive research. Accordingly, a major subject area at the conference was around automotive applications and related topics such as microphone arrays, noise suppression, or robust speech recognition. The 137 registered participants featured representatives of all major German universities and companies active in the field of speech processing and a considerable international audience as well. The next conference will take place in September 2014 at the University of Erlangen-Nuremberg.
David Suendermann is department head and full professor of computer science at the DHBW Stuttgart
SANE Conference Overview
Tara N. Sainath
SLTC Newsletter, November 2012
The Speech and Audio in the Northeast (SANE) Conference was held on October 24, 2012 at Mitsubishi Electric Research Laboratories (MERL) in Cambridge, MA. The goal of this meeting was to gather researchers and students in speech and audio from the northeast American continent. The conference featured 8 talks which are outlined in more detail below.
Unsupervised pattern discovery in speech was discussed in three main talks, including talks by Jim Glass and Chia-ying Lee from MIT, T.J. Hazen and David Harwath from Lincoln Labs, and Herb Gish from BBN. Most current speech recognition systems require labeled data for training acoustic, pronunciation and language models. However, given the vast amount of unlabeled data and the difficulty of sometimes obtaining labeled data, there is no doubt unsupervised pattern discovery can help in areas such as learning acoustic sub-word units, lexical dictionaries and higher-level semantic information. Zero-resource learning from spoken audio looks at discovering patterns in speech signals using unsupervised techniques, without any knowledge of labeled transcriptions, language, etc.
These techniques have been explored for acoustic pattern discovery [1], learning of acoustic-phonetic inventories [2], and topic modeling for spoken documents [3].
Tara Sainath from IBM Research presented work on using bottleneck features extracted from Deep Belief Networks (DBNs). The work discusses an alternative bottleneck structure which trains a NN with a constant number of hidden units to predict output targets, and then reduces the dimensionality of these output probabilities through an auto-encoder, to create auto-encoder bottleneck (AE-BN) features [4]. The benefit of placing the BN after the posterior estimation network is that it avoids the loss in frame classification accuracy incurred by networks that place the BN before the softmax. AE-BN features provide between a 10-20% relative improvement over state-of-the-art Gaussian processing techniques across telephony and broadcast news tasks.
Dan Ellis from Columbia spoke about "Recognizing and Classifying Environmental Sounds". Environmental sound recognition is the process of identifying user-relevant acoustic events/sources from a soundtrack. The talk discussed methods to identifying events from real-world consumer video clips [5]. It also discussed doing video classification from audio transients, which represent foreground events in a video scene [6].
Josh McDermott from MIT spoke about 'Understanding Audition via Sound Analysis and Synthesis". Analysis and synthesis of natural sounds allows humans to better understand how sounds are heard and processed [7]. The talk argued that sound synthesis can help us to explore auditory models. More specifically, variables that produce compelling synthesis could underlie perception, while synthesis failures point the way to new variables that might be important for the perceptual system. Auditory models help us to understand how many natural sounds may be recognized, both with simple and more complex models and auditory representations.
Steve Rennie from IBM Research discussed using the Factorial Hidden Restricted Boltzmann Machine (FHRBM) for robust speech recognition. In this work, speech and noise are modeled as independent RBMs [8]. Furthermore, the interaction between speech and noise is explicitly modeled to capture how these components combine to generate observed noisy speech features. The work compares the FHRBMs to the traditional factorial model for noisy speech which is based on GMMs. FHRBMs offer the advantage that the representations of both speech and noise are highly distributed. This allows the model to learn a parts-based representation of noisy speech data that can generalize better to previously unseen noise conditions, producing promising results.
Finally, John Hershey from MERL presented work on "A New Class of Dynamical System Models for Speech and Audio". This work introduces a new family of models called non-negative dynamical systems (NDS), that combine aspects of linear dynamical systems (LDS), hidden Markov models (HMM), and non-negative matrix factorization (NMF), in a simple probabilistic model. In NDS, state and observation variables are non-negative, and the innovation noise is multiplicative and Gamma distributed rather than additive and Gaussian as in LDS. The talk showed how NDS can model frame-to-frame dependencies in audio via structured transitions between the elementary spectral patterns that describe the data. Speech enhancement results were demonstrated on a difficult non-stationary noise task, comparing favorably to standard methods.
Acknowledgements
Thank you to Jonathan Le Roux of MERL for his help in providing content and feedback for this article.
References
[1] A. Park and J. Glass, "Unsupervised pattern discovery in speech," IEEE TASLP, Jan. 2008.
[2] C. Lee and J. Glass, "A nonparametric Bayesian approach to acoustic model discovery," Proc. ACL, Jul. 2012.
[3] T. J. Hazen, M.-H. Siu, H. Gish, S. Lowe and A. Chan, "Topic modeling for spoken documents using only phonetic information," Proc. ASRU, Dec. 2011.
[4] T. N. Sainath, B. Kingsbury, and B. Ramabhadran, "Auto-Encoder Bottleneck Features Using Deep Belief Networks," in Proc. ICASSP, Mar. 2012.
[5] K. Lee and D. Ellis, "Audio-Based Semantic Concept Classification for Consumer Video," IEEE TASLP, Aug. 2010.
[6] C. Cotton, D. Ellis , and A. Loui, "Soundtrack classification by transient events," Proc. ICASSP, May 2011.
[7] J. H. McDermott and E. P. Simoncelli, "Sound texture perception via statistics of the auditory periphery: Evidence from sound synthesis," Neuron, Sep. 2011.
[8] S. Rennie, P. Fousek and P. Dognin, "Factorial Hidden Restricted Boltzmann Machine for Noise Robust Speech Recognition," in Proc. ICASSP, Mar. 2012
If you have comments, corrections, or additions to this article,
please contact the author: Tara Sainath, tsainath [at] us [dot] ibm
[dot] com.
Tara Sainath is a Research Staff Member at IBM T.J. Watson Research Center in New York. Her research interests are mainly in acoustic modeling. Email: tsainath@us.ibm.com
Unfamiliar applications of some familiar techniques
Martin Russell, Chris Baber, Manish Parekh and Emilie Jean-Baptiste
SLTC Newsletter, November 2012
This article considers applications in other domains, of techniques that are familiar in the context of speech and language processing. The focus is the EU CogWatch project, although there are many other examples. Do technique such as hidden Markov models (HMMs) lend themselves naturally to these new domains, or is it just an instance of Maslow's hammer [2], or perhaps (apologies to Maslow) a variant that should be referred to as Maslow's HMMer - "I suppose it is tempting, if the only tool you have is a HMM, to treat everything as if it were speech recognition"? This article briefly explores this issue and argues that this is not the case, that these methods are appropriate because of the nature of the problems, that these new applications can benefit from the experience and investment of the speech and language research community, and that, conversely, challenges in these new areas might give new insights into difficult speech and language processing problems.
Introduction
CogWatch is a European Union Framework 7 research project. It involves the University of Birmingham, BTM Group Limited, Headwise Limited, RGB Medical Devices SA, Technische Universität München, The Stroke Association, and Universidad Politéchnica de Madrid. Its objective is to develop rehabilitation technologies that help patients who are recovering from a stroke to complete a range of activities of daily living (ADL) independently. A third of these patients will experience long term physiological or cognitive disabilities, and a significant proportion can suffer from Apraxia or Action Disorganisation Syndrome (AADS), where symptoms include impairment of cognitive abilities to carry out ADL [1]. The CogWatch system will track a participant's progress as he or she tries to complete an activity, and return an appropriate cue if an error occurs or is judged by the system to be imminent. The focus of the first prototype system is the activity of making a cup of tea, but the project will expand to include other ADLs such as dressing, food preparation and grooming.
Similarities with Spoken Dialogue Systems
Using a method from HCI called Hierarchical Task Analysis (HTA), an activity, or goal, such as tea making can be broken down into a hierarchy of sub-goals, tasks and sub-tasks. Many different sequences of sub-goals can constitute a successful completion of an the activity like tea making, and there are typically many alternative instantiations of a sub-goal as a sequence of tasks. In order to monitor the patient's progress through the activity, each of the objects involved is fitted with a 'CogWatch instrumented coaster' (CIC). This is an electronic drink mat, containing an accelerometer, three force sensitive resistors (FSRs) and a 'bluetooth' module. The accelerometer data indicates the acceleration of an object in its x, y and z planes, while the FSRs show whether it is resting on a surface or raised in the air and when its weight changes. The time varying sequences of data from these sensors are transmitted via bluetooth, synchronized and passed to an automatic activity recognition (AAR) system, where they are classified as tasks or sub-goals, and these are interpreted by the task model (TM). The job of the TM is to estimate the participant's status with respect to completing the activity at each stage in the interaction, and to intervene appropriately if it judges that an error has occurred or is likely. To someone who has worked for a long time on speech and language technology, this looks very much like a spoken dialogue system (SDS)! Indeed, in the first CogWatch prototype we are using hidden Markov models (HMMs) in the AAR to classify the sensor data into sub-goals or tasks, and a partially observable Markov decision process (POMDP) to model the task.
Not surprisingly, the use of HMMs to interpret accelerometer data is not new (see, for example, [3 - 7]) and POMDPs have also been used previously to model ADLs (see, for example [8]).
Differences from Speech Processing
Although many of the challenges in CogWatch appear to be analogous with problems in speech and language processing, there are clear and interesting differences. For example, although HTA provides a principled approach to breaking down an activity into a hierarchy of basic tasks, there no is agreed standard set of elementary tasks - no common "phone" set. One might speculate that the sequence of sensor outputs from a jug when that jug is lifted is sufficiently similar to the corresponding sensor data when a mug is lifted, to enable both actions to be characterized with the same model (applied to different sets of sensor outputs), but different objects may call for different types of grip, which may result in different movements, and an object full of liquid will certainly be raised more carefully than one that is empty. In addition there will be individual differences between the different lifters. Another fundamental divergence between the two domains is that, because tea-making is potentially a two-handed activity, different sub-goals can be executed simultaneously, or at least their time spans can overlap. This is like a SDS in which two people are interacting with the system simultaneously, both cooperating to complete the same overall goal! Consequently the output of the HMM-based recogniser is not a well-ordered sequence of sub-goals or tasks, but a partially-ordered lattice. This means that standard Viterbi decoding of the input against a grammar is insufficient, and that something more like a set of parallel 'goal detectors' is needed instead. Finally, it is clear that different sub-goals require different sets of features. For example, the sub-goal corresponding to pouring milk into a mug requires sensor outputs from the milk container and the 'receiving' mug, while the sub-goal corresponding to adding a tea-bag to the mug requires sensor outputs for the tea-bag container and the mug. Of course, one could use the complete feature vector in all cases, and leave it to the model to identify which components are relevant to the current classification task, but this introduces noise and unnecessary computational burden.
Non-speech applications such as this give prominence to new types of pattern processing problems, albeit within a familiar pattern processing framework. It is possible that solutions to these problems will have implications for speech processing. For example, going back to the final point of the previous paragraph, in speech recognition it is also evident that different types of feature are relevant to the classification of different phones, and yet in conventional statistical model based approaches we use the same set of 'general purpose' features for all phones.
Some Final Thoughts
In theory, the utility of a particular approach to a particular problem depends on how well the assumptions inherent in the approach match the properties of the problem. From this perspective there are many types of pattern that are more suited to the HMM-based approach than speech (for example, the 'piecewise constant' assumption is certainly better suited to the output of an eye-tracker than to a speech signal). However, in practice utility is often measured in terms of recognition performance, and this certainly accounts for the popularity of HMM-based approaches to speech and language processing. For over 30 years automatic speech recognition has benefitted from significant research effort and investment, and this has led to major progress in terms of performance. It is natural to try to exploit this progress in other fields, so that they benefit from this investment. However, adapting these methods to new, non-speech applications raises new challenges and focuses on different priorities and different aspects of the technology. Hopefully this will give us new insights into speech pattern processing.
Finally, ICASSP would seem to be the natural forum for a discussion of non-speech applications of speech algorithms, because of the diverse backgrounds of the delegates that it attracts.
Acknowledgements and more information
Thanks to Joachim Helmsdörfer and Charmayne Hughes at Technische Universität München, for discussions that have informed this article.
Abraham H. Maslow (1966), The psychology of science
Amft, O., Junker, Holger & Tröster, G. (2005), Detection of eating and drinking arm gestures using inertial body-worn sensors. In 9th IEEE International Symposium on Wearable Computers (ISWC’05), pp. 160-163.
Junker, H. et al., (2008), Gesture spotting with body-worn inertial sensors to detect user activities. Pattern Recognition, 41(6), pp.2010-2024.
Stiefmeier, T. et al., (2006), Combining Motion Sensors and Ultrasonic Hands Tracking for Continuous Activity Recognition in a Maintenance Scenario, 2006 10th IEEE International Symposium on Wearable Computers, pp.97-104.
Tröster, G. & Amft, O., (2008), Recognition of dietary activity events using on-body sensors. Artificial intelligence in medicine, 42(2), pp.121-36.
Ward, J.A. et al., (2006). Activity recognition of assembly tasks using body-worn microphones and accelerometers. IEEE transactions on pattern analysis and machine intelligence, 28(10), pp.1553-67
Hoey, J., von Bertoildi, A., Poupart, P. and Mihailidis, A., (2007), Assisting Persons with Dementia during Handwashing Using a Partially Observable Markov Decision Process, Proc. 5th Int. Conf. on Computer Vision Systems (ICVS 2007).
Martin Russell, Chris Baber, Manish Parekh and Emilie Jean-Baptiste are all with the School of Electronic, Electrical and Computer Engineering at ther University of Birmingham, UK. Email: m.j.russell@bham.ac.uk (Martin Russell)
Grounding and Levels of Understanding in Human-Computer Dialogue
Matthew Marge
SLTC Newsletter, November 2012
Spoken dialogue system researchers have adopted theoretical models of human
conversation; this article describes one theory of human-human communication
and its adaptation to human-computer communication.
Overview
Enabling artificial agents like robots to communicate with people using spoken language has been the dream of many, ranging from Hollywood screenwriters to spoken dialogue system researchers. Dialogue systems for personal use have experienced a dramatic increase in popularity with the release of the Apple’s Siri, a voice-based user interface for iOS devices. When people communicate with each other, they suggest ideas, engage in discussions, and may agree or disagree about ideas. This comes off from person to person as completely natural; it’s a part of our nature.
In human-human communication, Clark [1,2] proposed that people ground the information and
experiences they share with dialogue partners; grounding is the name of the process. When a dialogue partner attempts to ground something under discussion, they are attempting to add it to the common ground they share with their dialogue partners (in other words, the information and experiences they share).
Clark and Schaefer [3] formally defined grounding in the Contribution Model, which states
that at any given point in the dialogue, dialogue partners are contributing to the discourse they
share. At the same time, the contributor is attempting to ensure that dialogue partners register
the contributor’s intention and can add that to their common ground. There are two phases to
every contribution: the presentation phase, where the contributor is presenting a signal (e.g., a spoken language utterance) to a partner, and the acceptance phase, where the partner attempts to understand the contribution, add it to their common ground, then display evidence (e.g., a signal like a nod or verbal acknowledgement) indicating that the contribution has been understood.
Along with the Contribution Model, Clark proposes several levels of understanding, ranging
from understanding that a dialogue partner has uttered something to understanding the full goals and intentions of the dialogue partner [2]. These levels of understanding drive the type of
strategies people use to recover from misunderstandings.
Paek [4] and Bohus [5] have adapted Clark’s levels of understanding to human-computer dialogue, namely for spoken dialogue systems (see Figure 1). From lowest to highest: The Channel level consists of the transfer of the user’s acoustic signal to a dialogue system. The dialogue system must correctly endpoint the user’s utterance, and failure to do so, like cutting off a user mid-sentence, results in an endpointer error. The Signal level involves the communication of words from the user to a dialogue system. The system’s speech recognizer is responsible for transcribing the acoustic signal into words, and misinterpretation of words results in recognition errors. The Intention level describes the transfer of the user’s intentions (i.e., semantics at the level of requested actions and other responses that drive the dialogue) to a dialogue system. The system’s parser attempts to extract this information from recognized speech, and any words that fail to parse are out of parse errors. Finally, the Conversation level describes the transfer of dialogue actions from the user to the agent. Dialogue actions include commands, confirmations, and requests for information. Any dialogue action that falls beyond the scope of the actions the dialogue system can do is an out of application error.
Figure 1: Levels of understanding in human-computer dialogue [4,5].
Robust dialogue systems prepare for errors at all of these levels of understanding. This body of work shows that understanding how people encounter errors in dialogue can inform the type of errors spoken dialogue systems can expect to encounter.
References
[1] Herbert. H. Clark and Susan E. Brennan. "Grounding in communication." Perspectives on Socially Shared Cognition, 13, 1991.
[2] Herbert. H. Clark. Using Language. Cambridge University Press, 1996.
[3] Herbert H. Clark and Edward F. Schaefer. Contributing to discourse. Cognitive Science,
13, 1989.
[4] Tim Paek. Toward a taxonomy of communication errors. EHSD-2003, 2003.
[5] Dan Bohus. Error awareness and recovery in conversational spoken language interfaces.
Ph.D. Dissertation CS-07-124, 2007.
If you have comments, corrections, or additions to this article, please contact the author: Matthew Marge, mrma...@cs.cmu.edu.
Matthew Marge is a doctoral student in the Language Technologies Institute at Carnegie Mellon University. His interests are spoken dialogue systems, human-robot interaction, and crowdsourcing for natural language research.
 Canadian federal law requires all government services to be bilingual. Also, while all government proceedings are in English and French, all proceedings are also simultaneously translated into a number of the native Inuit languages as well. I hope you consider submitting a paper to ICASSP-2013 (Due Date is Nov. 30, 2012), and/or consider attending this conference which promises to be as technically enriching as past ICASSP meetings.
Canadian federal law requires all government services to be bilingual. Also, while all government proceedings are in English and French, all proceedings are also simultaneously translated into a number of the native Inuit languages as well. I hope you consider submitting a paper to ICASSP-2013 (Due Date is Nov. 30, 2012), and/or consider attending this conference which promises to be as technically enriching as past ICASSP meetings.