
TALES Video Player with Dual-Caption Enabled
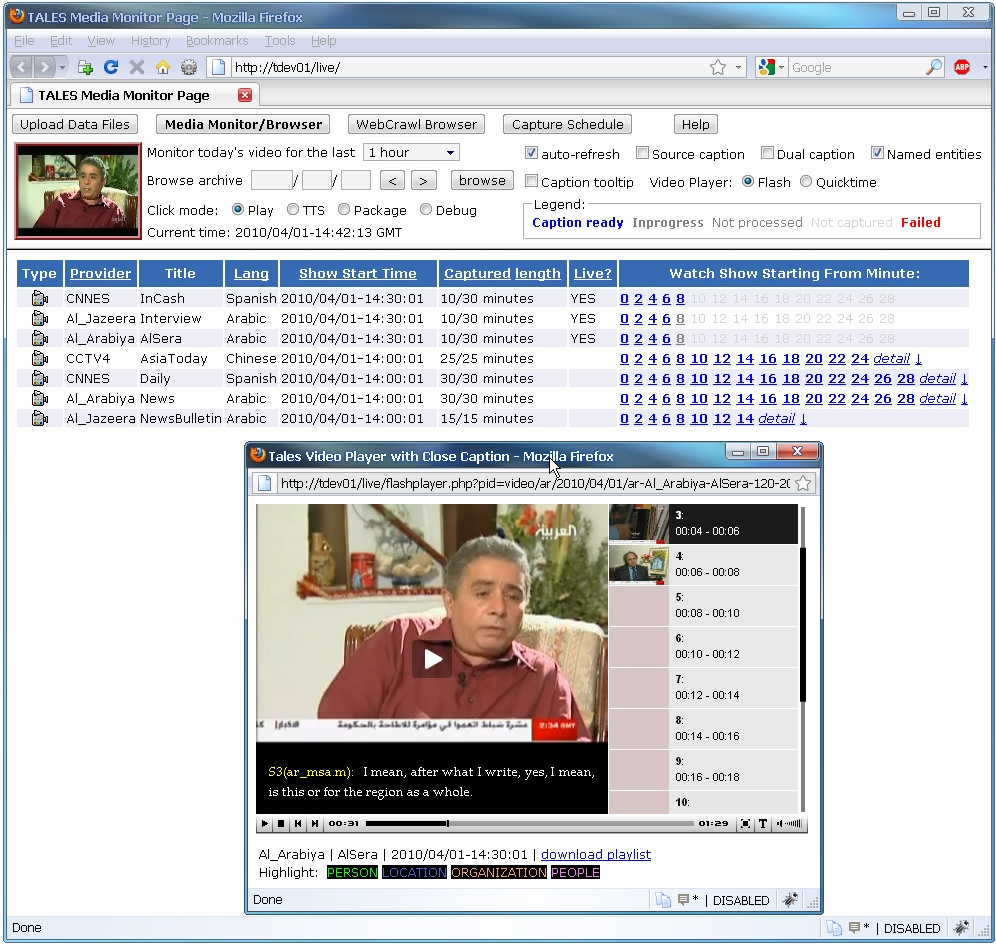
TALES Media Monitor, with a show being monitored
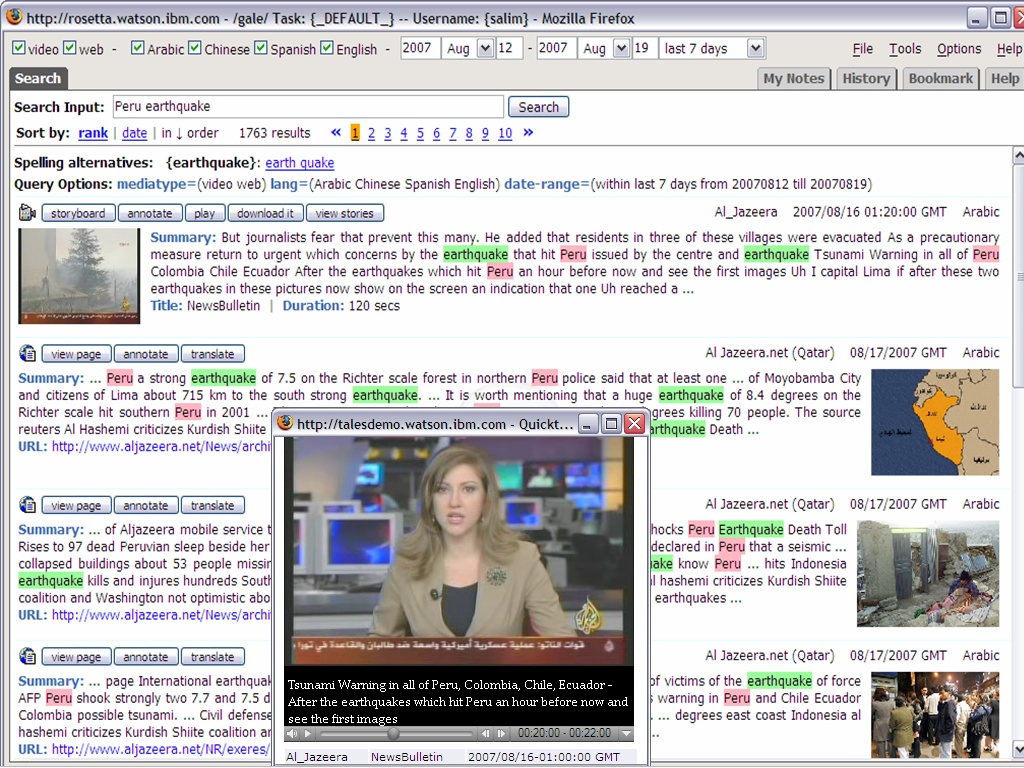
TALES Search UI with Embedded Video Player
![]()
TALES TransBrowser with Correction Mode
Welcome to the Spring 2010 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter.
In this issue we are pleased to provide another installment of brief articles representing a diversity of views and backgrounds. This issue includes articles from 6 guest contributors, and our own 6 staff reporters..
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions. You can reach us at speechnewseds [at] listserv (dot) ieee [dot] org.
Finally, to subscribe the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Jason Williams, Editor-in-chief
Pino Di Fabbrizio, Editor
Martin Russell, Editor
Chuck Wooters, Editor
Any IEEE SPS member interested in Speech and Language or non-IEEE members of professional organizations in related fields can sign up as an affiliate member of the Speech and Language Processing Technical Committee.
The IEEE Signal Processing Society, our parent organization, also produces a monthly newsletter, "Inside Signal Processing".
Brno University of Technology, Czech Republic, is organizing four important speech events this summer. This article briefly introduces NIST SRE 2010 workshop, Speaker Odyssey, and BOSARIS and KALDI research workshops.
Over the last five years, text messaging (also called SMS, short for "short message service") has become an increasingly popular form of communication in many parts of the world. Although state-wide bans on driving while talking on a mobile phone exist in the US, a growing distraction facing drivers is texting while driving. Researchers at the University of Texas at Dallas are addressing this problem by developing a procedure to give text messages a "voice" with speech synthesis systems.
This article describes IBM TALES, a multi-lingual, multi-modal foreign news media monitoring research prototype system. TALES incorporates multiple natural language processing technologies from IBM, such as speech-to-text, machine translation, text-to-speech, information extraction, etc.
Organization for ASRU 2011 is underway -- the committee is in place, Hawaii has been selected as the venue, and IBM has agreed to be a principal sponsor.
As research in language technology continues to develop, insights are contributed from interdisciplinary topics such as robotics and computer investigations into the evolution of language. One researcher pursuing such directions is Luc Steels, Professor of Computer Science at the Free University of Brussels and Director of the Sony Computer Science Laboratory in Paris.
A brief history of SLaTE, the ISCA Special Interest Group on Speech and Language Technology in Education.
35th International Conference on Acoustics, Speech, and Signal Processing (ICASSP) was recently hosted in Dallas, Texas from March 14-19, 2010. The conference included lectures and poster sessions in a variety of speech and signal processing areas. In this article, some of the main acoustic modeling sessions at the conference are discussed in more detail.
This article describes how the role of those professionals usually required to build commercial spoken dialog systems is changing in the dawning age of rigorously exploiting petabytes of data.
The AT&T Statistical Dialog Toolkit V1.0 is now available to the research community. This toolkit simplifies building statistical dialog systems, which maintain a distribution over multiple dialog states.
Earlier this year the Question Generation Shared Task Evaluation Challenge was announced as part of Generation Challenges 2010. This challenge is just one of the ways by which the relatively new QG community expands and at the same time encourages advancements in QG technology.
SLTC Newsletter, April 2010
ICASSP is over for another year and its time to reflect on the year ahead. One of the main talking points at our annual Technical Committee (TC) meeting was the new Bylaws which have now been adopted by the Signal Processing Society. As I mentioned in the last newsletter, these were instigated by Alex Acero with the aim of harmonising the operation of all of the TCs around a common set of Policies and Procedures (P&Ps).
One particular innovation in these new P&Ps is that TCs are now encouraged to recruit a new class of member called an Affiliate. Affiliates are non-elected, non-voting members of the Technical Committee. Any IEEE SPS member interested in Speech and Language or non-IEEE members of professional organizations in related fields can sign up as an affiliate.
Once signed up, affiliate members will receive various TC circulars including calls for Member and Vice Chair nominations, newsletter announcements and invitations to get involved in various TC activities. Affiliates may also be invited to act as reviewers for workshops and conferences.
IEEE student members are particularly welcome as affiliates. Indeed, we need students to affiliate to our TC because we have a new Student Subcommittee whose remit is to engage with students and facilitate greater sharing of ideas and information. We hope that this subcommittee will eventually provide tutorials, courses, networking events, access to job postings, student grants, and other activities of interest to students. This subcommittee will be run by students for students, and its chair will be a student. So if you are a student and you read this, please sign up as an affiliate. Your student status will be noted and you will in due course start to receive information from the Student Subcommittee.
Steve Young
Steve Young is Chair, Speech and Language Technical Committee.
SLTC Newsletter, April 2010
Several exciting speech events will take place at Brno University of Technology (BUT), Czech Republic, this summer. All of them are organized or co-organized by BUT Speech@FIT group (headed by Lukas Burget, Honza Cernocky and Hynek Hermansky) at the Faculty of Information Technology of BUT, and are targeted at speaker and speech recognition.
The show will begin with the NIST (U.S. National Institute of Standards and Technology) Speaker Recognition Evaluation (SRE) workshop on the 24th and 25th of June. NIST’s public evaluations provide valuable calibration of the current state of the art, and thus strongly influence the direction of research. Consequently, much research in the speech and language communities is organized around these evaluations. The workshop is the closing event of every evaluation, where the results are announced, and the participants present the details of their systems.
The following event, "Odyssey 2010 – The Speaker and Language Recognition Workshop", held from 28 June – 1 July, is a small but prestigious event in the speaker and language recognition circles. Odyssey is organized as an ISCA Tutorial and Research Workshop and concentrates on the theory and applications of speaker and language recognition for commercial, forensic, and government applications. This workshop in Brno succeeds previous successful events held in Martigny (1994), Avignon (1998), Crete (2001), Toledo (2004), San Juan (2006) and Stellenbosch (2008).
Unlike the previous two events, BOSARIS’10 (Brno Speaker Recognition Summer Workshop 2010) is a 5-week research workshop. Organized around the core of the group that gathered in 2008 at Johns Hopkins summer workshop group “Robust Speaker Recognition over Varying Channels”, the participants will address the issues of inter-session and environmental robustness, and the speed of SRE systems. Although the results of the workshop are likely to be most interesting to the defense and security community, BOSARIS is not a classified research workshop and results will be made available to the public domain. The workshop is lead by Niko Brummer (Agnitio, South Africa), Patrick Kenny (CRIM, Canada) and Lukas Burget (BUT).
Finally, BUT will host several experienced speech researchers for another five weeks for the “KALDI” workshop. The group will be coordinated by Dan Povey (Microsoft), who also headed the 2009 JHU work-group “Low Development Cost, High Quality Speech Recognition for New Languages and Domains”. The KALDI workshop will focus on open and reusable sets of tools to speed up research and development of speech recognition systems. The title of the workshop has something to do with the devotion of some BUT staff to excellent coffee: according to legend, Kaldi was the Ethiopian goat-herder who discovered the coffee plant. Kaldi was also the original name of BUT’s wFST decoder.
If these four events leave you wanting more speech research in the Czech Republic, remember that a year later, ICASSP 2011 will take place in ... Prague!
Honza Cernocky is Head of Department of Computer Graphics and Multimedia, Faculty of Information Technology, Brno University of Technology, and managing head of BUT Speech@FIT group. Email: cernocky@fit.vutbr.cz
SLTC Newsletter, April 2010
Over the last five years, text messaging (also called SMS, short for "short message service") has become an increasingly popular form of communication in many parts of the world. Although state-wide bans on driving while talking on a mobile phone exist in the US, a growing distraction facing drivers is texting while driving. A recent study showed that people sending text messages in simulated driving tasks were six times more likely to be in car accidents [1]. Those with visual disabilities can also find text messaging (especially reading others' messages) to be a challenge.
Researchers at the University of Texas at Dallas are addressing this problem by developing a procedure to give text messages a "voice" with speech synthesis systems. Synthesizing text messages, however, is not trivial - abbreviations are a common property of text messages, both due to the lack of a full-size keyboard and the linguistic habits of many SMS users. Text messaging "lingo" associated with SMS is often considered a language of its own, with properties such as numbers replacing letters (e.g., "2day" for "today") or the removal of letters in a word (e.g., "sth" for "something"). As is common in most speech synthesis methods, these messages must be normalized into a format that can easily be interpreted by speech synthesizers.
Deana Pennell and others at the Human Language Technology Institute at UT Dallas are developing heuristic and statistical methods for normalizing text messages for synthesis. When asked about the key motivation for this work, "abbreviations are becoming more and more common, and text containing these abbreviations may contain useful information," said Pennell. "This will only become more true as younger generations age, so it is important to begin working on the problem now," she added.
Pennell and her colleagues first developed a set of rules for transforming normal English text to text messaging lingo [2]. These rules included removing characters that only weakly determine the overall phonetic properties of a word, such as the trailing "g" in words ending with "ing" and the silent "e" in words like "cable". Other rules exist at the syllabic level, such as the removal of vowels that are in the interior of a word's syllables (e.g., transforming "disk" to "dsk").
They are also developing a binary decision classifier to create abbreviations from English words. This classifier determines when a character in a word could be removed to create an abbreviation. The classifier is currently trained from a set of 1000 English words with 2-3 abbreviations for each word. Features in the maximum entropy-based model include neighboring character context, whether or not each character is a vowel or consonant, and how each character is positioned in the syllables of a word. Each word's abbreviations using this model are scored, ranked, and mapped to the corresponding word in a lookup table. They hope that this method can be a reasonable approach to predicting the correct word from an abbreviation without any sentence-level context.
Pennell evaluated the quality of the model by reversing the problem - determining the rate at which abbreviations from a test set corresponded to the correct English words in the lookup table that they generated. They achieved an accuracy of 58% when determining the corresponding word (this was only when the best abbreviation-word match was selected from the lookup table). When a test abbreviation was matched to one of the three best candidates, results increased to 75% accuracy. They expect that incorporating more context, such as word-level n-grams, will improve the model.
Pennell finds the most challenging part of her work to be that the "lingo" associated with text messages is "constantly changing". "It would be impossible to just provide a dictionary of all abbreviations and use that for translation," she says.
One growing challenge is the rapid growth of text messaging from smartphones, which often have full keyboard layouts. Although this may decrease the use of numbers associated with text messages (e.g., "any1" for "anyone"), Pennell believes this problem "won't go away completely". "One look at internet forums and chat rooms will tell you why; people use these abbreviations frequently,” she says. She adds that "we will continue to see deletion-based abbreviations and phonemic substitution-based abbreviations such as 'bcuz' for 'because' - not only because they are also common in chat rooms...but until unlimited texting plans are the norm".
Despite these challenges, there is a great deal of promise from this and related work. Not only will drivers be able to communicate more effectively with SMS when text messages are played back, but text messages will become accessible for a broader audience of users. "This technology can also be used for screen readers for the blind to enable them to better read forums, blogs and chat rooms," said Pennell.
For more information on this work, please see Pennell’s 2010 ICASSP paper. Related work can also be found by researchers at Microsoft Research who address the problem of composing text messages in the car.
Related work from MSR:
If you have comments, corrections, or additions to this article, please contact the author: Matthew Marge, mrma...@cs.cmu.edu.
SLTC Newsletter, May 2010
This article describes IBM TALES, a multi-lingual, multi-modal foreign news media monitoring research prototype system. TALES incorporates multiple natural language processing technologies from IBM, such as speech-to-text, machine translation, text-to-speech, information extraction, etc.
Modern communication technologies have made massive amounts of real-time news information in English and foreign languages readily available. This data takes the form of multilingual audio, video, and web content generated by broadcast media and social networking sites and is growing daily. This calls for effective, scalable, multilingual media monitoring and search solutions..
Several companies have developed systems based on Natural Language Processing (NLP) technologies to address the news monitoring task. Not only is it necessary for such a system to handle multimodal data, but also it must cross the language barrier, and process data with low latency. Here at IBM we made a big step toward this goal with the development of the Translingual Automatic Language Exploration System, codenamed TALES.
TALES is a news monitoring system that allows English-speaking users to monitor English and foreign-language news media in near real-time and search over stored content. TALES captures multilingual TV news broadcasts and crawls multilingual websites daily. The collected data is passed through a series of natural language processing engines to extract metadata. More specifically, for audio/video data, the following engines are applied:
When dealing with web data, TALES first detects the page language [9], and then processes it with engines in step 2), 4), and 7), omitting the audio/video-specific processing steps.
For end-users, TALES provides two ways to access the system:
In addition, TALES provides a web page translation tool named “TransBrowser” that allows end-users to seamlessly translate a web page and all its linked pages with perfect layout preservation, effectively enabling them to navigate foreign news websites as if they were in English. TransBrowser even allows the end-user to submit corrections to the machine translation to help improve the SMT engine.
TALES has been running 24x7 for about five years. At the moment it supports the following list of languages: English, Chinese (Simplified and Traditional), Modern Standard Arabic, Farsi, and Spanish. More languages are being added.
IBM is not the only company working on a news monitoring system. Examples of similar systems from other companies include BBN Technology’s Broadcast Monitoring System (BMS) [10], Autonomy’s Virage [11], Volicon’s Observer [12].
To summarize, TALES is a multilingual, multi-modal analytic system that lets English speakers collect, index and access information contained in English and foreign-languages news broadcasts and Websites. TALES technology is built on top of the IBM Unstructured Information Management Architecture (UIMA) [13] platform and uses multiple IBM natural language technology components. TALES enables users to search English and foreign-language news, play back streaming video with English closed captioning, monitor live video with low latency time, browse and translate foreign websites, etc. TALES has been deployed in multiple customer sites.
This work was partially supported by the Defense Advanced Research Projects Agency under contract No. HR0011-06-2-0001.
TALES Video Player with Dual-Caption Enabled
TALES Media Monitor, with a show being monitored
TALES Search UI with Embedded Video Player
![]()
TALES TransBrowser with Correction Mode
For more information, see:
Leiming Qian is a Senior Software Engineer at IBM T. J. Watson Research Center and the software architect for TALES. His interests are the application of Natural Lanuage Processing technology to solve real life problems.
Imed Zitouni conducts research on a variety of NLP problems at IBM T. J. Watson Research Center. His research interests include language understanding, information extraction and machine translation on speech and text.
SLTC Newsletter, April 2010
ASRU 2011 will be held Dec. 11 - 15, 2011 in Hawaii. Motivated by the success of ICASSP 2007 in Honolulu, and past ASRU workshops (St. Thomas, San Juan, Kyoto and Merano), we plan to provide attendees with a pleasant and informal setting that naturally generates interactions and close collaborations among researchers. Several venues in Hawaii are currently under consideration, including resorts in Big Island and Honolulu, with a decision on the exact location to be announced in May 2010. The dates have been chosen to accommodate Thanksgiving, Christmas and other holidays, and conferences such as NIPS, that ASRU attendees may wish to participate in. IBM has agreed to be a major sponsor.
As a scientific community, we hope to have participation from countries all over the world at ASRU 2011. In the article published in the February 2010 edition of the SLTC newsletter, it was observed that participation from Asia, Central and South America was low. We hope that the selected location will attract participants from not just those countries, but others as well.
We invite the community to send us their comments, thoughts, concerns and requests on what they would like to see in ASRU. (http://www.asru2011.org) We will do our best to accommodate every suggestion. A workshop is made successful by its participants and we hope to have record participation from researchers and students in academia and industry.
Stay tuned for more information!
Bhuvana Ramabhadran is with TJ Watson Lab, IBM Research.. Email: bhuvana@us.ibm.com.
SLTC Newsletter, April 2010
As research in language technology continues to develop, insights are contributed from interdisciplinary topics such as robotics and computer investigations into the evolution of language.
One researcher pursuing such directions is Luc Steels, Professor of Computer Science at the Free University of Brussels and Director of the Sony Computer Science Laboratory in Paris. His research takes a number of directions, generally using agent-based computer simulations, analytical models and experiments with robots [4] to investigate the development of the cognitive mechanisms needed to manage the complexities of language use. For example, he may use simulations to examine the ways in which a population of agents might self-organize a set of perceptually grounded categories, focusing on the specific example of categorization of colors [7].
"Language is an open system," he said in an interview conducted at IJCAI-09. "So it's always changing, always evolving. So we need to build adaptive language systems, as opposed to [developing] a database of examples, and applying some machine learning techniques to get a language system, and then you deploy it; this is how most systems are now built. But I think part of the reason why they don't work very well is because dialogue is really a matter of give and take. So all my research almost can be seen as a way to figure out how to do that."
The goal is a practical one: study ways in which robots and agents might learn and teach each other the various aspects of language [2]. For example, investigating the ways that robots could perform lexical acquisition using representations that link perception, body, action, and language [8], or studying issues that arise from embodient when conducting color-learning experiments with robots [1].
"So we're trying to understand very basic things like color or space or time or articles," Professor Steels said. "So I think we need to do a lot more basic research in this area to really go to the bottom of all these different surrounding domains, syntactic domains, and so that's what we are doing... I see our role more in delving deep, and then you realize actually how difficult it is, even if you take something as simple as color language, or language about space. Like, if you say left and right, you immediately get into issues of perspective reversal and how to express things with a minimal complexity, and robustness, and all those kinds of things. So I think what we do is basic research."
A useful tool in investigating these issues is the Fluid Construction Grammar [3]. "The idea of Fluid Construction Grammar is that the grammar is not fixed," said Professor Steels. "So the rules of the grammar are potentially changing at all times, so this means, among other things, that there's not a single way of doing things, there are always multiple possibilities which are stored in one agent, we always have a multi-agent system. So there are multiple possibilities and there's a preference, and so there's a score with every rule that's in your grammar, and these scores are being adapted as the agent is interacting [with other agents]. So in a sense it's a way of dealing with variation which is clearly there in a population of language users. So that's where the fluidity comes from. And also the fact that you can deal with ungrammatical sentences. So you're parsing not to check whether the sentence you read is grammatically correct, but you're parsing to get as much as you can out of the sentence.... And then you use the real world in your understanding process to come to an interpretation. And then once you do that, you can potentially get more feedback from the listener, or from the effect of the action that you execute as a consequence of what you said... So then you update, you change, you adjust the rules, you change the scores, you do lots of lots of things after every interaction."
Pursuing this and related research has led to advances and proposed future directions in some of the most fundamental questions in AI and natural language processing, such as investigating issues in meaningful symbols use [6], the social aspects of language use [5], and more.
For more information, see:
SLTC Newsletter, April 2010
Education is an important and compelling application domain for speech and language technologies. Early applications, such as spelling and grammar checkers and the use of compressed natural speech or synthetic speech in "talking" electronic reading books for children, were supplemented in the early 1990s by more sophisticated applications that exploited the most recent developments in automatic speech recognition technology. The applications fell into two main categories, second language learning, and reading, pronunciation and language tuition tools for children learning their first language. It is interesting to note that these applications pose significant challenges even for modern-day speech recognition technology, namely recognition of non-native and children's speech.
STiLL, the first ISCA (International Speech Communication Association) workshop on Speech Technology in Language Learning, was organized by the Department of Speech Music and Hearing at KTH Stockholm and held at Marholmen, Sweden, in May 1998. Of the forty six papers presented, 85% were concerned with second language learning, mainly for adults, and 15% addressed native language pronunciation, primarily for children. As the name implies, the emphasis of the workshop was on speech technology, with over 40% of the papers concerned with applications of automatic speech recognition, 13% with speech synthesis and 13% with visualisation. Only 5% of the papers addressed aspects of language or dialogue.
STiLL was followed in 2000 by inSTiL, held at the University of Abertay in Dundee, Scotland, and then by the InSTIL/ICALL 2004 Symposium on Computer Assisted Learning in Venice, Italy.
SLaTE, the ISCA special interest group on Speech and Language Technology in Education, was created at Interspeech 2006 in Pittsburgh. It is chaired by Maxine Eskenazi from Carnegie-Melon University. The group's name reflects the intention to embrace all applications of speech and language technologies in education, and not only language learning. SLaTE held its first workshop, SLaTE 2007, in Farmington, Pennsylvania, USA in October 2007. The workshop prompted a special issue of Speech Communication on Speech and Language Technology in Education (Speech Communication volume 51, issue 10, October 2009). The special issue includes a number of expanded versions of papers from SLaTE 2007.
SLaTE 2009 was held at Wroxall Abbey Estate, Warwickshire, England as an Interspeech 2009 satellite workshop. The workshop was truly international, attracting 70 delegates representing universities, companies and government organizations in 19 different countries. As in previous workshops, the majority of the papers and demonstrations were concerned with the application of speech and language technologies to language learning and reading tuition, with a significant number addressing automatic pronunciation assessment. However, as with the 2007 workshop, SLaTE 2009 saw a growing emphasis on dialogue systems, interactive games, and conversational agents for language learning, together with approaches to automatic generation of content for language learning applications. The SLaTE 2009 proceedings are accessible online.
In September 2010 SLaTE is co-organizing an Interspeech satellite workshop on "Second Language Studies: Acquisition, Learning, Education and Technology" in Tokyo, Japan. The third SLaTE workshop is scheduled to take place in 2011 in Venice, Italy.
Martin Russell is a Professor in the School of Electronic, Electrical & Computer Engineering at the University of Birmingham, UK. Labs Research. Email: m.j.russell@bham.ac.uk
SLTC Newsletter, April 2010
The 35th International Conference on Acoustics, Speech, and Signal Processing (ICASSP) was recently hosted in Dallas, Texas from March 14-19, 2010. The conference included lectures and poster sessions in a variety of speech and signal processing areas. In this article, some of the main acoustic modeling sessions at the conference are discussed in more detail.
Many interesting papers were presented in a special session on Direct Modeling. [1] discusses using long-span segment level features directly related acoustic properties to words. The paper compares two direct-model approaches to model these long span features, namely Flat Direct Models (FDMs) and Segmental CRFs (SCRFs). The authors find that both models show improvements over a standard baseline HMM system on the Bing Mobile voice-search database.
[2] introduces a discriminative model for speech recognition which jointly estimates acoustic, duration and language model parameters. Typically, language and acoustic models are estimated independently of each other. This results in acoustic models ignoring language cues and language models ignoring acoustic information. The authors find that jointly estimating acoustic, durational and language model parameters results in a 1.6% absolute improvement in WER on a large vocabulary GALE task.
The session "New Algorithms for ASR" featured many papers which explored new machine learning techniques for speech recognition applications. For example, [3] explores using Restricted Bolzmann Machines (RBMs) for phonetic recognition. RBMs are advantageous as they address the conditional independence assumption of Hidden Markov Models (HMMs). Specifically, they use a hidden state that collectively allows many different features to determine a specific output frame. The observations interact with the hidden features using an undirected model. On the TIMIT phonetic recognition task, the authors find that the RBM method offers a 0.6% absolute improvement PER over a conventional HMM system.
[4] explores digit recognition using point process models. Performance of HMM systems can degrade when noise conditions in test are unmatched from training. Point process models (PPMs) have been shown to more robustly detect keywords in noisy speech conditions. In this paper, digit recognition is performed via the following steps. First, the speech signal is transformed into a sparse set of acoustic events through time. Secondly, point process models of these events are used to hypothesizes possible digits. Finally, the sequence of hypothesized digits is reduced to a final hypothesis using a graph-based optimization method. On the Aurora 2 noisy digits task, the PPM model offers comparable performance to an HMM in clean speech but allows for significant improvements in noisy conditions.
Finally, subspace Gaussian Mixture Models (SGMM) was a popular topic in the acoustic modeling session ([5], [6]). In SGMMs, a common GMM structure is shared among all phonetic states. The means and weights of each state then vary in a subspace of the total parameter space. This allows for a much more compact representation of the acoustic model. Experiments on the English Callhome database in [5] indicate that compactly representing the acoustic model allows for improvements in WER over the standard GMM approach to acoustic modeling, and these gains continue to hold even after speaker adaptation is applied to the acoustic models. In addition [6] shows the benefit of SGMM for multilingual speech recognition. The traditional approach to multilingual recognition is to use a “universal phone set” covering multiple languages. In [6], phone sets from each language are treated distinctly but a SGMM method allows parameters of the models to be shared across multiple language. Absolute improvements in WER between 5%-10% are reported for the English, Spanish and German Callhome database.
For more information, please see:
[1] G. Zweig and P. Nguyen, "From Flat Direct Models to
Segmental-CRF Models," in Proc. ICASSP, 2010.
[2] M. Lehr and I.Shafran, "Discriminatively Estimated Joint Acoustic,
Duration, and Language Model for Speech Recognition," in Proc. ICASSP,
2010.
[3] A. Mohamed and G. Hinton, "Phone Recognition using
Restricted Boltzmann Machines," in Proc. ICASSP, 2010.
[4] A. Jansen and P. Niyogi, "Detection-Based
Speech Recognition with Sparse Point Process Models," in Proc. ICASSP, 2010.
[5] D. Povey et. al., "Subspace Gaussian Mixture Models for Speech
Recognition," in Proc. ICASSP, 2010.
[6] L. Burget et. al.,
"Multilingual Acoustic Modeling for Speech Recognition Based on Subspace
Gaussian Mixture Models," in Proc. ICASSP, 2010.
If you have comments, corrections, or additions to this article, please leave a comment below or contact the author: Tara Sainath, tsainath [at] us [dot] ibm [dot] com.
Tara Sainath is a Research Staff Member at IBM T.J. Watson Research Center in New York. Her research interests are in acoustic modeling. Email: tnsainat@us.ibm.com
SLTC Newsletter, April 2010
This article describes how the role of those professionals usually required to build commercial spoken dialog systems is changing in the dawning age of rigorously exploiting petabytes of data.
Commercial spoken dialog systems can process millions of calls per week producing considerable savings for the enterprises deploying them. Due to the high traffic hitting such applications, fluctuation of savings can be considerable with varying automation rates and call durations, two factors directly impacting the financial business model behind many commercial deployments. Accordingly, the main goals of system design, implementation, and tuning include the maximization of automation rate and minimization of average handling time, or a combination of those in a reward function.
Actions to drive system performance include tuning grammars, enhancing system functionality, rewording prompts, putting activities in a different order, etc. Traditionally, these actions are performed by speech scientists and interaction designers that implement changes according to best practices guidelines and their own long-standing experience. The impact of changes can be measured by comparing automation rates and handling times before and after the fact. To overcome the effects of performance variation due to external factors such as the caller population or the weekday up-and-down, a more precise comparison can be carried out by deploying both the baseline and the `improved' system at the same time and distributing the call mass between them. Data needs to be collected until the performance difference is found to be statistically significant.
Since the applications we are talking about in this article can be highly trafficked, statistical significance of the performance difference between two systems can normally be found after a relatively short period of time, so, there is nothing preventing us from exploring more than two systems at a time. In fact, one can implement a variety of changes at different points in the application and randomly choose one competitor every time the point is hit in the course of a call. This `contender' approach can be used to enlighten arbitrary uncertainties coming up during the design phase, as e.g. which prompt, which disambiguation strategy, which order, which grammar, which parameter setting is better. Based on observed performance differences and the amount of traffic hitting each contender condition, the call mass going to each of the conditions can be adjusted on an ongoing basis to optimize the overall reward of the application while awaiting statistically significant results.
Now, the contender approach can change the life of interaction designers and speech scientists in that best practices and experience-based decisions can be replaced by straight-forward implementation of every alternative one can think of. Is directed dialog best in this context? Or open prompt? Open prompt given an example? Or two? Or open prompt but offering a backup menu? Or a yes/no question followed by an open prompt when the caller says no? What are the best examples? How much time should I wait before I offer the backup menu? Which is the ideal confirmation threshold? What about the voice activity detection sensitivity? When should I time out? What is the best strategy following a no-match? Touch-tone in the first or only in the second no-match prompt? Or should I go directly to the backup menu after a no-match? What in the case of a time-out? Et cetera. Nobody needs to know the answer from one's gut feeling. Data will tell.
Contender (or what the research community also refers to as reinforcement learning) is only one of the many varieties of techniques one can use to optimize application performance based on massive amounts of available data. One can also study how likely a call will end up being escalated to an agent, and, upon reaching a certain threshold, one can escalate to keep non-successful calls as short as possible. Data will tell.
Also the duration of automated calls may be strongly reducible by reorganizing activities by their information gain measured on live data. We ask (and back-end-query) information items in the order of relevance which, in turn, minimizes the average number of gathered information items. Data will tell.
The never-ending headache of speech scientists how to overcome the omni-present weakness of speech recognition can also be healed by data. Instead of carefully tweaking rule-based grammars, user dictionaries, and confidence thresholds, there is a lazy but high-performing recipe. One needs to systematically collect large numbers of utterances from all the contexts of a spoken dialog system, transcribe these utterances, annotate them for their semantic meaning, and train statistical language models and classifiers to replace grammars that have been used in these recognition contexts before. The performance improvement can be predicted offline on separate test sets, and confidence thresholds can be tuned. Data will tell.
Using the above methods and other techniques exploiting production data of spoken dialog systems on a large scale, speech scientists and interaction designers are getting lazy and can spend more time at coffee breaks, Friday afternoon bashes, and Midtown skyscraper parties while servers are running hot doing our job.
David Suendermann is the principal speech scientist of SpeechCycle and focuses his research on spoken dialog systems, voice conversion, and machine learning. Email: david@speechcycle.com WWW: suendermann.com
SLTC Newsletter, April 2010
The AT&T Statistical Dialog Toolkit V1.0 is now available to the research community. This toolkit simplifies building statistical dialog systems, which maintain a distribution over multiple dialog states.
Recently, statistical approaches to spoken dialog systems have received increasing attention in the research community. Whereas conventional systems track a single hypothesis for the current dialog state, one of the main benefits of statistical dialog systems is that they maintain a distribution over a set of possible dialog states. This distribution can incorporate information and models not available to conventional dialog systems, including all of the entries on the ASR N-Best list, context-dependent models of user behavior, and prior personalized expectations of the user’s goals. This distribution has shown to yield gains in robustness to ASR errors when compared to conventional dialog systems [1,2,3].
Despite their promise, building statistical dialog systems remains challenging. A major problem is that there are no toolkits or frameworks currently available, so application developers must implement their own infrastructure from scratch. To move the field forward -- and to understand how to approach application development for statistical systems -- a toolkit is needed.
The AT&T Statistical Dialog Toolkit (ASDT) V1.0 aims to provide an accessible means to building dialog systems, which maintain a distribution over multiple dialog states. The core of the toolkit is a real-time belief update engine which maintains the distribution over a set of application-specific programmatic objects. The application developer creates these objects to suit their application; each object implements a small set of straightforward methods which the engine calls to update the distribution.
Each programmatic object represent a partition of one or more user goals. For example, in a tourist information domain, one partition object might represent all venues which are "NOT hotels"; another partition object might represent all venues which are "hotels near midtown"; another might represent all "hotels which NOT near midtown which are inexpensive". Partitions are sub-divided at run-time according to the ASR output. If the number of partitions grows too large, low-belief partitions are recombined to ensure that the update runs in real-time. The optimized update method employed by the engine is based on recent work described in [4], which draws on earlier work in [2] and [5].
In addition to the update engine, ASDT v1.0 also includes a large set of examples, illustrating off-line and simulation usage. The examples also provide an end-to-end voice dialer system, drawing on a database of 100,000 (fictitious) listings.
The toolkit and examples are written in standard Python. The provided end-to-end dialog system uses the in-the-cloud "AT&T Speech Mash-up Platform" for speech recognition and text-to-speech, obviating the need to install and configure ASR and TTS locally – only standard Python and common Python libraries are required. ASDT v1.0 is extensively documented, and uses standard mechanisms for configuration and logging.
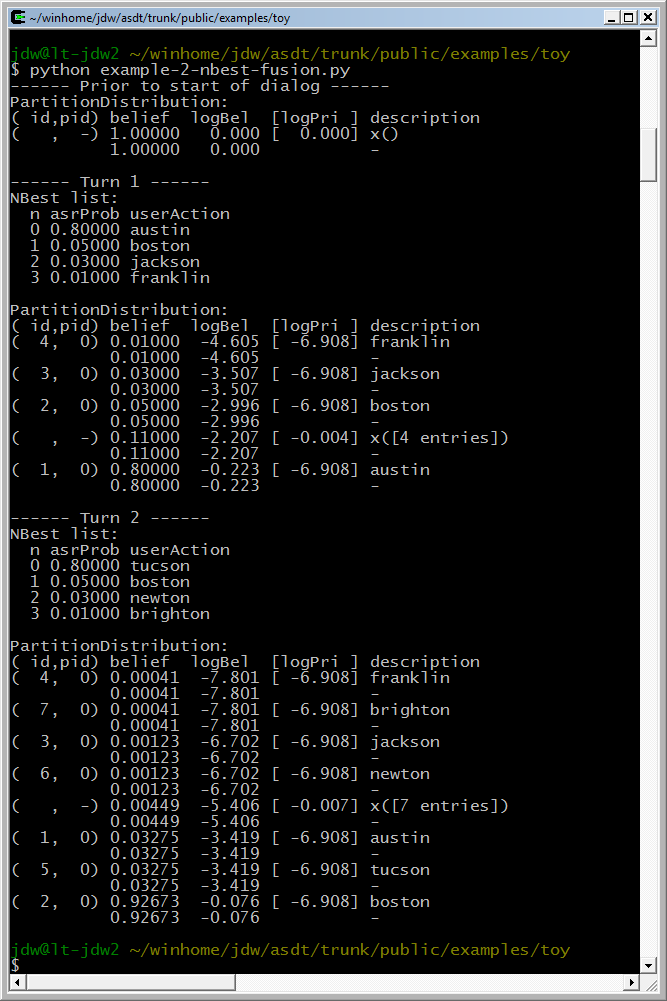
Figure 1: Example of tracking a dialog off line. The user says "Boston" twice. In each example, the ASR produces an N-Best list with the wrong hypothesis in the top position, and "Boston" further down the N-Best list. After the second recognition, "Boston" has the highest belief. This example shows how the statistical approach synthesizes together all the information on the N-Best list to arrive at the correct answer at the end of the dialog.
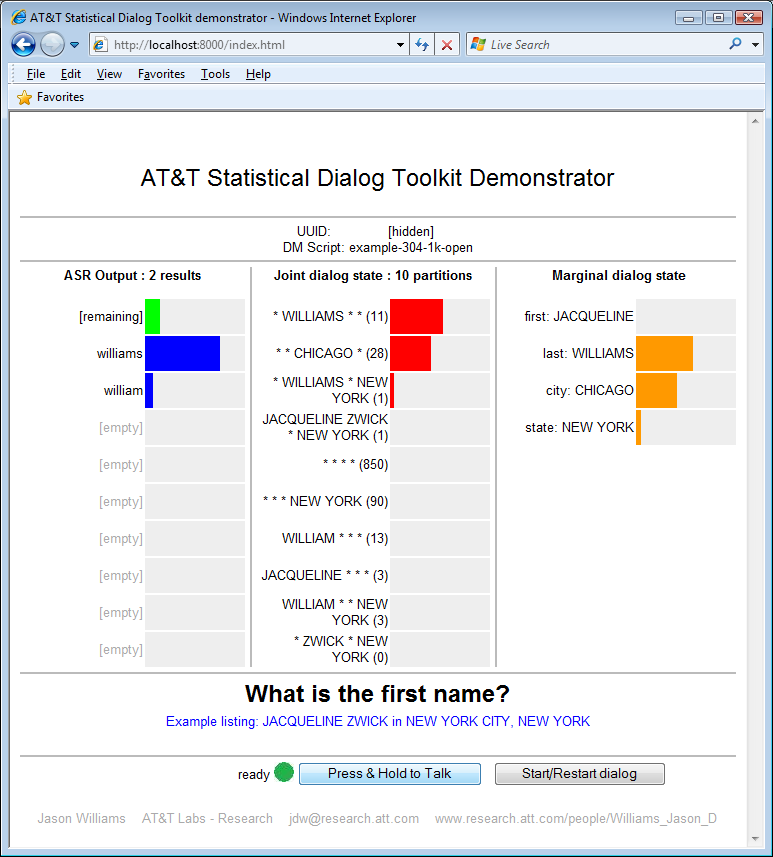
Figure 2: Screenshot of the end-to-end dialog system. The left column shows the ASR result. The center column shows the distribution over partitions – each partition corresponds to a python object. Each partition contains four fields – first name, last name, city, and state. Values which are not known are shown with '*'. The right column shows marginal belief in the most likely value for each field.
The source code of ASDT v1.0 is available for download under a non-commercial source code license from the following URL:
http://www.research.att.com/people/Williams_Jason_D/
This page also includes information on how to join an ASDT discussion list.
[1] H Higashinaka, M Nakano, and K Aikawa, "Corpus-based discourse understanding in spoken dialogue systems," in Proc ACL, Sapporo, 2003.
[2] SJ Young,M Gasic, S Keizer, F Mairesse, J Schatzmann, B Thomson, and K Yu, "The hidden information state model: a practical framework for POMDP-based spoken dialogue management," Computer Speech and Language, vol. 24, no. 2, pp. 150–174, April 2010.
[3] J Henderson and O Lemon, "Mixture model POMDPs for efficient handling of uncertainty in dialogue management," in Proc ACL-HLT, Columbus, Ohio, 2008.
[4] Jason D. Williams, "Incremental partition recombination for efficient tracking of multiple dialog states," Proc ICASSP, Dallas, Texas, USA, 2010.
[5] Steve Young, Jason D. Williams, Jost Schatzmann, Matthew Stuttle, and Karl Weilhammer, "The hidden information state approach to dialogue management," Cambridge University Engineering Department Technical Report CUED/F-INFENG/TR.544, 2006.
Jason D. Williams is Principal Member of Technical Staff at AT&T Labs - Research. His main research interests are spoken dialog systems, user modeling, and planning under uncertainty. Email: jdw@research.att.com.
SLTC Newsletter, April 2009
Question Generation (QG) is an interesting field of research which is only recently receiving the attention of researchers. QG is the process of automatically generating questions from text and is in many ways the inverse of Question Answering (QA). Given free text, the function of a QG system is to generate a question which relates to that text in some way.
Some generated questions might be answerable by the input text. Some deeper questions might not be explicitly answerable and may even lead to further questions. Work has already been done on classifying question types and describing taxonomies.[1,2]
QG can be beneficial for applications which interface with humans using dialogue, such as intelligent tutoring systems or other dialogue capable systems. Question Generation may be used to create questions for testing student's understanding of text or trigger a deeper understanding of a topic.
In contrast with Question Answering (QA), until recently QG has had a rather low profile in the natural language processing community. On the positive side, QG is making quick leaps forward, partly because of the shared foundations with QA that it can draw on.
A typical approach used by QA systems since the early years of the Text Retrieval Conference’s QA track is to automatically construct a search query from a question, use this query as an input for a search engine such as Google or Yahoo. A question answering system then automatically analyses snippets and documents returned by the search engine and finds specific sentences that are most likely to answer a given question. This approach relies on identification of the answer sentence template which would match sentences that answer the question.
Let's look at how the two fields are similar. To answer a question such as "When did Amtrak begin operations?" the QuALiM [3] QA system searched for sentences of the form "Amtrak began operations in ANSWER" or "In ANSWER, Amtrak began operations". Some of the current QG systems use the same principle albeit in reverse. For a sentence "Amtrak began operations in YEAR" a QG system may generate a WHEN question "When did Amtrak begin operations?"
Both QA and QG manipulate the sentences using syntactic and semantic information.
To encourage research in QG, two workshops on the subject have already been held [4]. The Intelligent Tutoring System (ITS) community has recognised the benefits of improving technology capable of generating questions and they have been enthusiastic participants. This year the Question Generation Shared Task Evaluation Challenge 2010 kicked off and participants are already engaged in two processing tasks with different scopes: single sentences and entire paragraphs.
For both tasks three data sources are used. These are the well known online encyclopedia Wikipedia, the social question answering site Yahoo! Answers and the Open University’s online educational resource, OpenLearn.
In the single sentence QA task, participants are given a single sentence and a target question type (e.g. WHO? WHEN? WHERE?). Participating systems generate a question of the target type from the input sentence. Typically we would expect to be able to answer the generated question from the input sentence but this is not an explicit requirement of the task. Here is one example from the single sentence QA task:
INPUT SENTENCE:
Abraham Lincoln (February 12, 1809 – April 15, 1865), the 16th President of the United States, successfully led his country through its greatest internal crisis, the American Civil War (1861 – 1865).
TARGET QUESTION TYPE: WHEN?
OUTPUT:
(1) In what year was Abraham Lincoln born
(2) In what year did the American Civil War commence?
The paragraph QA task provides a complete paragraph of free text. Participants’ systems are asked to generate six questions from each paragraph at three different levels of scope. Generated questions must relate to the entire paragraph, multiple sentences or single sentences (or less). The following instance shows the type of input and output expected from this task:
INPUT PARAGRAPH:
Abraham Lincoln (February 12, 1809 – April 15, 1865), the 16th President of the United States, successfully led his country through its greatest internal crisis, the American Civil War, preserving the Union and ending slavery. As an outspoken opponent of the expansion of slavery in the United States, Lincoln won the Republican Party nomination in 1860 and was elected president later that year. His tenure in office was occupied primarily with the defeat of the secessionist Confederate States of America in the American Civil War. He introduced measures that resulted in the abolition of slavery, issuing his Emancipation Proclamation in 1863 and promoting the passage of the Thirteenth Amendment to the Constitution. As the civil war was drawing to a close, Lincoln became the first American president to be assassinated.
OUTPUT:
(1) Who is Abraham Lincoln?
(2) What major measures did President Lincoln introduce?
(3) How did President Lincoln die?
(4) When was Abraham Lincoln elected president?
(5) When was President Lincoln assassinated?
(6) What party did Abraham Lincoln belong to?
The results of the challenge will be reported at the 3rd Workshop on Question Generation in June 2010.
The workshop invites the QG challenge participants as well as other researchers to present work pertaining to QG, including novel approaches, methods of evaluation, question taxonomies, data collection, and annotation schemes. The QG community is still growing and all interested parties are welcome to become involved and contribute in some way. It is an exciting and challenging field which brings together researchers from different areas such as question answering, natural language understanding and intelligent tutoring systems.
[1] A. Graesser, V. Rus, and Z. Cai Question classification schemes. Proceedings of the Workshop on the Question Generation Shared Task and Evaluation Challenge. (2008)
[2] Nielsen, R. D., Buckingham, J., Knoll, G., Marsh, B., & Palen, L. A taxonomy of questions for question generation. Proceedings of the Workshop on the Question Generation Shared Task and Evaluation Challenge. (2008)
[3] Kaisser, M. and Becker, T. Question Answering by Searching Large Corpora with Linguistic Methods, in Proc 13th TREC, NIST (2004)
[4] Rus, V. & Graesser, A.C. (Eds.). (2009). The Question Generation Shared Task and Evaluation Challenge. ISBN:978-0-615-27428-7.