Welcome to the Spring 2012 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter.
In this issue we are pleased to provide another installment of brief articles representing a diversity of views and backgrounds. This issue includes 7 articles from 7 guest contributors, and our own staff reporters and editors.
Starting with this issue, we revive the "Announcements" section, where we plan to include job changes and book announcements. Please email the editors with your non-commercial announcements.
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions. You can submit job postings here, and reach us at speechnewseds [at] listserv (dot) ieee [dot] org.
Finally, to subscribe the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Dilek Hakkani-Tür, Editor-in-chief
William Campbell, Editor
Patrick Nguyen, Editor
Martin Russell, Editor
Welcome to the next installment of the SLTC Newsletter of 2012. In this SLTC Chair update, I would like to spend a little time covering several related aspects on citations and impact which have come up based on (i) a proposal by ICASSP-2013 to move to a 5-page optional format, and (ii) trends from IEEE Trans. Audio, Speech and Language Processing and ICASSP papers.
RSR2015 (Robust Speaker Recognition 2015) is a new speech corpus for text-dependent robust speaker recognition.
The "Spoken Web Search" task of MediaEval 201 involved searching for audio content, within audio content, using an audio content query. The task required developing and optimizing a language-independent audio search system on very little available data.
The recent excitement around speech recognition caused by the popularity of Apple's Siri reminds me of the research atmosphere of a quarter century ago. In the late 1980s, a young CMU PhD student named Kai-Fu Lee revolutionized and revitalized the academic speech recognition world, which had been trying to break new ground since the early 1950s.
Popularity of voice interfaces on smartphones have been growing recently. As for most users typing on a phone is more laborious than typing on a full-size keyboard, voice interfaces serve a real practical purpose. This article overviews and compares several modern voice interfaces and smartphone apps for dialogue management and error handling approaches.
Deep Belief Networks (DBNs) have become a popular topic in the speech recognition community of late. In this article, we discuss in more detail work in deep belief networks from ICASSP.
Following on the tremendous success of ASRU 2011, the SPS-SLTC invites proposals to host the Automatic Speech Recognition and Understanding Workshop in 2013.
SLTC Newsletter, May 2012
Welcome to the next installment of the SLTC Newsletter of 2012. In this SLTC Chair update, I would like to spend a little time covering several related aspects on citations and impact which have come up based on (i) a proposal by ICASSP-2013 to move to a 5-page optional format, and (ii) trends from IEEE Trans. Audio, Speech and Language Processing and ICASSP papers.
In our field of signal processing, and in particular speech and language processing, there is an expectation that high quality research should appear and be recognized in both our premier conferences (for IEEE within the Signal Processing Society it is ICASSP - Inter. Conf. Acoustics, Speech, and Signal Processing) and journals (again, for speech and language researchers, that would be the IEEE Trans. on Audio, Speech and Language Processing). The notion of "impact factor" is something that has grown to be a symbol of the quality of a journals and conferences. As such, there is more interest within the IEEE Signal Processing Society to increase the impact factor of our journals and conferences. There is also an ongoing discussion as to the acceptance rate of papers being submitted to IEEE ICASSP, with the notion that a higher rejection rate means a higher quality conference (some of my colleagues in the Computer Science field have conferences that have an acceptance rate of 15-20%). This of course assumes that the quality of papers submitted to all conferences have a equivalent quality distribution, which of course is not the case (some even argue that their conferences are more prestigious because the acceptance rates of some conferences are lower than the acceptance rates of their journals - this argument is clearly flawed, since authors are generally able to self-select and not submit potential manuscripts to journals at the same rate and quality as what might be submitted to conferences). However, in this letter, I would prefer to focus on journal impact factor and not acceptance rate for conferences and leave that for another time.
So, here, I offer some comments on impact factor and citations. Let me be up front here to say, I am by no means an expert in this domain, and one only need to go to the various online search engines to find many publications on their effectiveness - or lack of effectiveness, of impact factors as a measure of quality, either of the journal, the papers appearing in those journals, or the authors of those papers.
So, where did this "impact factor" come from? In an article by Brumback [2], he notes that Eugene Garfield, who was an archivist/library scientist from Univ. of Penn., developed a metric that could be used to select journals to be included in a publication being considered called the "Genetics Citation Index"[1]. This Citation Index was the initial model for what is now known as the Science Citation Index, which it should be noted was commercialized by Garfield's company, named the Institute for Scientific Information (ISI) (as noted by Brumback[2]). As can be found in a number of locations on the web, this "impact factor" metric for journals is calculated "based on 2 elements: the numerator, which is the number of citations in the current year to any items published in a journal in the previous 2 years, and the denominator, which is the number of substantive articles (source items) published in the same 2 years."[2,3,4,5].
Unfortunately, as Seglen[3] points out, the journal impact factor has migrated into a singular rating metric that is being used to determine not just the value of particular journals, but also the quality of scientists, whether someone should be hired at a University - research laboratory or company, the quality of a University, or even the quality of the scientific research produced by an individual or research group. The impact factor is also being used by promotion committees in many universities, as well as "committees and governments in Europe and to a lesser extent in North America" in making decisions as to whether to award grants/contracts, as well as promotion and tenure for individual faculty/scientists.
It should be clear to signal processing researchers that evaluating scientific quality is a difficult problem which has no clear standard solution (in some sense, the medical field is ahead of engineering, since the debate on impact factor and criteria has been an open area of active discussion for many years) . In an ideal world, published scientific results would be assessed in terms of quality by true experts in the field and given independent quality as well as quantity scores which would be agreed according to an established set of rules. Instead, IEEE uses our peer review process based on review committees to assess the quality of a paper (i.e., the review process for ICASSP as well as for IEEE Transactions on ASLP papers). Of course when outside scientists seek to assess the impact of our publications, these assessments are generally performed by general committees who are not experts in speech and language processing, and will therefore resort to secondary criteria such as raw publication counts, perceived journal prestige, the reputation of particular authors and institutions. Again, as scientists and engineers, we generally seek a solution which is also has a scientific basis, is quantitative and repeatable, and ultimately removes as much subjective influence as possible. Unfortunately, the importance of a research field sometimes is associated with the impact factor generated by the journals in that sub-discipline, and can therefore wrongly skew the general public's impression on the importance of someone's research.
As noted in Wikipedia [5], the "impact factor is highly discipline-dependent". The percentage of total citations occurring in the first two years after publication varies highly among research areas, where for some, it is as low as 1-4% in areas like math and the physical sciences, while for biological sciences it can be as high as 5-8% [5]. A study by Chew, Villanueva, and Van Der Weyden [4] in 2007 considered the impact factor of seven medical journals over a 12-year period. They found that impact factors increased for the journals due to either (i) the numerators increasing, or (ii) the denominators decreasing (not surprising!) to varying degrees. They interviewed Journal Editors to explore why such trends were occurring, and a number of reasons were noted, which included deliberate editorial practices. So clearly, the impact factor is vulnerable to editorial manipulation at some level in many journals, and there is a clear dissatisfaction with it as the sole measure of journal quality. It clearly does not make sense to claim that all articles published in a journal are of similar quality, and even Garfield [1], who originated the impact factor, states that it is incorrect to judge an article by the impact factor of the journal.
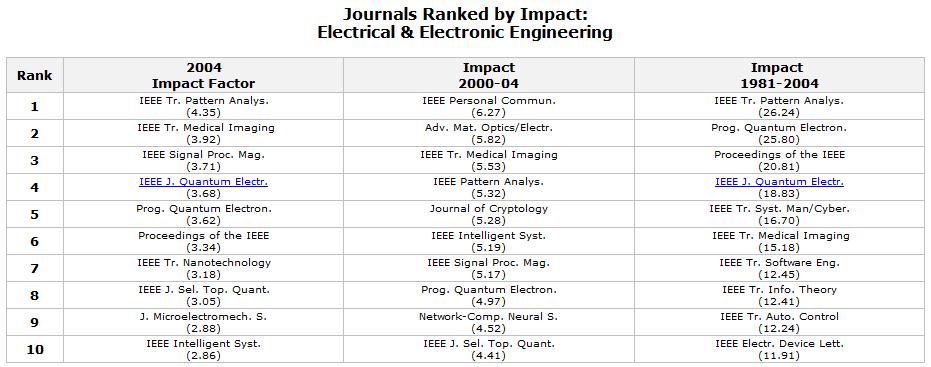
So where does that leave either IEEE ICASSP or IEEE ASLP (for those of us in Speech and Language Processing)? If one visits the IEEE Transactions on Audio, Speech and Language Processing website[6], you will see the impact factor is 1.668. A ranking of the top journals in electrical and electronic engineering [7] shows the following top 10 journals (in 2004), where the IF ranges from 2.86 to 4.35 for a single year. While the top 10 journals ranked by Impact in the area of Surgery by Sci-Bytes [8] range from 4.06 to 7.90. Still, the top 10 journals in the area of material science have impact factors from 4.88 to 20.85 [9].
[7] Journals Ranked by Impact Factor: Electrical & Electronic Engineering
http://www.in-cites.com/research/2006/january_30_2006-1.html
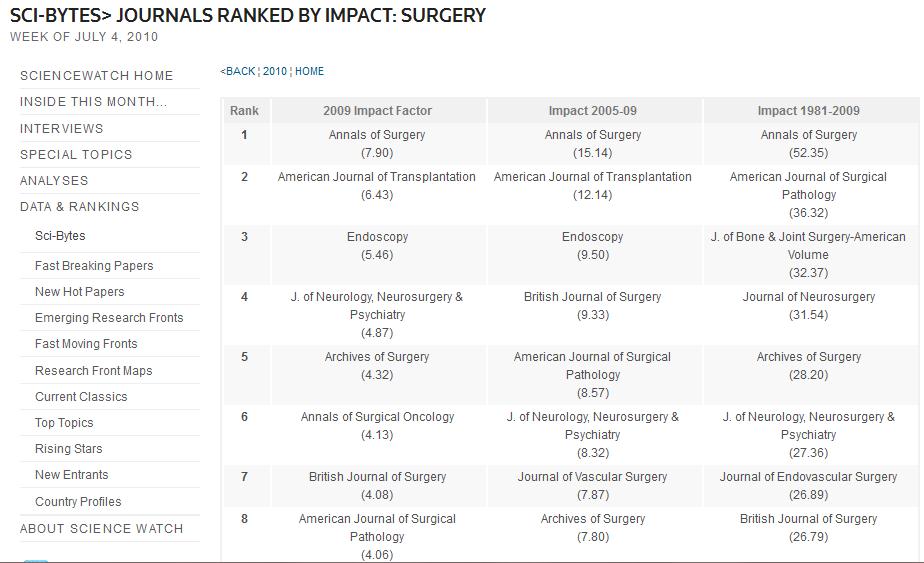
[8] Sci-Bytes> Journals Ranked by Impact: Surgery (Week of July 4, 2010); http://sciencewatch.com/dr/sci/10/jul4-10_2/
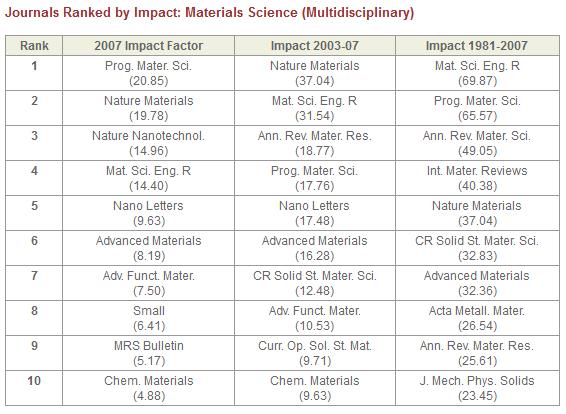
[9] Impact factor of journals in Material Science; http://sciencewatch.com/dr/sci/09/may24-09_1/
IEEE ICASSP-2012: So the reason for discussion on impact factor here stems from discussions at ICASSP-2012, and a proposal put forth by the IEEE ICASSP-2013 organizing committee. That proposal asked individual Technical Committees to consider allowing an optional 5th page to be added to the regular 4-page ICASSP paper, which has existed for +30 years. The proposal was suggested in order to increase the number of citations included in each ICASSP paper. You might be surprised to know that the number of citations per ICASSP paper has dropped from 5.8 (in 2006, with a total of 11020 citations) to 2.8 (in 2009, with a total of 5239 citations). Papers published in the ACL are 8 pages and averaged 16.6 citations per paper in 2009. Interestingly, the "shortness" of the citations is also limited to time as well, with most citations occurring recently, and fewer ICASSP authors citing seminal work from more than 2-3 years in the past (I realize this is a generalization, and simply suggest this is occurring but not across all papers). So, this proposal to increase the page count from 4 to 5 was considered by the SLTC and initially turned down, primarily due to the fact that the fundamental flaw here is not a lack of space, but an increasing trend for authors/researchers to commit less real-estate to their references.
At the SLTC meeting at ICASSP-2012, we renewed this discussion and came to the consensus that SLTC would support an optional 5-page format for ICASSP-2013, with the condition that (i) only references would be allowed on this 5th page (owing to the fact that Speech and Language Processing routinely receives about ¼ of the ICASSP submissions - generally around 700 papers to review, and we did not want to tax our expert reviewers further), and (ii) that the IEEE ICASSP Conference Paper template have a section before the final "Conclusions/Summary" section that is entitled "Relation to Previous Work". In this section, it is expected that authors should specifically point to prior work that has been done and to differentiate how their ICASSP contribution either builds on prior work or differentiates their work from prior studies. The SLTC believes this will better help address the problem of not relating the contributions to previous studies.
Finally, where possible, it is important to cite IEEE Transactions papers in place of, or in addition to, a previous ICASSP conference paper. If folks have any comments on this proposal, please let the SLTC know you opinions (or communicate them to your own Technical Committees within the IEEE Signal Processing Society if you focus on topics outside of speech and language processing).
In closing, we hope that everyone who attended IEEE ICASSP in Kyoto enjoyed the conference and came away with new ideas, new knowledge, new friends/colleagues, and new connections with other researchers/laboratories. I will say that I thoroughly enjoyed the conference and commend the outstanding organizational accomplishments of the ICASSP 2012 Organizing Committee (really a flawless superb meeting!) as well as CMS for their excellent handling of logistics (I have a saying that if "everything goes well, it just doesn't happen that way - someone really sweated the details and made sure everything would go smoothly"; the ICASSP-2012 Organizing Committee should be commended for an outstanding job!).
It is now May and only six more months until the next due date (November 19, 2012) for ICASSP-2013 in Vancouver, Canada (which takes place May 26-31, 2013)!
Best wishes…
John H.L. Hansen
May 2012
References:
[1] E. Garfield, "Journal impact factor: a brief review," CMAJ, vol. 161, pp. 979-980, 1999.
[2] R. Brumback, "Worshiping false idols: The impact factor dilemma," Journal of Child Neurology, Vol 23(4), pp. 365-367, Apr. 2008.
[3] P. Seglen, "Why the impact factor of journals should not be used for evaluating research," BMJ (British Medical Journal), 314.7079.497, 1997 (Published 15 February 1997)
[4] M. Chew, E.V. Villanueva, M.B. Van Der Weyden, "Life and times of the impact factor: retrospective analysis of trends for seven medical journals (1994-2005) and their Editors' views," JRSM: Journal of the Royal Society of Medicine, vol. 100 no. 3 142-150, March 2007.
[5] Wikipedia: Impact Factor. http://en.wikipedia.org/wiki/Impact_factor
[6] Website for IEEE Trans. Audio, Speech and Language Processing. http://www.signalprocessingsociety.org/publications/periodicals/taslp/
[7] Journals Ranked by Impact Factor: Electrical & Electronic Engineering http://www.in-cites.com/research/2006/january_30_2006-1.html
[8] Sci-Bytes> Journals Ranked by Impact: Surgery (Week of July 4, 2010); http://sciencewatch.com/dr/sci/10/jul4-10_2/
[9] Impact factor of journals in Material Science; http://sciencewatch.com/dr/sci/09/may24-09_1/
[10] IEEE ICASSP-2012: http://ieeeicassp.org/
John H.L. Hansen is Chair, Speech and Language Processing Technical Committee.
SLTC Newsletter, May 2012
RSR2015 (Robust Speaker Recognition 2015) is a new speech corpus for text-dependent robust speaker recognition. The current release includes 151 hours of short duration utterances spoken by 298 speakers. RSR2015 is developed by the Human Language Technology (HLT) department at Institute for Infocomm Research (I2R) in Singapore. http://hlt.i2r.a-star.edu.sg/ HLT@I2R has a long history of research in the areas of speech information processing and computational linguistics.
WHY ANOTHER CORPUS?
HLT@I2R participated in a smart home project, StarHome, that is located in Fusionopolis, Singapore. StarHome features voice automation in a smart home setup. It responds to home users' requests through an ergonomic vocal interface [1]. The combination of speech and speaker recognition offers a solution to both convenience and security. Text-dependent speaker recognition lies on the fringes of the mainstream speaker recognition, which has not been given much attention. As a result, the speech resources available for such research are either too small or inadequate. In view of the fact that user-customized command and control, that recognizes a user-defined voice command at the same time identifies the speaker, is a useful application scenario. RSR2015 is developed for the following objectives.
WHAT CAN WE DO WITH RSR2015?
RSR2015 allows for simulation and comparison of different use-cases in terms of phonetic content. For example, the most extreme constraint is to fix a unique utterance for all users of the system all the time. In the case where a larger set of fixed pass-phrases is shared across users, the scenario becomes very similar to user-customized command and control application. On the other hand, it is possible to limit the phonetic content of the speech utterance by randomly prompting sequences of phones or digits. In this case, the context of the phone varies across sessions and especially between enrolment and test.
The choice of a specific scenario depends on what constraints we would like to impose on the users. Unfortunately, no existing database allows for a comparison of speaker recognition engines across scenarios in similar conditions. RSR2015 is designed to bridge the gap. It consists of fixed pass-phrases, short commands and random digit series recorded in the same conditions.
DATABASE DESCRIPTION
RSR2015 contains audio recordings from 298 speakers, 142 female and 156 male in 9 sessions each, with a total of 151 hours of speech. The speakers were selected to be representative of the ethnic distribution of Singaporean population, with age ranging from 17 to 42.
The database was collected in office environment using six portable devices (four smartphones and two tablets) from different manufacturers. Each speaker was recorded using three different devices out of the six. The speaker was free to hold the smartphone or tablet in a comfortable way.
To facilitate the recording, a dialogue manager was implemented on the portable devices as an Android© application. The speakers interact with the dialogue manager through a touch screen to complete the recording. Each of the 9 sessions for a speaker is organized into 3 parts:
PART 1 - Short-sentences for pass-phrase style speaker verification (71 hours)
All speakers read the same 30 sentences from the TIMIT database [3] covering all English phones. The average duration of sentences is 3.2 seconds. Example: "Only lawyers love millionaires."
PART 2 - Short commands for user-customized command and control (45 hours)
All speakers read the same 30 commands designed for the StarHome applications. The average duration of short commands is 2 seconds. Example "Light on"
PART 3 - Random digit strings for speaker verification (35 hours)
All speakers read the same 3 10-digit strings, and 10 5-digit strings. The digit strings are session dependent.
BENCHMARKING
For ease of benchmarking across systems, RSR2015 database comes with several evaluation protocols targeting at different scenarios, an example of which is given in [4] showing a way of splitting the database for background training, development and evaluation.
WHERE TO GET THIS DATABASE?
Please contact Dr Anthony Larcher at Email alarcher [at] i2r.a-star.edu.sg or Dr Kong-Aik Lee at kalee [at] i2r.a-star.edu.sg.
REFERENCES:
[1] K. A. Lee, A. Larcher, H. Thai, B. Ma and H. Li, "Joint Application of Speech and Speaker Recognition for Automation and Security in Smart Home", In Interspeech, 2011, pp 3317-3318.
[2] A. Larcher, P.-M. Bousquet, K. A. Lee, D. Matrouf, H. Li and J.-F. Bonastre, "I-vectors in the context of phonetically-constrained short utterances for speaker verification", In ICASSP 2012.
[3] W. M. Fisher, G. R. Doddington and K. M. Goudie-Marshall, "The DARPA speech recognition research database: specifications and status", DARPA Workshop on Speech Recognition, 1986, pp. 93-99
[4] A. Larcher, K. A. Lee, B. Ma and H. Li, "RSR2015: Database for Text-Dependent Speaker Verification using Multiple Pass-Phrases", submitted to Interspeech 2012
Anthony Larcher is Research Staff in Human Language Technology Department at Institute for Infocomm Research. His interests are mainly in speaker and language recognition.
Haizhou Li is the Head of Human Language Technology Department at Institute for Infocomm Research. His research interests are speech processing and computational linguistics.
SLTC Newsletter, May 2012
Recently, there has been great interest in algorithms that allow rapid and robust development of speech technology for any language, with a particular focus on search and retrieval. Today's technology was mostly developed for transcription of English, and still covers only a small subset of the world's languages, often with markedly lower performance. A key reason is that it is often impractical to collect a sufficient amount of data under well-defined conditions for current state-of-the-art techniques to work well. The "Spoken Web Search" task attempts to provide an evaluation corpus and baseline for research on language-independent search (as a precursor to transcription) of real-world speech data, with a special focus on low-resource languages, and to provide a forum for original research ideas. The goal is to compare "mainstream" speech recognition, porting existing tools and resources to these new tasks, to "zero-knowledge" approaches, which attempt to directly match signals and patterns without relying on knowledge transfer, under a variety of conditions.
MediaEval [7] is a benchmarking initiative dedicated to evaluating new algorithms for multimedia access and retrieval. It emphasizes the "multi" in multimedia and focuses on human and social aspects of multimedia tasks.
The "Spoken Web Search" task of MediaEval 2011 [4, 5] involved searching for audio content, within audio content, using an audio content query. By design, the total dataset consisted of only 700 utterances (less than 3h) of telephony quality from four Indian languages (English, Gujarati, Hindi, Telugu), without language labels. The data has been collected by IBM Research India, as part of the "Spoken Web" effort [2, 3], which attempts to develop an Internet-like tool for low-literate users who have no access to smart-phones. In this scenario, users would be able to navigate voice web-pages (essentially voice messages) using voice, on low-spec mobile phones, in their local language or dialect, without relying on a dedicated speech dialog system and the associated infrastructure. The task therefore requires researchers to build a language-independent audio search system so that, given a query, it should be able to find the appropriate audio file(s) and the (approximate) location of query term within the audio file(s). Performing language identification, followed by standard speech-to-text is not appropriate, because recognizers are typically not available in these languages, or even dialects. Evaluation was performed using standard NIST metrics for spoken term detection, such as ATWV (Average Term Weighted Value) which computes an average weighted combination of missed detections and false alarms across all search terms [1].
In the 2011 evaluation, two "zero-knowledge" approaches trained only on the available data were submitted, while two sites submitted phone-based systems, which leveraged additional information. One site submitted an articulatory-feature-based approach, which also leveraged additional audio data, processing it in a language independent way. The results are described and summarily analyzed in [5]. While using a very small data-set, three approaches achieved maximal ATWVs of 0.1 or greater on the development data, detecting about 15% of events, with very low false alarm probabilities, as required by the chosen parameterization of ATWV. The same three approaches could be run successfully on the unseen evaluation data, and the choice of decision thresholds proved to be remarkably stable, given the little amount of available data.
In the evaluation, a pattern-matching based query-by-example approach generalized best to unseen data, while the phone-based approaches achieved an identical performance on the evaluation data as on the development data. It is interesting to note that under the given conditions, the zero-knowledge approaches could slightly outperform the phone-based approaches, which relied on the availability of matching data from other languages. Follow-up work on larger datasets will be required to investigate the scalability of these systems.
These initial numbers on a very low-resource spoken term detection task represent encouraging results. It is interesting to note that very diverse approaches could achieve very similar results, and future work should include more evaluation criteria, such as amount of external data used, processing time(s), etc., which were deliberately left unrestricted in this evaluation, to encourage participation. With respect to the amount of data available, this evaluation was even more challenging than the goals set by current research programs, yet results have been achieved that appear useful in the context of the "Spoken Web" or similar tasks, particularly if the alternative is to have no solution at all.
To our knowledge, this work is the first evaluation of its kind, and would work for languages or dialects that may not even have a written form. A follow-up evaluation with additional languages [6] will be performed in conjunction with the MediaEval 2012 workshop, which will be held in Pisa in October 2012. For further information, and to sign up (until May 31st, 2012), please refer to [7], or contact the organizers.
References
[1] J. Fiscus, J. Ajot, J. Garofolo, and G. Doddington, "Results of the 2006 spoken term detection evaluation," in Proc. SSCS, Amsterdam; Netherlands, 2007.
[2] A. Kumar, N. Rajput, D. Chakraborty, S. K. Agarwal, and A. A. Nanavati, "WWTW: The world wide telecom web," in NSDR 2007 (SIGCOMM workshop), Kyoto, Japan, Aug. 2007.
[3] M. Diao, S. Mukherjea, N. Rajput, and K. Srivastava, "Faceted search and browsing of audio content on spoken web," in Proc. CIKM, 2010.
[4] N. Rajput and F. Metze, "Spoken web search," In Proc. MediaEval 2011 Workshop, Pisa, Italy, Sept. 2011.
[5] F. Metze, N. Rajput, X. Anguera, M. Davel, G. Gravier, C. van Heerden, G. V. Mantena, A. Muscariello, K. Prahallad, I. Szöke, and J. Tejedor. The spoken web search task at MediaEval 2011. In Proc. ICASSP, Kyoto; Japan, March 2012. IEEE.
[6] E. Barnard, M. Davel, and C. van Heerden, "ASR corpus design for resource-scarce languages," in Proc. INTERSPEECH, Brighton; UK, Sept. 2009, ISCA.
[7] http://www.multimediaeval.org/
Florian Metze is Research Faculty at Carnegie Mellon University's Language Technologies Institute. His interests are mainly in acoustic modeling, user interfaces, and multi-media analysis.
SLTC Newsletter, May 2012
The recent excitement around speech recognition caused by the popularity of Apple's Siri reminds me of the research atmosphere of a quarter century ago. In the late 1980s, a young CMU PhD student named Kai-Fu Lee revolutionized and revitalized the academic speech recognition world, which had been trying to break new ground since the early 1950s. At the time, we - the speech research community - were disappointed by the slow progress of speech recognition and disillusioned about its possible evolution into mainstream technology. Kai-Fu invented nothing new, nothing that shifted any paradigms. Rather, he patiently and with obsessive determination revised all that had been done by researchers around the world, and combined the most successful ideas into something that showed the highest performance ever, at least for the limited common test available at the time-the DARPA Resource Management Task. Kai-Fu's was a work of engineering at its best: he integrated and compared, for the first time on the very same test set, dozens of different small improvements and showed everyone in the academic and industrial research communities that high-performance speech recognition was indeed possible. Kai-Fu earned his degree and then moved on to a successful career that included key positions at Apple, Microsoft, and Google. Speech recognition researchers around the world started following Kay-Fu's speech recognition approach, and soon the race for better and better speech recognition was on again, with new project challenges and new researchers taking those challenges on. Soon, the quality of speech recognition performance rose as researchers built upon each other's work and compared their results on common tests. Startups like SpeechWorks and Nuance appeared on the scene, and the rest is history. I call this the "Kai-Fu effect." Often technology evolves not because of anything profoundly new, but because someone, by standing on the shoulders of giants, makes things work in the right place and at the right time.
The interest in speech research caused by the release of Siri, the speech recognition assistant introduced by Apple with the new iPhone 4S last October s an example of the Kai-Fu effect. My opinion--Siri people, please correct me if I am wrong--is that there is nothing new in Siri, nothing really groundbreaking. It uses a state-of-the-art commercial speech recognition deployed "in the cloud," the result of the evolution of HMMs developed in the late 1970s (it takes little imagination to identify which recognizer they are using). In addition to speech recognition, Siri uses some form of semantic parsing. I imagine it requires a good amount of manual labor to keep this updated and to improve its performance against the huge amount of log data generated by the users. Is this new? Some of us could argue that we have been doing this for decades, building systems that more or less successfully could graciously answer questions like "What's playing at the movie theaters around here" and "Show me the flights from New York to San Francisco next Monday in the afternoon." But we did not build Siri.
Siri is popular partially because it is a high-quality product- a decently accurate recognizer and very sleek interface beautifully integrated into an extremely popular device with panache (try saying, "I hate you, Siri") - but more importantly, it was released at the right time. Google's voice search and all other mobile voice applications (Vlingo and Bing, to name a few), paved the way for Siri by conditioning us to the idea of talking to a smartphone. And again, the idea of "talking" to a mobile device is not new. Many prototypes of multimodal wireless interaction were built in the late 1990s and early 2000s, but the mobile devices at that time were slow and expensive, the wireless data network almost non-existent, and Web services, like flight and restaurant reservations, less pervasive than they are now. While the technology was there, Siri could not have been a reality for millions of consumers. Siri could not have existed as a mass phenomenon.
I don't have an iPhone 4S (yet). I am not an early adopter; I would say I lag at the end of the early majority, just a tad away from the late majority. But the quality of its engineering and its potential were obvious to me when I tried Siri and the iPhone 4S while having dinner with one of my early adopter friends a few months ago. I have been in speech recognition for nearly 30 years, and it is the first time I can clearly see that speech recognition may be here to stay. Thanks to Siri, thanks to Apple, and thanks to Steve Jobs's vision, speech recognition is hot again. That success, however, comes with risks. Now speech recognition has really been exposed to everyone, and people seem to like it; this is a far cry from the public reaction to the much dreaded "Your call is important to us. Please tell me the reason you are calling about" IVRs. Speech recognition and understanding is causing a lot of excitement and making a lot of promises. If Apple, Google, and everyone who is contributing to the mass adoption of speech technology, at the commercial and at the research level, do not keep the promises made by the current applications and the increasing market expectations, we may fall back again into a long speech recognition winter, but this time it will take longer for spring to come again.
Roberto Pieraccini is the director of International Computer Science Institute (ICSI), Berkeley. Email: roberto[at]icsi[dot]berkeley[dot]edu
SLTC Newsletter, May 2012
Popularity of voice interfaces on smartphones have been growing recently. As for most users typing on a phone is more laborious than typing on a full-size keyboard, voice interfaces serve a real practical purpose. This article overviews and compares several modern voice interfaces and smartphone apps for dialogue management and error handling approaches.
Voice interfaces have gained public recognition since the release of Siri on i-phone. Siri's popularity is an exciting development for speech technologies. Many voice interfaces with functionalities similar to Siri's are also available on Android smartphones, including Google's Voice Search, SpeakToIt assistant, Vlingo Assistant, Jeannie, and Eva. Android Search interfaces that focus exclusively on search functions include Dragon and Bing search. We compared several of the interfaces in an attempt to determine what makes a voice app appealing to a user.
While users are delighted and entertained to ask an app about the meaning of life (see [1]), it is not the main purpose of a voice interface. Voice interfaces help users perform functions such as sending an email or a text message, playing a song from a music library, accessing calendar, performing a web search, or checking weather forecast.
The interfaces differ in the functions that they support, modality of communication, text-to-speech and recognition components, amount of initiative taken by the system, and dialogue handling methods. Virtual assistant voice interfaces take a role of a personal assistant, in some cases with a graphical virtual character:
SpeakToit: 

Eva/Evan:


These interfaces attempt to support functions of a virtual secretary who can take notes, make reminders, and send messages in addition to web search functions.
Mute assistants
Some of the voice interfaces take a role of mute and passive assistants (Voice Search and Vlingo assistant). These interfaces accept speech as input but do not speak back. They communicate to a user using graphical interfaces and sound effects. These interfaces are fully user-initiative, never asking "what can I do for you?" or starting to speak in the middle of a meeting. They run low risk of annoying a user but they also do not appear as "intelligent" as Siri. Graphics-only output works well only when you can see the screen. If you are trying to use an interface while driving or walking, speaking becomes an important capability for a voice interface system.
Speaking assistants
Siri, SpeakToIt assistant, and Eva/Evan apps speak back to a user. These systems take more initiative than mute assistants. They address the user by name and exhibit emotions both in a choice of a spoken response and in a facial expression. SpeakToIt assistant shows happiness when it is turned on by saying "Good to see you again", apologizes when they do not understand or is unable to handle a command "I am sorry I'm not able to do that just yet but I will be soon". When i-phone loses network connection, Siri (which relies on the connection) responds with error messages, such as "There is something wrong", "I cannot answer you now". These responses sound very cute and human-like and give an impression that the app has a personality, however more helpful responses "Network is down, try again later" or "Try turning on your wireless connection", would reveal the problem to a user or suggest a solution.
 Quality of TTS makes a big difference for the perceived quality of a voice app. Neither of the mechanical voices used by the free versions of Android systems compares to affective Siri's voice.
SpeakToIt and Eva assistants also have a graphical persona. A character in SpeakToIt assistant app has a customizable appearance and displays subtle facial expressions during communication. However, it is not clear how much this adds to the system's functionality.
Quality of TTS makes a big difference for the perceived quality of a voice app. Neither of the mechanical voices used by the free versions of Android systems compares to affective Siri's voice.
SpeakToIt and Eva assistants also have a graphical persona. A character in SpeakToIt assistant app has a customizable appearance and displays subtle facial expressions during communication. However, it is not clear how much this adds to the system's functionality.
Voice search interfaces
Other types of apps, such as Dragon and Bing specialize on search only. These interfaces are not attempting to be 'can-do-all' assistants. Instead, they have a focused set of functions relevant to search. Bing has a pre-set list of search types: images, videos, maps, local, etc. We found this helpful because it suggests to a user which functionalities are supported by the system. Dragon, on the other hand, provides a speaking-only interface equivalent to 'how may I help you'. A user can guess by trial and error what the system capabilities are.
Error handling is a necessary function for a voice interface. Even in quiet conditions systems are bound to occasionally misrecognize user's speech.
We performed a test where we looked at error handling capabilities of several voice interfaces. In this comparison we were looking at the system's strategies at error handling and not the quality of speech recognition so we simulated the same error in each system.
Voice search is a useful tool, but what happens when a search query is misrecognized? To test voice web search interfaces error handling capabilities, we asked Voice Search, SpeakToIt Assistant, Siri, and Bing `Find hotels in Lisbon', mispronouncing Lisbon slightly to induce recognition failure. In some cases, the Voice Search app provides alternative ASR hypotheses for the search command and allows the user to choose one of them. However, in our experiment, Lisbon was not one of them. In other cases (when the system is more confident of its hypothesis) Voice Search simply proceeds to search using the incorrectly recognized ASR string, presenting the irrelevant search results without indicating what it has used for the actual search string. Neither of these strategies is optimal: if the correct word is not in the list of provided alternatives or if the system does not recognize its own error, the user must start over by speaking the entire message or type a correction. The most unpleasant part about this interface is that a user cannot even see which string was searched.
SpeakToIt Assistant exhibits a similar lack of effective error-recovery options, simply returning a map with search results for its top (incorrect) hypothesis. While the GUI does allow the user to correct the incorrectly recognized string by typing, no voice alternative is provided.
At first Siri responds to "find hotels" query "I am sorry, I can not do that" because it does not match its set of capabilities. In order to do a web search, a user has to prefix their search with "web search" . With its results to an incorrectly recognized web search query, Siri, similarly to android apps, is unhelpful: when she misrecognizes a location in our hotel query, she also returns a search result with the hotels at the incorrect location.
We found bing's error-handling more graceful than the other interfaces. It showed the search string and allowed user to edit the search string using a combination of GUI and speech. For example, a user can erase a misrecognized part of the utterance and either type or record a new phrase.
"Siri gave me hope -- a feeling that we were truly jumping into the future, where a voice on a mobile computer could help me in almost any way" says Jordan Crook in a mostly critical review of Siri's functionality [2]. Interestingly, users of Siri unanimously refer to the program affectively as a she and not it.
What makes a user perceive system as intelligent? Subjective characteristics play an important role in user perception: such as witty and varied responses, personalized addressing to a user, quality of TTS and affective intonation. Objective characteristics that affect a user's perception, besides quality of speech recognition, include the ability of the system to communicate to a user what the system capabilities are, effective error detection and handling. Voice interfaces that take initiative can be perceived as more intelligent, however taking initiative also means taking a risk of annoying a user with an unnecessary question or request. The new popularity of voice interfaces on smartphones is an exciting opportunity that can drive advances in dialogue research.
Only free versions of the Android apps were assessed here. Also, we did not have access to an icecream sandwich with its new voice capabilities. Voice Answer is another i-phone app that we have not looked at in this article [3].
For more information, see:
[1] Funny answers from Siri, maindevice.com
[2] Siri, Why Are You So Underwhelming?, Review of Siri by Jordan Crook, Techcrunch
[3] Another Siri-Like App Review of Voice Answer (Sparkling Apps, Netherlands) by Ingred Lunden, Techcrunch
If you have comments, corrections, or additions to this article, please contact the author: Svetlana Stoyanchev, sstoyanchev [at] cs [dot] columbia [dot] edu.
Svetlana Stoyanchev is a Postdoctoral Research Fellow at Columbia University. Her interests are in error handling and information presentation in spoken dialogue.
SLTC Newsletter, May 2012
The International Conference on Acoustic, Audio and Signal Processing (ICASSP) was recently hosted in Kyoto, Japan from March 25-30, 2012. Deep Belief Networks (DBNs) have become a popular topic in the speech recognition community of late, for example showing an improvement of over 30% relative on a Switchboard telephony task [1] compared to a baseline Gaussian Mixture Model/Hidden Markov Model (GMM-HMM) system, a common approach used in acoustic modeling. In this article, we discuss in more detail work in deep belief networks from ICASSP. Specifically, this article highlights 2 categories of DBN research, namely ideas on improving training/decoding speech and alternative neural network architectures.
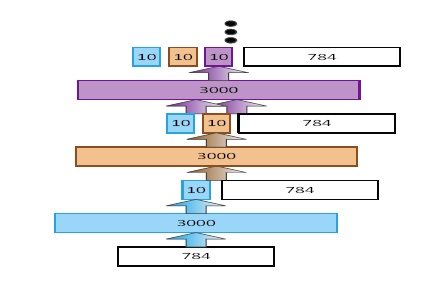
DBN training is typically performed serially via stochastic gradient descent. It is often slow and difficult to parallelize. [2] explores learning complex functions from large data sets that can be parallelizable, through an architecture called Deep Stacking Network (DSN). Figure 1 shows the typical architecture for a DSN. Each module of a DSN consists of 3 layers, an input layer, a weight + non-linearity layer, and then a linear output layer. The paper describes a convex-optimization formulation to efficiently learn the weights of one DSN module. After one module is finished training, the output from the last module plus the input features are given as input to the next module. DSN performance on the TIMIT phone recognition task is around 24%, compared to a PER of 21-22% for a DBN. However, given the efficiency of training and the large gains DBNs show over GMM/HMM systems, this method certainly seems like a promising approach.
 |
[3] explores enforcing random parameter sparseness during DBN training as a soft regularization and convex constraint optimization problems. The authors also propose a novel data structure to take advantage of the sparsity. The proposed methodology was evaluated on both a Switchboard and Voice-Search task, decreasing the number of nonzero connections to 1/3 and building a more generalized model with a reduced word error rate (WER) by 0.2-0.3% absolute compared to fully connected model on both datasets. Furthermore, the error rate can match the fully connected model by further reducing the non-zero connection to only 12% and 19% on the two respective datasets. Under these conditions, the model size can be reduced to 18% and 29%, and decoding speech improved by 14% and 23%, respectively, on these two datasets.
[4] introduces a sequential DBN (SDBN) to model long-range dependencies between concurrent frames by allowing for temporal dependencies between hidden layers. The paper presents pre-training and fine-tuning backpropagation derivations for this model. Experiments on TIMIT show that a simple monophone SDBN system compares favorably to a more complex context-dependent GMM/HMM system. In addition, the number of parameters of the SDBN is much smaller than a regular DBN. Given that DBN training is computationally expensive, reducing parameters is one approach to speed up training.
[5] explores using convolutional neural networks (CNN), which have generally been explored for computer vision tasks, to speech recognition tasks. A convolutional neural network (CNN), is a type of NN which tries to model local regions in the input space. This is achieved by applying a local set of filters to process small local parts of the input space. These filters are replicated across all regions of the input space. The idea of local filters is to extract elementary features such as edges, corners, etc from different parts of the image. Because different features are necessary to extract, a feature map is used to allow for different types of features. All units within one feature map perform the same operation on different parts of the image. After a set of local filters processes the input, a max-pooling layer performs local averaging and subsampling to reduce the resolution of the feature map, and reduce sensitivity of the output to shifts and distortions. A CNN is typically comprised of multiple layers, which alternates between convolution and subsampling. The authors show that the proposed CNN method can achieve over 10% relative error reduction in the core TIMIT test set when comparing with a regular DBN using the same number of hidden layers and weights.
[6] analyzes why the performance of DBNs has been so promising in speech recognition. The authors argue that DBNs perform well for three reasons, namely DBNs are a type of neural network which can be fine-tuned, DBNs have many non-linear hidden layers, and finally DBNs are generatively pre-trained to make the fine-tuning optimization easier. This paper shows experimentally through results on the TIMIT phone recognition task, why each of these aspects improves DBN performance. Furthermore, the authors also show through dimensionally reduced visualization of the relationships between the feature vectors learned by the DBNs that the similarity structure of the feature vectors at multiple scales is preserved, visually illustrating the benefits of DBNs.
[1] F. Seide, G. Li, X. Chen, D. Yu, "Feature Engineering In Context-Dependent Deep Neural Networks For Conversational Speech Transcription," in Proc. ASRU, December 2011.
[2] L. Deng, D. Yu and J. Platt, “Scalable Stacking and Learning For Building,” in Proc. ICASSP, 2012
[3] D. Yu, F. Seide, G. Li and L. Deng, "Exploiting Sparseness In Deep Neural Networks For Large Vocabulary Speech Recognition", in Proc. ICASSP 2012.
[4] A. Galen and J. Bilmes,“Sequential Deep Belief Networks,” in Proc. ICASSP, 2012
[5] O. Abdel-Hamin, A. Mohamed, H. Jiang and G. Penn, "Applying Convolutional Neural Networks Concepts to Hybrid NN-HMM Model for Speech Recognition," in Proc. ICASSP, 2012.
[6] A. Mohamed, G. Hinton and G. Penn, "Understanding How Deep Belief Networks Perform Acoustic Modeling," in Proc ICASSP, 2012.
If you have comments, corrections, or additions to this article, please contact the author: Tara Sainath, tsainath [at] us [dot] ibm [dot] com.
Tara Sainath is a Research Staff Member at IBM T.J. Watson Research Center in New York. Her research interests are mainly in acoustic modeling. Email: tsainath@us.ibm.com
SLTC Newsletter, May 2012
Following on the tremendous success of ASRU 2011, the SPS-SLTC invites proposals to host the Automatic Speech Recognition and Understanding Workshop in 2013. Past ASRU workshops have fostered a collegiate atmosphere through a thoughtful selection of venues, thus offering a unique opportunity for researchers to interact.
The proposal should include the information outlined below.
If you would like to be the organizer(s) of ASRU 2013, please send the Workshop Sub-Committee a draft proposal before July 1, 2012. (Point of contact: gzweig@microsoft.com). Proposals will be evaluated by the SPS SLTC, with a decision expected in September.
The organizers of the ASRU workshop do not have to be SLTC members, and we encourage submissions from all potential organizers. So we encourage you to distribute this call for proposals far and wide to invite members of the speech and language community at large to submit a proposal to organize the next ASRU workshop.
For more information on the most recent workshops, please see: