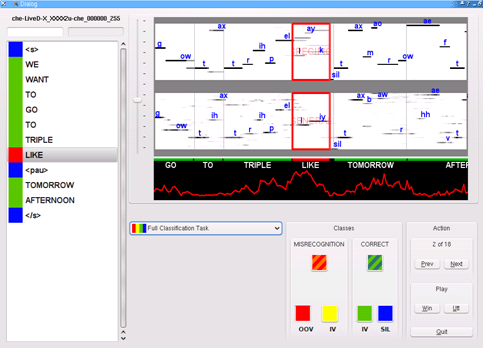
Visualization of posteriors from strongly and weakly constrained systems, and
OOV detection. This example shows the OOV word "Tripoli" recognized as "triple
like".
Welcome to the Summer 2009 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter.
In this issue we are pleased to provide another installment of brief articles representing a diversity of views and backgrounds. We are delighted to feature articles from guest contributors Paolo Baggia, Alan W. Black, Honza Cernocky, Maxine Eskenazi, Tina Kohler, Catherine Lai, James A. Larson, Matthew Marge, V. John Mathews, Ali H. Sayed, K. W. "Bill" Scholz, Matt Speed, Marcel Waeltermann, and Steve Young. We are also, as ever, pleased to provide articles from our staff reporters, Satanjeev "Bano" Banerjee, Svetlana Stoyanchev, Antonio Roque, Annie Louis, and Filip Jurcicek. And once again, Chuck Wooters has assembled a comprehensive list of CFPs and job postings.
Also, in this issue we will conduct a trial of a new feature: reader comments. At the bottom of each of the articles in this issue, readers will be able to comment on articles. Comments will be screened by the editors to ensure they are appropriate and on-topic. If this experiment is successful, we hope to make this feature permanent. Thanks to Rupal Bhatt at the Signal Processing Society for implementing this feature for us.
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions. You can reach us at speechnewseds [at] listserv (dot) ieee [dot] org.
Finally, to subscribe the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Jason Williams, Editor-in-chief
Pino Di Fabbrizio, Editor
Chuck Wooters, Editor
Identifying suitable candidates, and then putting together a strong supporting case for an award takes considerable time and effort. So is it worth it?.
IEEE Thematic Meetings on Signal Processing (IEEE-THEMES) are a new series of one-day meetings, devoted to a specific theme. The first meeting will explore Signal and Information Processing for Social Networking, and be held on March 15, 2010 in Dallas, Texas.
Results from the shared task evaluation of the Conference on Computational Natural Language Learning (CoNLL-2009) were presented in Boulder, CO, USA at June 4-5, 2009. Shared tasks have a long tradition at CoNLL and it already was the 11th task for which the organizers provided common task definition, data, and evaluation. In 2009, the shared task was dedicated to the joint parsing of syntactic and semantic dependencies in multiple languages.
The U.S. National Institute for Standards and Technology (NIST) sponsored a language recognition evaluation in Spring 2009. This article describes the evaluation tasks, data, participant algorithms, and results.
Ambiguity in language is problematic for NLP systems. However, what is ambiguous in one language might be unambiguous in another. This benefit forms the motivation for a multilingual framework to perform disambiguation in several language tasks and this approach has often found to yield considerable improvements over results using monolingual features. This article surveys a suite of multilingual models that have been discussed in some of the most recent work presented at the NAACL and EACL conferences this year.
AVIOS sponsors an annual speech application contest for college students. Student participation is ensured by offering substantial prizes funded by multiple corporate sponsors. Participants are encouraged to select from a variety of platforms including hosted and desktop VXML platforms, desktop speech APIs, multimodal environments, and smartphone-resident development suites. Contest judges use systematically developed evaluation criteria to rank contestant's entries. Since its inception in 2006, over 60 students from 4 countries have demonstrated their creativity, submitting applications ranging from children's games to an appointment manager, a communication tutorial, and even a calorie counter!
We continue the series of excerpts of interviews from the History of Speech and Language Technology Project. In these segments Louis Pols, Lauri Karttunen, and Jean-Paul Haton discuss how they became involved with the field of speech and language technology.
This article gives an overview of speech and multimodal technology used to help people with hearing disabilities. One of the described methods uses visualization and natural language processing techniques. The other method involves an invasive procedure that enables deaf people to gain the ability to hear.
This piece reviews the formative role of the W3C in language technology standards in the past decade, and its current activities which are shaping future standards.
Amazon's Mechanical Turk offers an opportunity to lower the cost of manual transcription while maintaining relatively high quality.
We announce a Spoken Dialogue Challenge (SDC) for the spoken dialogue community. After listening to discussions on the need for better assessment and comparison of work at venues like SigDIAL and the Young Researchers' Roundtable on Spoken Dialogue Systems we have taken on the responsibility of running a Spoken Dialogue Challenge for the whole community with the aid of a group of advisors who are seasoned researchers in our field.
OOVs (out of vocabulary words) are truly the nightmare of large vocabulary speech recognition. Researchers of Speech@FIT group at Brno University of Technology are focusing their research effort on the detection of OOVs by combining the posterior probabilities generated by strongly and weakly constrained recognizers.
SLTC Newsletter, July 2009
This is the time of year when the Speech and Language Technical Committee turns its thoughts towards the next round of award nominations which have to be submitted to the Society's Awards Board by October 1st.
Identifying suitable candidates, and then putting together a strong supporting case for an award takes considerable time and effort. So is it worth it? Clearly the recipients of awards enjoy receiving them but do they matter much beyond that, or are they just an example of "mutual back-slapping" with no real consequence?
In fact awards do matter -- indeed, they matter a great deal. Awards are important because they give our field credibility, and this operates at many levels. Within the IEEE itself, they give our area more influence both because they identify individuals whose opinions are listened to, and because they give weight to the area generally. Within our own institutions, awards to our colleagues in the Speech and Language area raises the esteem of not just the individuals but of the research area generally. Awards can also contribute materially to the prospects of promotion which results in more senior people with more influence to change things. Awards can also influence sponsors in the amount of funding they allocate to a sector. They can also be a factor in assessing funding proposals where an award can give an edge when competing for funds, especially when competing with other disciplines. For example, in the UK, all Universities are subjected to a Research Assessment Exercise (RAE) which directly determines a large chunk of their research income. One of the factors that is considered in making this assessment is the esteem of each research area as measured by awards, fellowships and similar.
So awards are important and the SLTC will continue do its best to make compelling nominations. But ultimately, the thing that matters most is the quality of the candidate. So please help us to identify deserving cases. We are looking for candidates for the Society Award, the Education Award, the Meritorious Service Award, and the Technical Achievement Awards. We also looking for candidates for the Best Paper Award, the Signal Processing Magazine Best Column Award, the Signal Processing Magazine Best Paper Award and the Young Author Best Paper Award. If you have ideas for any of these please forward them to myself (sjy@eng.cam.ac.uk), Philip Loizou (loizou@utdallas.edu) or indeed any member of the SLTC.
For more information, see:
Steve Young is Chair of the Speech and Language Processing Technical Committee of the IEEE Signal Processing Society.
SLTC Newsletter, July 2009
For nearly sixty years, the IEEE Signal Processing Society has provided its members access to the latest technologies and scientific breakthroughs through the quality of its conferences and publications. In the past, the conferencing and publication arms of the Society have worked independently for the most part. We are pleased to announce a joint initiative of the Conference Board and the Publication Board of the Society -- IEEE Thematic Meetings on Signal Processing (IEEE-THEMES).
IEEE-THEMES are one-day meetings, devoted to a specific theme. The first meeting will be held on March 15, 2010 at the Sheraton Dallas Hotel in Dallas, Texas. The theme for this first meeting is Signal and Information Processing for Social Networking.
How are IEEE-THEMES different from other conferences? There are several ways in which the new series will distinguish itself from others. The Proceedings of IEEE-THEMES will be published as a special issue of the IEEE Journal of Selected Topics in Signal Processing (J-STSP). The papers presented at the meeting will be selected based on a thorough and rigorous review of full-length manuscripts submitted to J-STSP in response to the call-for-papers for IEEE-THEMES. This means that the quality of the papers presented at the conference will be comparable to those in archival journals. We are committed to ensuring the highest quality for all our conferences, and expect IEEE-THEMES to serve as a model for achieving this goal.
IEEE-THEMES will provide a true learning experience to the attendees of the meeting. The meetings will run in single track (no parallel sections), with each presentation lasting for about 30 minutes. Because the learning aspect of the conference is as important as the novelty of the research results presented at the meeting, we are requiring that the papers be presented by experienced, senior authors of the paper and not students. Of course, students may be first authors, and may present their papers at the meeting if they are sole authors.
For the first time in the history of the IEEE Signal Processing Society, we will provide live feeds of the IEEE-THEMES for virtual attendance. The video and audio feeds from the meeting will also be available for future downloads.
We have made the cost of attending the meeting as low as possible for members of the Signal Processing Society. For both on-site and virtual attendance, the Society members will receive a 50% discount over the full registration rates. This is a significant reduction over IEEE member rates for registration. This is yet another benefit of membership of the Society.
It is easy for you to attend the first IEEE-THEMES if you are planning to attend ICASSP 2010 in Dallas. The meeting takes place on the day of tutorials at ICASSP If you are one of many who cannot stay away from work for more than a day, the one-day format may be especially suited for you. For all of you who have a technical interest in social networks or want to learn about signal and information processing in social networks, we look forward to seeing you on site or virtually on March 15, 2010.
V. John Mathews is Professor in the Department of Electrical and Computer Engineering at University of Utah. He is also Vice-President (Conferences) of the IEEE Signal Processing Society. Email: mathews@ece.utah.edu
Ali H. Sayed is Professor and Chairman in the Electrical Engineering Department at UCLA. He is also Vice-President (Publications) of the IEEE Signal Processing Society. Email: sayed@ee.ucla.edu
SLTC Newsletter, July 2009
Results from the shared task evaluation of the Conference on Computational Natural Language Learning (CoNLL-2009) were presented in Boulder, CO, USA at June 4-5, 2009. Shared tasks have a long tradition at CoNLL and it already was the 11th task for which the organizers provided common task definition, data, and evaluation. In 2009, the shared task was dedicated to the joint parsing of syntactic and semantic dependencies in multiple languages.
This year's task can be considered as an extension of the 2008 shared task. Similar to the CoNLL-2008 task, the main objective of the shared task was to explore joint parsing techniques under a unified dependency based formalism. As in 2008, the organizers of the shared task hypothesized that parsing using information available from a semantic parser for syntactic parsing and vice versa could improve upon the more common cascade approach. Note that the typical approach to syntactic and semantic parsing is to build a pipeline composed of a syntactic parser followed by semantic analysis using features derived during syntactic parsing. In contrast to the monolingual setting of the CoNLL-2008 task, the organizers extended the task to cover multiple languages. The goal of the organizers was to evaluate how different approaches could cope with different languages such as English, Catalan, Chinese, Czech, German, Japanese and Spanish.
Following last year's task, the organizers designed numerous categories in which they evaluated the submitted results. Among others, the most important categories were "close" and "open" challenges. In the closed challenge, participants were only allowed to use training data provided by the organisers. In contrast, the open challenge allowed participants to incorporate any kind of available knowledge. Moreover, the challenges were divided into two tasks: (1) joint task - both syntactic dependency parsing and semantic role labelling had to performed, (2) semantic role labelling only task - the syntactic dependency parses generated by state-of-the-art parsers for the individual languages were provided and only the semantic parsing had to be performed. According to the organizers, the most interesting evaluation was the joint task-closed challenge because it allowed evaluation of the benefits of joint parsing in a "fair" environment which was not influenced by use of different data. This year, 20 systems participated in the closed challenge; 13 systems in the joint task and seven in the semantic role labelling task only. Moreover, two systems competed in the open challenge (joint task).
As the main topic of the shared task was joint parsing, the organizers were very interested in a comparison between the joint and the cascade approaches. However, only four of the 20 systems used the joint model for syntactic and semantic dependency parsing. To give an example of a joint parsing approach, the best joint parser "Merlo", which was third in the main evaluation, used synchronous syntactic and semantic derivations in an incremental parsing model using the joint probability of the syntactic and semantic dependencies. The system maintained two independent stacks of syntactic and semantic derivations synchronized at each word. The synchronous derivations were modelled with an Incremental Sigmoid Belief Network that had latent variables to represent properties of parsing history relevant to the next step in parsing (Gesmundo et al., 2009). On the other hand, the over-all best system "Che" was based on a cascade of three components; syntactic parsing, predicate classification, and semantic role labelling. First, the syntactic parser implemented the high-order Eisner parsing algorithm using spanning trees (Eisner et al., 2000). Second, a support vector machine model was used to classify the predicates. Finally, maximum entropy model was used for semantic role classification combined with integer linear programming to enforce global constraints on the predicted roles (Che et al., 2009). As the best two systems were not using any joint parsing and the number of joint parsers was low, the organizers note that it is not still clear whether joint parsing offers a significant improvement over other approaches.
Overall the shared task of 2009 was very demanding because the participants had to cope with several languages and large amount of data in short development time (about two months). For example, Wanxiang Che, who submitted the winning system of the joint task, says that his group had to use Amazon EC2 cloud computing service to be able to train and test their models for all seven languages in such short time. Although processing the large amount of data, determining initial settings and the right features of the parser was computationally expensive, Wanxiang Che notes that careful feature engineering worked in their favor. Also Hai Zhao, who submitted the best semantic role labelling-only system, emphasized that the crucial part of the training process was determining the right features. Only by using parallel computation and clever optimization was his team able to select the right features for the parser (Zhao et al., 2009).
For more information (including links to data sets and task documentation), see:
SLTC Newsletter, July 2009
The U.S. National Institute for Standards and Technology (NIST) sponsored a language recognition evaluation in Spring 2009. This article describes the evaluation tasks, data, participant algorithms, and results.
The United States National Institute for Standards and Technology (NIST) sponsored a language recognition evaluation (LRE) in the spring of 2009. The evaluation concluded with a workshop held in Baltimore, Maryland, U.S.A on June 24 and 25. The 16 participants in this year’s evaluation were primarily from Europe and Asia, with one participant from the United States. At the June workshop participants described their algorithms, NIST reported on evaluation results, and all participants engaged in joint discussions regarding data, performance measures, and future tasks. This was the fourth LRE since 2003.
This year’s evaluation contained three tasks: 23-language closed-set evaluation, 23-language open-set evaluation, and 23-language language-pair evaluation. The latter two tasks were optional.
Closed-set evaluation requires a language detection decision and score for each target language when the test segments are limited to the known set of (23) target languages. Open-set evaluation requires a language detection decision and score when the set segments are not limited to the target languages; i.e., out-of-set (OOS) languages are included. Language-pair evaluation requires a language detection decision and score when the test segments are limited to two languages; i.e., there is always a single alternative language hypothesis for each trial.
Each task contained three segment-duration test conditions: 3-, 10-, and 30-seconds. The open-set evaluation included 16 OOS languages, with considerable numbers of speech tested for each OOS language. There were significantly more OOS speech segments this year than in previous LREs.
The 23 target languages were:
| Amharic | Bosnian | Cantonese |
| Creole (Haitian) | Croatian | Dari |
| English (American) | English (Indian) | Farsi |
| French | Georgian | Hausa |
| Hindi | Korean | Mandarin |
| Pashto | Portuguese | Russian |
| Spanish | Turkish | Ukrainian |
| Urdu | Vietnamese |
Data collection for LRE has become increasingly challenging, so a new paradigm was used this year: found data. Instead of paying speakers for their telephonic voice recordings in various languages, narrowband voice segments were extracted from Voice of America (VoA) recordings, since these are most likely talkers using telephone, and therefore more likely to be conversational. This not only decreased the cost of data collection, it also provided larger numbers of test segments. The VoA recordings were collected across several years, providing a wide variety of languages and speakers. Researchers at Brno University of Technology’s (BUT) Faculty of Information Technology created an algorithm for detecting narrowband portions of the broadcast. VoA broadcast information provided language label information for most segments. Segments with no VoA broadcast information were labeled using automated language recognition. All labels were verified by the Linguistic Data Consortium (LDC) to insure correctness. The evaluation data contained some conversational telephone speech (CTS), but the bulk was from VoA narrowband segments.
Most participants submitted algorithms with combinations of Gaussian Mixture Models (GMM), Support Vector Machines (SVM), and phonetic tokenization. Most GMMs were discriminative, and most phonetic tokenization used tokens extracted from multiple languages. Most sites used feature vectors containing Mel-frequency cepstral coefficient (MFCC) and shifted delta cepstra (SDC), and they incorporated some sort of channel and noise compensation. Sites were requested to report their processing speeds. These ranged from 5 times faster than real time to 23 times slower than real time.
NIST defined the basic performance measurement to be a cost performance based on detection miss and false alarm probabilities, with equal cost for both types of errors. They offered an alternative cost measure using log-likelihood ratios, and also provided graphical performance representation using detection error tradeoff (DET) curves.
Overall, the performance was as expected, with the closed-set performance showing about half the error rates of open-set performance. For the 30-s segments, the top performers achieved equal error rates (EER) below 5% for open-set task and below 2% for the closed-set task.
The language-pair task performance was better for all systems performing this task in all durations than for the closed-set task. Performance for over 90% of the 253 language pairs had an average error rate less than 1%. The five language pairs exhibiting the biggest challenge for automated language recognition are all closely related to each other: Hindi/Urdu Bosnian/Croatian, Russian/Ukrainian, American English/Indian English, Dari/Farsi.
NIST plans to hold language evaluations and workshops every other year (i.e., odd years). In the years between (i.e., even years), they will hold speaker evaluations and workshops. The found-data paradigm worked well this year, and it is hoped future evaluations will also take advantage of existing data.
Thanks to Alvin Martin and Craig Greenburg for providing input to this article.
You can learn more about NIST’s language recognition evaluations at the NIST language recognition evaluation web page.
If you have comments, corrections, or additions to this article, please contact the author: Tina Kohler, m.a.kohler [at] ieee [dot] org.
Tina Kohler is a researcher for the U.S. Government. Her interests include speaker and language processing. Email: m.a.kohler@ieee.org
SLTC Newsletter, July 2009
Ambiguity in language is problematic for NLP systems. However, what is ambiguous in one language might be unambiguous in another. This benefit forms the motivation for a multilingual framework to perform disambiguation in several language tasks. Multilingual models use information about equivalent words or sentences in two or more languages and have often been found to yield considerable improvements over results from monolingual features. In addition, the feasibility of this approach has greatly increased in recent years with the availability of large amounts of parallel texts and translations in different languages. This article surveys a suite of multilingual models that have been discussed in some of the most recent work presented at the NAACL and EACL conferences this year. These models cover a variety of topics ranging from ambiguity resolution for parsing and part-of-speech tagging, better methods for model design and preprocessing for statistical machine translation systems and findings about language similarities that enable systems built for one language to be used for another.
Snyder et al. [2] present a multilingual approach to resolve ambiguity during part of speech (POS) tagging. For example, a word like “fish” can be used in English as either a noun (in “I like fish.”) or a verb (in “I love to fish”). But in French, the words for noun (“poisson”) and verb forms (pêcher) are different. Therefore depending on the tag for the word in French, this can be unambiguously assigned in this example, the correct tag for the English equivalent can be chosen. In this work, the basic structure consists of a Hidden Markov Model (HMM) for each language which is designed to capture properties about tag sequences that are specific for that language. Such a model structure is standard in monolingual setups. Word alignments across the languages are then used to build a superstructure to learn multilingual patterns. The model now provides the ability to learn the POS tags for a particular language using both patterns of POS transitions in that language together with the information about tags for same word in a different language. When used to tag monolingual texts in 8 European languages, the multilingual model obtained better performance than monolingual models in a majority of the cases. Another experiment showed that performance improved continuously as the number of languages in the model was increased.
A similar intuition can be employed to disambiguate between different senses of the same word. A word with multiple senses in one language may have different lexical forms for the senses in another language. Work by Apidianaki [10] presents an analysis of and a new approach to multilingual word sense disambiguation.
Multilingual models are also attractive for learning larger syntactic structures, where several problems related to ambiguity are often encountered. Fraser et. al [1] show that parse-reranking can be improved by comparing the candidate parses for a sentence in one language to parse trees for the sentence in a different language. Their experiments use English sentences and their German translations. The set of parses generated for an English sentence are compared to the 1-best parse for the equivalent German sentence. The divergence between their parse trees is examined and used to rank the candidate English parses by closeness to their German counterpart. For example, two features found to be very indicative of syntactic divergence are difference in spans and correspondence in depth of the two parse trees. The model using these bilingual features resulted in improved performance over a monolingually trained parser. The German parse trees and word alignments are also obtained automatically showing that considerable benefits can be had from a multilingual model even with slightly noisy information.
In another recent piece of work, Cohen and Smith [8] show their new set of priors for probabilistic grammars can be used to jointly learn grammars for English and Chinese with improved performance over their monolingual settings.
In addition to resolving ambiguity for monolingual texts, models trained on information from more than one language can be particularly advantageous when the final task or application involves both languages. For example, when word boundaries are not explicitly marked in languages like Chinese, the standard technique is to use a segmenter trained on annotated monolingual corpora. However the segmentations obtained may not always be optimal, such as when inducing alignments for the purpose of training Machine Translation (MT) systems. Ma and Way [3] present an approach to word segmentation for MT where decisions about boundaries are made by considering properties of both languages involved. Following this intuition, the system learns segmentation boundaries for Chinese by examining the frequencies of alignments of English words to blocks of Chinese characters. Since the model is designed with the end task in mind, an extrinsic evaluation approach is adopted and the value of the segmentation is tested in a MT task. When the bilingual segmentation model is used, consistently good performance is obtained on translation for three different data sets.
Ma and Way’s work [3] outlined above shows that for tasks like MT that involve more that one language, preprocessing of source and target languages can be better informed using the properties of both languages. Two other studies, also in MT, use multilingual information from an entirely different perspective. These show that a third language, other than source and target, can used to improve MT performance by an intermediate step involving information from this language.
An example of this approach is the use of a "pivot" language to aid the translation from a source to target language when parallel resources are scarce for the language pair. For instance, the translation process could be cascaded and performed in two stages, source to pivot language translation followed by translation from pivot to target language. English has commonly been used in prior work because parallel texts are often available with English and such resources are plentiful. Paul et al. [5] however seek to answer the question whether English is always the best choice. Their experiments involve pair-wise translation experiments with 12 languages. The results confirm their intuitions. For a majority of the pairs, the best performance was obtained using a pivot that was not English. Interestingly, the optimal pivot for a language pair is also found to different for translations in the two directions. Based on their results, Paul et al. [5] suggest that in addition to amount of training data available with the pivot language, translation quality from source to pivot and pivot to target is another important factor to consider while choosing a pivot. Relatedness of the pivot language to source and target is also another factor because it indirectly affects the quality of the associated translations.
Chen et al. [4] provide additional work in this direction. Their focus is on phrase based MT where a table of mappings is maintained for phrases from the source and target languages. In this framework, a large amount of training data is needed for good performance but with it comes subsequent problems with model size and increased time for searching the table. In addition, tables could also contain noise from wrong alignments that could adversely affect translation quality. This work presents a novel approach to solving these problems using information from a third “bridging” language. A mapping from source to target is kept in the phrase table only if there is also a corresponding mapping from source to target through a common bridge phrase. A direct effect of this constraint is reduction in size of the phrase tables. The reduction also eliminates noisy entries and the table can be loaded and translations performed considerably faster than when using the full table. The filtering works best with a language closely related to source and target. Then matching phrases between source, target and bridging languages are easily found and can be used to refine the source-target mappings. On the other hand with very unrelated languages, lots of filtering can drastically reduce the information in the table.
While related languages can be used to improve performance by joint learning or in a multilingual model, Harbusch et al. [6] show that sometimes similarities are high enough to enable complete system transfer from one language to another. Central to this work is the development of a system that can generate ellipsis in coordination-based constructions. The underlying framework is a set of rules that warrant elision in appropriate situations. An example of such elisions in English would be the reduced construction "I wanted a cat and my sister did too" in place of "I wanted a cat and my sister wanted a cat too". In this work, the authors demonstrate that rules for generating elliptical structures in Estonian are extremely similar to that in German although the two languages come from different families. As a result, an ellipsis generation system written for German could be completely transferred and used for Estonian sentences with no modification.
A number of other recent work also note improvements from multilingual models. In multisource MT, the model is built to take advantage of existing translations for a text in different languages to improve performance for translation into a new language. Schroeder et al. [9] present a novel method for multisource translation and observe steady improvements as the number of languages increase in the input set. Bouchard-Côté et al. [7] show that re-construction of ancient languages is also done better using a larger set of languages that constitute its modern counterparts.
[1] Alexander Fraser, RenjingWang, and Hinrich Schütze. 2009. Rich bitext projection features for parse reranking In Proceedings of EACL 2009, pages 282-290.
[2] Benjamin Snyder, Tahira Naseem, Jacob Eisenstein, and Regina Barzilay. 2009. Adding more languages improves unsupervised multilingual part-of-speech tagging: a bayesian non-parametric approach In Proceedings of HLT-NAACL 2009, pages 83-91.
[3] Yanjun Ma and Andy Way. 2009. Bilingually motivated domain-adapted word segmentation for statistical machine translation In Proceedings of EACL 2009, pages 549-557.
[4] Yu Chen, Martin Kay, and Andreas Eisele. 2009. Intersecting multilingual data for faster and better statistical translations In Proceedings of HLT-NAACL 2009, pages 128-136.
[5] Michael Paul, Hirofumi Yamamoto, Eiichiro Sumita, and Satoshi Nakamura. 2009. On the importance of pivot language selection for statistical machine translation In Proceedings of NAACL-HLT 2009, Short Papers, pages 221-224.
[6] Karin Harbusch, Mare Koit, and Haldur Õim. 2009. A comparison of clausal coordinate ellipsis in Estonian and German: Remarkably similar elision rules allow a language-independent ellipsis-generation moduleIn Proceedings of the Demonstrations Session at EACL 2009, pages 25-28.
[7] Alexandre Bouchard-Côté, Thomas L. Griffiths, and Dan Klein. 2009. Improved reconstruction of protolanguage word forms In Proceedings of HLT-NAACL 2009, pages 65-73.
[8] Shay Cohen and Noah A. Smith. 2009. Shared logistic normal distributions for soft parameter tying in unsupervised grammar induction In Proceedings of HLT-NAACL 2009, pages 74-82.
[9] Josh Schroeder, Trevor Cohn, and Philipp Koehn. 2009. Word lattices for multi-source translation In Proceedings of EACL 2009, pages 719-727.
[10] Marianna Apidianaki. 2009. Data-Driven Semantic Analysis for Multilingual WSD and Lexical Selection in Translation In Proceedings of EACL 2009, pages 77-85.
If you have comments, corrections, or additions to this article, please contact the author: Annie Louis, lannie [at] seas [dot] upenn [dot] edu.
SLTC Newsletter, July 2009
AVIOS, the Applied Voice Input/Output Society, is a non-profit foundation dedicated to informing and educating developers of speech applications on best practices for application construction and deployment. In early 2006 we decided to focus this goal on college students by giving them an opportunity to demonstrate their developmental competence to the speech community. The competition has now grown into an annual contest whose winners are substantially remunerated for their efforts, and whose winning applications are posted on our website.
The development of a speech application contest requires multiple distinct activities:
Ideally, an application development platform suitable for student use must be cost-free to the student, and approachable without an extensive learning curve. Students should be able to focus on intricacies of speech / multi-modal application development without having to master complex multi-layered development environments. After all, contest entries are typically developed from concept through delivery in a single college semester. VoiceXML platforms such as BeVocal / Nuance Café and Voxeo Prophecy, as well as multi-modal platforms such as the Opera Multimodal Browser have proven well suited to meet these requirements. In addition, students with prior Microsoft development experience have successfully developed applications using SAPI and .NET, and even WinMobile5.
Each year we have attempted to extend the palette of available platforms to encourage student exploration. We've recommend sophisticated development environments such as Voxeo's VoiceObjects platform and CMU's RavenClaw/Olympus, and are encouraging the use of AT&T's Speech MashUp. In the future we hope to negotiate no-cost access to a number of other full-featured speech application generation environments.
Recruiting sponsors for the contest is fundamental to the success of the program. Sponsors provide not only prizes for winners, but endorsement of their favorite development platform. Endorsement includes ‘getting started' instruction, reference documentation, and access to technical support for students who have chosen to use that platform. Sponsoring institutions receive recognition on our website and at our annual conference, and are offered access to student resumes.
In order to ensure valid and unbiased selection of winners, we have selected several a priori criteria for evaluating speech / multimodal application quality. Criteria include robustness, usefulness, technical superiority, user friendliness, and innovation; and in an effort to ensure objectivity through quantification, each criterion is summarized using a 5-point Likert scale.
Contest applications have been evaluated by speech technology leaders from companies including Microsoft, Nuance, Convergys, and Fonix on the basis of technical superiority, innovation, user-friendliness, and usefulness of each application. Judges typically had decade or more of experience in the speech technology field and explicit experience in the design, development, deployment, and utilization of speech and multi-modal applications. Each judge possessed sufficient computer resource to access student entries their intended deployment channel (e.g., a judge must have access to a WinMobile handset if (s)he is to judge a student's WinMobile project). Judges independently evaluate each student project, then the evaluation scores and associated written evaluations are consolidated and ranked. Judges then meet physically or virtually to review the rankings, possibly adjusting ranks to match shared observations, and finally selecting the winners and runners-up.
In the past three years, nearly 60 students from 10 academic institutions in 4 countries have participated in the contest. Winning applications included the following:
The contest proved effective in meeting our goals by fostering creative thinking in the use of speech technology and in the development of speech and multimodal applications. For the past three years, the contest has exposed students to a variety of speech technologies, including:
The above corporate sponsors have provided prizes such as software packages, popular hardware and monetary awards, including airfare and lodging for attending Voice Search Conference, to contest winners. In addition to experiences with commercial products, students were also able to use university prototypes, including CMU's RavenClaw/Olympus and MIT's WAMI.
An unanticipated benefit of the contest is to help students learn more about the corporate environment and to help the corporate sponsors identify emerging talent. Comments from participating students indicate that the contest has been a success: "The contest was a great chance for me to gain some in-depth knowledge." "I was very satisfied with learning to write voice applications." "There is a notable difference between theory and practice in speech recognition", and from one sponsor, "Wow! I want to contact that student!"
For more information about past contest entries and winners, the current contest, and future contests, please see the AVIOS web site at www.avios.com.
K. W. "Bill" Scholz is President, AVIOS.
James A. Larson is an Adjunct Professor in the Computer Science Department of Portland State University.
SLTC Newsletter, July 2009
We continue the series of excerpts of interviews from the History of Speech and Language Technology Project. In these segments Louis Pols, Lauri Karttunen, and Jean-Paul Haton discuss how they became involved with the field of speech and language technology.
These interviews were conducted by Dr. Janet Baker in 2005 and are being transcribed by members of ISCA-SAC as described previously in 1, 2, 3, 4, 5. Sunayana Sitaram (National Institute of Technology, Surat), and Antonio Roque (University of Southern California) coordinated the transcription efforts and edited the transcripts.
Transcribed by Matt Speed (University of York)
Q: One question that I think we’ve asked everybody, is how did you get into this field?
A: I’m a physicist by training, but I didn’t know too well what field I would choose. I never knew what I wanted to do, so I started to study physics because I thought it might be interesting, and I had good figures in high school. While studying theoretical physics I didn’t know which direction to take, so I took solid state physics but still wasn’t sure about it. So I got my degree and I didn’t know what to do, and then I had to fulfill my military service which in the military in Holland at that time you could do before after your university studies. So, rather than fulfilling my draft I took the alternative of starting some research at the defense research organization, and that happened to be the TNO Institute in Soesterberg. There I came into the Department of Speech and Hearing of Reinier Plomp and I started doing military-type work, measuring noise around rifles and hearing loss in people that were shooting and such practical things. Quickly I ran into the regular research that was going on there, and that was psychoacoustics. At that time psychoacoustics was only done by tones and by combinations of tones and Plomp wanted to make this slightly more realistic. He wanted to use real sounds, and one of those real sounds of course is speech sounds and vowels. He wanted to do timbre perception and pitch perception on real sounds and he asked me if I would be interested in working on that a little bit. So that’s how I gradually grew into it. We started to do psychoacoustic research with vowel like sounds and we liked it so much that it grew and we went on to more dynamic sounds, then synthesis, recognition and coding and all of that. After my period of one and half years in the military we talked to each other and said that he liked me and we both liked that type of work, so I got a job at the institute.
Q: And what year would that have been?
A: I graduated in 1964, so in mid 1965. I became active in the field and from a physicist I gradually grew into a speech scientist and also a phonetician. I never got any training in phonetics, but I took it up myself. That’s how it started and the work we did came closer and closer to phonetics work done in the universities. So then you become a member of the Phonetic Association and you become a chairman of the board and things like that and then they need a new professor in Amsterdam and my boss said “why don’t you apply, you never know”. I was totally relaxed because I didn’t care, I could do whatever I liked in the institute, they gave me complete freedom but I thought ‘why not’. That was exactly the right attitude to get that job because my competitors were all very nervous and were chasing the job because they had a long career in this field already. For some reason they chose me, and that was 1982
Q: That was 1982?
A: Yes. I also got my PhD of course. At a certain point I was still at TNO. The ‘T’ in TNO stands for Applied – Applied Physics Research, so it is an applied research institute and one of the sections is Defence Research but the institute was very open towards science. Actually it was more a real research institute, like the Fraunhofer-Gesellschaft in Germany. They had good opportunities to get your doctoral degree. So after a while I graduated. I got my PhD in 1977 I think, so that was more than 10 years after I started, so I did it the slow way. I first did all kinds of things and then at some point we both realized that if we put a few things together then we would have a nice topic for a thesis, so that’s what I did.
Transcribed by Catherine Lai (University of Pennsylvania)
Q: Could you maybe say something about how you got into this field?
A: Oh, it's kind of difficult to pinpoint it. In linguistics I've actually had two careers. I started out as a semanticist. I wrote my dissertation on problems of reference in syntax and I invented a theory that became very widely used for discourse reference, then it became the theory of Irene Heim and Hans Kamp who developed it further. Then I worked on presuppositions and implications and brought about the theory of questions, the model theoretic semantics of questions. But I had been doing a little bit of computation already when I was a grad student and I spent a year when I was writing my semantics dissertation in Santa Monica at the RAND corporation, where I worked with Martin Kay who is one of the great pioneers of the whole field. But then I got my job in Texas and I was just doing semantics for ten years with nothing to do with computational things. But I was getting tired of this stuff and I just accidentally got myself one of these early ARPANET accounts and decided that I was going to do Finnish.
Q: What year was that?
A: This was around 1978. Again kind of...I signed up to teach a course in computational linguistics, of course knowing nothing about it at the time.
Q: (laughs) Well, that's the best way to learn it right?
A: That's what academic people do!
Q: Absolutely!
A: And so I re-taught myself how to program and I taught myself LISP. I was organizing, actually even, a conference on parsing and a lot of people came to it including my old friends from RAND who are Martin Kay and Ron Kaplan who, I found, were already at PARC, in California, and on came also a young graduate student from Finland by the name of Kim Koskenniemi and discovered that we all had an interest in morphology and we all had been doing it. So, I had built an analyzer for Finnish in LISP...
Q: And what did it run on? What hardware?
A: A DEC machine... a DEC 20 or DEC 10, one or the other.
Transcribed by Marcel Waeltermann (Deutsche Telekom Laboratories)
Q: We’re great pleased today to have Jean-Paul Haton come here and honored that he is allowing us to interview him today. Thank you so much.
A: It’s a pleasure.
Q: One question I think we’ve asked everybody, and maybe the only question we’ve asked everybody is: How did you get into the field?
A: Good question for a good start. Well, I remember the date, it was in ’68, because May ’68 for a French guy is an important date. I was just graduated from Ecole Normale Supérieure. My first introduction to the field of speech processing was related to speech training for the deaf; for deaf children, especially. From that particular topic, I rapidly shifted to automatic speech recognition. Until now, I’m still involved in this particular area of speech communication.
Q: Why did you switch to speech recognition? Was that an opportunity?
A: In fact, speech training is one application area, a fundamental aspect of speech processing, pattern recognition, and speech recognition.
Q: And who were you working with at that time?
A: I graduated from Ecole Normale, as I said, in Paris, and I went to Nancy, which is in the north-eastern part of France. And there was a person who was working on speech training for deaf children, due to the fact that, unfortunately, his daughter was deaf. That’s the reason why he was working on this. I was interested by what he was doing. But rapidly, as I said, I shifted to the problem of speech recognition, which was more attractive for me.
Q: Were there other people working in speech recognition there?
A: No, I was the first person. I started the work at that place.
Q: What did you start trying to do? How did you start?
A: I started trying to recognize vowels, using a perceptron. So, that was very particular. At that time, the back-propagation learning algorithm was not yet invented, I should say. So, we were using a single-layer perceptron, which is a linear classifier. So, of course the results concerning the recognition of vowels were not really good.
Q: What computers were you using, or what resource?
A: We were using what we called at that time a minicomputer, “mini-ordinateur” in French, from the French company Télémécanique, which was a very limited machine. Nevertheless, for my doctoral thesis in 1974, I had a real-time system for recognition of, let’s say, if I remember well, 30 words, which was not bad for the time; and in real-time, once again.
SLTC Newsletter, July 2009
This article gives an overview of speech and multimodal technology used to help people with hearing disabilities. One of the described methods uses visualization and natural language processing techniques. The other method involves an invasive procedure that enables deaf people to gain the ability to hear.
Current state-of-the-art systems perform translation of English to Sign English. Sign English is a word-to-word translation from English where each word in a sentence is replaced with its sign. American Sign Language (ASL), on the other hand, is a real natural language. It has its own grammar, lexicon, and linguistic structure. ASL is a graphic language- it uses eye gaze and facial expressions to convey meaning. In addition to the lexicon, ASL also has “classifier predicates” which consist of semantically meaningful handshapes. A handshape depends on the type of the entity described: whether it is a motion, a surface, a position, etc. ASL also requires spatial reasoning: 3D hand movement paths play an important role in ASL. Speakers use 3D space for referring to described objects along with the spatial orientation of their hands.
Automatic translation of speech or text into animation of sign language would significantly increase the accessibility of information to people with hearing disabilities. Machine translation is a rapidly developing field in language research. As ASL is a natural language, machine translation techniques may be applied to it. However, generation of ASL poses an additional challenge of visualization and spatial reasoning which is not present in other languages. Researchers at CUNY address the automatic generation of ASL [1] and present the first system that generates classifier predicates.
The researchers performed both subjective and objective human evaluation of the visually generated ASL. As a subjective evaluation listeners were asked to judge understandability, grammaticality, and naturalness of the generated expressions. As an objective evaluation listeners’ comprehension of automatically generated expressions was evaluated.
The subjects consistently judged the visually generated ASL more grammatical and understandable than visually generated Sign English. The comprehension task also showed that listeners correctly understood an utterance in more than 80% of cases while comprehension of English Sign was around 60%. These results show great potential for automatic translation to visualized ASL.
Another technological solution for the hearing impaired is offered by cochlear prosthesis. The prosthesis is inserted into the cochlea (the spiral-shaped cavity of the inner ear that contains nerve endings essential for hearing) by a surgeon. This technology combines scientific knowledge in biology and in signal processing. It involves an invasive procedure on a patient and relies on signal processing techniques for analyzing and transmitting sound information to the brain.
The normal hearing process is amazingly complex. Sound waves undergo a series of transformations before arriving to the brain:
The most common cause of deafness is damage to the hair cells. A cochlear prosthesis is designed to electrically simulate the auditory nerve. It bypasses the normal hearing mechanism (steps 1 – 5) and electrically stimulates the auditory neurons directly. Cochlear implant researchers face a technical challenge of stimulating auditory neurons to convey meaningful information, such as amplitude and frequency of the acoustic signal to the brain. The cochlear implant consists of a microphone, a signal processor, a transmission system, and an electrode inserted by a surgeon into the cochlea.
Strategies used by cochlear implants for signal transmission are largely dependent on the signal processing techniques such as compressed-analogue, continuous interleaved sampling, and extraction of fundamental frequency of formants.
Assessing implant performance is difficult as the cause of deafness and personal characteristics affect the effectiveness of the implant. Depending on the physical characteristics, some people are able to get a significant improvement in hearing. You can hear some simulations of speech perception using cochlear implants at http://www.utdallas.edu/~loizou/cimplants/cdemos.htm
SLTC Newsletter, July 2009
Speech transcription - the process of writing down the words spoken in a snippet of audio - is useful for many reasons. It is useful for humans, because consuming information from text is often faster than doing so from audio; it is useful for automated information storage and retrieval systems, and it is a necessary first step for speech research - for speech recognition, understanding, summarization, synthesis, etc. However, manual speech transcription is an expensive and time-consuming task - sometimes requiring up to ten times the actual duration of the audio snippet to transcribe it. Amazon's Mechanical Turk offers an opportunity to lower the cost of manual transcription while maintaining relatively high quality.
In 2006, Amazon.com, Inc. started Mechanical Turk (MTurk for short) - a website and web application that brings together software developers/researchers ("requesters") who have tasks that need human expertise, and human workers ("providers") who are willing to perform these tasks for monetary compensation. Tasks most suitable for submission to this system are those that can be trivially accomplished by (at least some) humans, but that cannot be done well, if at all, by automatic means. For example, while almost any human can quickly and accurately tell which way, left or right, a person is looking in a photograph, doing so is often difficult for a computer program. MTurk provides a platform for requesters to have such tasks completed through the following sequence: Requesters upload tasks to MTurk's website (manually or automatically through an API). These tasks are viewable to providers who can choose to accept one or more of these tasks. Once providers complete the tasks, the requester can retrieve and review the providers' outputs, and pay them for their efforts if the work appears to be satisfactory. MTurk keeps track of each provider's task-completion rate and other performance measures. Requesters can require that only providers with a particular past job performance level or higher can work on their tasks.
The task of speech transcription is well suited for MTurk - it is relatively easy for humans to do and difficult for speech recognizers. Additionally, speech transcription can be split into small jobs for multiple workers to do in parallel. (A good description - with instructions - of how to use MTurk for speech transcription for human consumption is provided by self-described journalist and programmer Andy Baio on his blog here.) Some commercial services, like CastingWords, use MTurk to provide transcriptions; such companies provide value by taking care of the details of job uploading/downloading, and performing quality assurance, etc.
Unlike transcriptions done for human consumption, however, transcriptions for speech research must be more "faithful" - with speech phenomena such as false starts and repeats transcribed accurately rather than cleaned up. We undertook a small exploratory study to examine the feasibility of using Amazon's Mechanical Turk to create faithful transcriptions of speech. In our experiment, we used 16 utterances ranging from 8 to 32 seconds in length. Each utterance was spoken by a single person (with multiple speakers across the dataset, most of them native), and contained a simple command, e.g. "Move forward for a few seconds, and then turn left". The audio was recorded using close-talking microphones, and was uniformly high quality. We had five MTurkers transcribe each utterance, and paid each MTurker $0.10 for their efforts. (We did not experiment with different payment amounts, and believe $0.10 to be high for the lengths of utterances we used.) MTurkers were instructed to transcribe faithfully - transcribing all false starts, repeats, etc., and calling them out with special notation (angle brackets, parentheses, etc.).
We evaluated MTurkers' transcriptions against transcriptions done in-house, and found that individual MTurkers' transcriptions had a word-level accuracy of 91% averaged across all transcriptions of all utterances. When false starts were cleaned up from both the MTurkers' transcriptions and the references, the average accuracy increased to 95%. It is likely that transcripts of even higher accuracies can be extracted from the five transcriptions per utterance by word-aligning the transcripts and doing word-level voting. We did not experiment with this idea, but to get a feel for the accuracy level that might be achievable, we picked the best transcript for each utterance (from the 5 available transcripts) with false starts, and found an average accuracy of 98%. While we will not know which transcript is the best when we don't have in-house transcripts, this result shows that for each utterance, there is at least one high quality transcript. With a voting scheme, it may be possible to extract this transcript.
In a separate study conducted by Dr. Dan Melamed, Principal Member of Technical Staff at AT&T Labs Inc., MTurk was evaluated for transcribing speech of low audio quality. This study was conducted using speech recorded over cell phones, with uniformly low audio quality. The utterances used in the experiment were short, containing a business name and a location, and were spoken by a single speaker. (There were different speakers across the dataset, most of whom were native speakers.) Five MTurkers were used, and their transcriptions merged by utterance-level voting. While individual MTurkers were found to be uniformly and substantially less reliable than in-house transcribers, the combined utterances were generally high quality. Specifically, by removing the top 25% utterances that MTurkers most disagreed on, the accuracy of the transcription was found to be equivalent to in-house transcription. Further, these accurate combined transcriptions cost an order of magnitude less than in-house transcription.
When asked whether he would use Mechanical Turk for speech transcription
purposes, Melamed said "Yes, we hope to use MTurk regularly in the future."
SLTC Newsletter, July 2009
In several of the fields of speech and language processing, challenges have been appearing. Each field that has welcomed a challenge has become more focused and seen a dramatic improvement in accuracy. Challenges bring communities together. They enable comparisons of techniques within the same environment. And they are the impetus behind fundamental advancements.
This is therefore the announcement of the Spoken Dialogue Challenge (SDC) for the spoken dialogue community. After listening to discussions on the need for better assessment and comparison of work at venues like SigDIAL and the Young Researchers' Roundtable on Spoken Dialogue Systems we have taken on the responsibility of running a Spoken Dialogue Challenge for the whole community with the aid of a group of advisors who are seasoned researchers in our field.
The goal of SDC is to enable as many research groups in the field as possible to compare results on similar tasks. The field of spoken dialogue research is large, encompassing areas of interest that are as different as reinforcement learning and error recovery on the theoretical level and telephone-based services and multiparty, multimodal conversations on the application level. Although one challenge cannot initially bring all of the different interests together, SDC is being created as a framework where challenge patterns can be tried and expanded as experience and community feedback dictate.
We propose the follow structure, deliberately creating an initial proposal that the community can discuss and contribute to. Our initial proposal is to start from the simple spoken dialogue task of building an information presentation system that gives bus information. We have chosen this as the first application because:
The participants will create a bus information system. Depending on their background, they may:
At the outset of the challenge, there will be training data that can be used in any way the teams see fit to train their systems. This data will include speech and the back-end (access to a database of bus schedules).
The challenge will consist of having three levels of callers progressively interact with the participating systems. The first level of callers will be a round robin of all of the members of the participating teams. They will be given numbers to call, a well-defined calling period, and scenarios to be completed. The second level of callers will be a controlled set of native speaker undergraduates. They will have the same conditions as the first level callers. The third level will be reserved for the systems that perform well enough, by some objective measure, that they can be used with real callers to the Pittsburgh Port Authority. The whole challenge will be overseen by a group of well-known researchers from a variety of sites and research interests.
The design of this first challenge makes it open to researchers interested in such areas as ASR, turn-taking, system architecture, speech synthesis, error handling, confidence measures, dialogue management, adaptation techniques, statistical modeling and lexical entrainment. There are some research areas that will not be able to be adequately addressed in the first iteration of this challenge. It is our intention to expand the challenge in its following iterations, based on our first experience and the feedback and suggestions from the spoken dialogue community.
A paper on the Spoken Dialogue Challenge will be presented at SigDIAL, and a presentation and discussions will take place at the Young Researchers' Roundtable this fall. The intention is to finalize the challenge details before the end of 2009 and run the first year's challenge in 2010.
Updates and details of the challenge will be posted at the Spoken Dialogue Challnge webpage.
Also a mailing list has been set up for further discussion. To join the list send a message to majordomo@speechinfo.org with the following line in the body of the message
subscribe sdc-discuss
To send messages to the mailing list, email to sdc-discuss@speechinfo.org.
Alan W Black is an associate professor at the Language Technologies Institute in the School of Computer Science at Carnegie Mellon Unversity. He works in the areas of speech synthesis, speech-to-speech translation and spoken dialogue systems.
Maxine Eskenazi is an associate teaching professor at the Language Technologies Institute in the School of Computer Science at Carnegie Mellon Unversity. She works in the areas of spoken dialogues systems and computer assisted language learning.
SLTC Newsletter, July 2009
In machine recognition, low-probability items are unlikely to be recognized. For example, in automatic speech recognition (ASR), the linguistic message in speech data is coded in a sequence of speech sounds (phonemes). Substrings of phonemes represent words, sequences of words form phrases. A typical ASR system attempts to find the linguistic message in the phrase. This process relies heavily on prior knowledge in a text-derived language model and a pronunciation lexicon. Unexpected lexical items (words) in the phrase are typically replaced by acoustically acceptable in-vocabulary items. OOVs (out of vocabulary words) are truly the nightmare of large vocabulary speech recognition, as each of them typically causes not one, but multiple recognition errors (due to language model mismatch).
Researchers of Speech@FIT group at Brno University of Technology (BUT, Czech Republic) are focusing their research effort on the detection of OOVs by combining the posterior probabilities generated by strongly and weakly constrained recognizers [Hermansky2007a]. Time intervals, where these two recognizers do not agree, are candidates to contain OOVs or other events the recognizer did not see in the training (e.g., unusual pronunciations, words with short embedded pauses, and unseen noise). The strongly constrained posteriors are generated by a full large vocabulary continuous speech recognizer (LVCSR) with a language model while weakly constrained ones are produced by a much simpler phone recognizer. A neural net is trained to produce probabilities of misrecognitions due to OOV content.
Initial work was done during the Johns Hopkins University summer workshop in 2007 [Hermansky2007b, Burget2008] on clean read speech from Wall Street Journal, but using a very limited recognition dictionary to introduce OOVs.. BUT recently moved to a more realistic task and verified the proposed approach on the CallHome database of conversational telephone speech [Kombrink2009]. BUT also developed a visualization tool allowing to "see" the posteriors and to explain some outputs of the system that were previously considered detection errors (see figure below).
Visualization of posteriors from strongly and weakly constrained systems, and
OOV detection. This example shows the OOV word "Tripoli" recognized as "triple
like".
The research is done under the umbrella of DIRAC (Detection and Identification of Rare Audio-visual Cues) – an integrated project sponsored by the EC under 6th Framework Programme. BUT efforts in DIRAC are led by Prof. Hynek Hermansky, who recently moved from IDIAP Research Institute in Switzerland to the Johns Hopkins University, and is also affiliated with BUT.
Further reading