Welcome to the Summer 2010 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter.
In this issue we are pleased to provide another installment of brief articles representing a diversity of views and backgrounds. This issue includes articles from 6 guest contributors, and our own 8 staff reporters and editors.
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions. You can reach us at speechnewseds [at] listserv (dot) ieee [dot] org.
Finally, to subscribe the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Jason Williams, Editor-in-chief
Pino Di Fabbrizio, Editor
Martin Russell, Editor
Chuck Wooters, Editor
SLT 2010, ASRU 2011, and IEEE awards.
The IEEE Signal Processing Society, our parent organization, also produces a monthly newsletter, "Inside Signal Processing".
This article provides an overview and useful links to the NAACL HLT 2010 conference, which included papers spanning computational linguistics, information retrieval, and speech technology. Due to its three-area focus and emphasis on statistical modeling and machine learning, the NAACL HLT conference will be of interest to many SLT readers, who should consider submitting papers to future conferences.
The Semantic Search Workshop (SemanticSearch 2010) was recently held in Los Angeles, CA on June 5th, in conjunction with Human Language Technologies: The 11th Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT-2010). This workshop features a keynote speech by Dr. Ronald Kaplan from the Powerset division of Microsoft Bing, a panel discussion, and six oral presentations. In this article we give an overview of the workshop.
This article reports on a workshop held at NAACL-HLT 2010 in Los Angeles, CA, June 1-6 2010. The workshop was sponsored by Amazon Mechanical Turk and CrowdFlower with two goals in mind: elicit paper submissions through a shared task challenge and create a forum where researchers could share experiments using data annotated via crowdsourcing. A few experiments from the workshop are described to show the reader use cases for this emerging data collection methodology. Leading the efforts to make this workshop possible were Chris Callison-Burch and Mark Dredze, researchers at Johns Hopkins University.
Last month, a NAACL workshop brought together researchers in speech and NLP that use crowdsourcing services like Amazon's Mechanical Turk and Crowdflower. We had a chance to interview the organizers about the workshop, the future of speech-related work on Mechanical Turk, and the prospects of unsupervised learning given the rise of crowdsourced data.
In the UK 90% of blind and partially sighted people "watch" TV every two days. The current interfaces available for digital TVs and set-top boxes limit their user experience as 60% cannot use on-screen menu navigation. This article discusses ongoing efforts in the digital television industry to improve accessibility by using text-to-speech synthesis to voice the digital TV information.
The U.S. National Institute for Standards and Technology (NIST) sponsored a speaker recognition evaluation in Spring 2010. This article describes the evaluation tasks, data, participant algorithms, and results.
The rise of computer technology has influenced research in all disciplines, including the humanities. Humanities research that uses language technology includes classical lexicography with computational linguistics and authorship attribution using machine learning methods.
Children are the potential beneficiaries of some of the most compelling applications of speech and language technology. This article gives a brief overview of some of the challenges posed by automatic recognition of children's speech and indicates relevant activities in the speech and language technology research community.
The use of Conditional Random Fields (CRFs) in speech recognition has gained significant popularity over the past few years. In this article, we highlight some of the main research efforts utilizing CRFs.
One-on-one tutoring allows students to receive personalized attention and is found more effective than classroom learning. In a classroom, where one teacher presents material to 20 or 30 students, each student receives less personalized attention. Providing a personal tutor for each student is expensive and infeasible. Can automatic tutoring systems provide instructions, support, and feedback to a student and play the role of a one-on-one tutor? This and other educational system-related questions were addressed at the tenth conference on Intelligent Tutoring Systems (ITS) that took place in June, 2010 in Pittsburgh, USA.
Phonetic Arts supplies speech synthesis technologies to the games industry. This article provides an overview of the benefits and challenges of applying speech synthesis to games, and gives an overview of Phonetic Arts' approach.
SLTC Newsletter, July 2010
July is here and for many in our community this is a relatively quiet time of year. ICASSP in Dallas seems a long time ago, the flurry of paper writing activity required to justify a visit to Japan in September is done and dusted, and the SLT submissions are on their way. So apart from the distraction of vacations, there are now a few weeks to reflect, catch-up on those research papers that you copied but never quite got the time to read and maybe chase some new ideas before the light evenings disappear and the ICASSP 2011 deadline looms.
Whilst ICASSP remains the flagship event for our community, our annual December workshop is also very important to us in providing an opportunity for more focussed presentations and discussion. For the last few years, we have alternated between the topics of Automatic Speech Recognition and Understanding (ASRU) and Spoken Language Technology (SLT). In 2010 we will have SLT in Berkeley, California and in 2011 we will have ASRU in Hawaii. In practice, both these workshops have operated on a broader remit than their names might suggest and topics such as synthesis and dialogue systems have appeared in both. Nevertheless, our focus on ASRU and SLT leaves major topics within our area largely untouched, for example, speech analysis and perception, enhancement, coding, etc. So recently the SLTC has been considering whether or not the call for future workshops might be broader in scope allowing potential organisers to select their own focus area. We could for example simply call it the the IEEE Speech and Language Workshop and have a differing focus every year. As yet, the TC have reached no conclusion on this debate, so if you have thoughts of your own, please email me and I will circulate them to the committtee.
About this time last year, I urged everyone in our community to be proactive in nominating colleagues for IEEE Awards. In the event we didn't do too badly. Isabel Trancoso received a Meritorious Service Award and Shri Narayanan was appointed as a Distinguished Lecturer. Shri also won a Best Paper award with Chul Min Lee, and Tomoki Toda won a Young Author Best Paper award. Our congratulation go to all of the aforementioned. However, I am sure that we can do even better next year so please help your TC by suggesting candidates. I would particularly like to hear about any speech and language papers published in our transactions which you think deserve a best paper award. So whilst you are doing that catch-up reading, please make a note of any TASLP paper that really makes an impression on you and let me know.
This will be my penultimate newsletter item as Chair of the SLTC. Next year our Vice-chair, John Hansen takes over as Chair. That also means that as well as electing new members to the TC to replace retiring members, we must also elect a new Vice-chair. Yannis Stylianou and the Member Election subcommittee will be dealing with this. Any elected member or ex-member of the TC is eligible to stand, so if you have a candidate in mind, please contact Yannis (yannis@csd.uoc.gr).
Steve Young
sjy@eng.cam.ac.uk
Steve Young is Chair, Speech and Language Technical Committee.
SLTC Newsletter, July 2010
This article provides an overview and useful links to the NAACL HLT 2010 conference, which included papers spanning computational linguistics, information retrieval, and speech technology. Due to its three-area focus and emphasis on statistical modeling and machine learning, the NAACL HLT conference will be of interest to many SLT readers, who should consider submitting papers to future conferences.
The North American Chapter of Association for Computational Linguistics - Human Language Technologies (NAACL HLT 2010) conference was recently held on June 1–6, 2010 in downtown Los Angeles at the Millennium Biltmore Hotel. This conference included papers on innovative high-quality work spanning computational linguistics, information retrieval, and speech technology. This year there was a special "Noisy Data" theme to acknowledge the significant work taking place across several disciplines with non-pristine data. This conference, due to its three-area focus together with a heavy dose of statistical modeling and machine learning, should be of interest to SLT members.
The program contained pre-conference tutorials, oral and poster presentations of full (8 pages plus 1 for references) and short papers (4 pages), application demonstrations, a student research workshop, and post-conference workshops. For a look at the conference program please see the program. The conference had three sub-parts:
The conference had the benefit of two interesting and diverse keynote presentations: Steve Renals, University of Edinburgh, Recognition and Understanding of Meetings and David Temperley, University of Rochester, Music, Language, and Computational Modeling: Lessons from the Key-Finding Problem. See the keynote web page for talk abstracts and presentation slides. In addition, there was a panel session reflecting the noisy data conference theme: Recent and Future HLT Challenges in Industry, chaired by Kristina Toutanova. Two excellent papers were selected by committee for best paper awards this year: Best Full Paper- Coreference Resolution in a Modular, Entity-Centered Model, by Aria Haghighi and Dan Klein, and Best Short Paper- "cba to check the spelling": Investigating Parser Performance on Discussion Forum Posts, by Jennifer Foster.
Electronic versions of the papers from the main conference, short papers on demonstrations, papers from the Student Research Workshop, and Tutorial abstracts can be found by following the link to the ACL anthology . Overall the conference program was quite strong.
The Association for Computational Linguistics (ACL) Executive Board began the task of establishing the NAACL Chapter in 1997, and the first NAACL Executive Board was elected in December of 1999. The NAACL chapter, once established, determined to hold a domestic conference every year that neither an ACL nor COLING conference would be held in North America. The NAACL conference was first convened in Seattle in 2000, and then annually except when ACL was held in North America. In 2003, NAACL was combined with the Human Language Technology (HLT) conference series. The HLT conferences brought together cross-disciplinary researchers focused on enabling computers to interact with humans using natural language and to provide them with language services (e.g., translation, speech recognition, information retrieval, text summarization, and information extraction). The combination of the two conference series has been successful in providing a unified forum for the presentation of high-quality, cross-disciplinary, cutting-edge work and in fostering new research directions.
I would like to thank the NAACL HLT 2010 general chair, Ronald Kaplan, my program co-chairs, Jill Burnstein and Gerald Penn, the local arrangements co-chairs, David Chiang, Eduard Hovy, Jonathan May, and Jason Riesa, who, among many other tasks, developed the NAACL HLT 2010 website, the publication co-chairs, Claudia Leacock and Richard Wicentowski, who prepared the proceedings for the conference and the ACL Anthology, and the many other people who contributed in various ways to the conference. I would also like to thank Giuseppe Di Fabbrizio for his input on this article.
Mary Harper was a technical program co-chair for NAACL HLT 2010. She is an Affiliate Research Professor in Computer Science and Electrical and Computer Engineering at the University of Maryland and a Principal Research Scientist at the Human Language Technology Center of Excellence at Johns Hopkins University. Her research focuses on computer modeling of human communication involving audio, textual, and visual sources. Email: mharper@umd.edu, Web: http://www.wam.umd.edu/~mharper
SLTC Newsletter, July 2010
Last month, a NAACL workshop brought together researchers in speech and NLP that use crowdsourcing services like Amazon's Mechanical Turk and Crowdflower. We had a chance to interview the organizers about the workshop, the future of speech-related work on Mechanical Turk, and the prospects of unsupervised learning given the rise of crowdsourced data.
Crowdsourcing has seen a dramatic rise in popularity recently. With its growth has come the emergence of several tools that allow data collection and annotation to be serviced by a large workforce - one willing to perform these tasks for monetary compensation. Our previous article discussed the benefits of using one crowdsourcing tool, Amazon's Mechanical Turk (MTurk for short), for speech transcription. Other crowdsourcing examples include Crowdflower, CastingWords, HerdIt, reCAPTCHA, and Wikipedia.
Last month, a NAACL workshop brought together researchers in speech and NLP that use crowdsourcing. The "Creating Speech and Language Data with Amazon's Mechanical Turk" workshop provided a forum for crowdsourcing researchers to share cutting-edge research in a variety of topics, including research using crowdsourcing, toolkits to use with MTurk, and lessons learned. Leading the efforts to make this workshop possible were Dr. Chris Callison-Burch and Dr. Mark Dredze, researchers at Johns Hopkins University.
We had a chance to interview Chris and Mark about the workshop.
SLTC: Would you consider the workshop a success? What do you think attendees learned most from the workshop?
Mark Dredze:
Yes! We had a huge attendance, great participation, many positive comments and people who want to do it again. I think the best outcome was the sharing of best practice knowledge among the participants. It was clear many people had learned valuable lessons in how to use MTurk. I know I learned a lot about how to attract turkers (pay turkers to recruit other turkers, advertise in the the turkers' native language), cultivate a trained workforce (pay people bonuses, use qualification HITs, write detailed directions), and how to break up tasks into manageable chunks (think of short HITs that don't require much training, chain many HITs together to get a more complex output). I got to meet other people doing similar things to what I am doing, and we shared ideas and advice.
Chris Callison-Burch:
Another significant takeaway was the importance of quality control and of the design of the HITs. The contributors on Mechanical Turk (and on most other crowdsourcing platforms) are not known to the person requesting the work. Consequently, we can't assume things about them. We can't assume that they are experts in any particular subject area. We can't assume that they are paying close attention. We can't assume that they are behaving in a conscientious fashion, and not simply randomly clicking. Therefore it is important to design the tasks so that (a) they have clear, concise instructions that non-experts can understand, (b) we insert quality control checks, preferably with gold standard data, that will allow us to separate the bad workers from the good workers (and there are a surprisingly high number of good workers on Mechanical Turk). I think that an excellent way of accomplishing both of these things is to iteratively design the task, to do many of the items yourself and to ask friends from outside your field to try it before doing a large-scale deployment on MTurk. That will give you a sense of whether it's doable, and will let you collect some "gold standard" answers that you can insert into the Turk data to detect cheaters. Another route is redundant annotation of the same items. Because labor is so cheap on Mechanical Turk, it's perfectly feasible to redundantly label items and take a vote over labels (assuming that Turkers perform conscientiously in general, and that their errors are uncorrelated).
For complex tasks, it is also a good practice to break them down into smaller, discrete steps. For instance, in my EMNLP-2009 paper [1], I used Mechanical Turk to test the quality of machine translation using reading comprehension tests. I did the entire pipeline on Mechanical Turk, from having Turkers create and select the reading comprehension questions, to administering the test by having other Turkers answer the questions after reading machine translation output, to hiring Turkers to grade the answers. It was a simple pipeline, but it allowed me to accomplish a complex task in a creative way.
SLTC: What do you foresee as the future of speech-related work with Mechanical Turk?
MD:
Certainly, if we want to collect speech data, this is a good way to get a huge diversity of data (different languages, accents, dialects, background noise). Most speech training data is fairly clean and consistent. This tackles the problem from the opposite end. The data you could collect is so diverse, it makes the problem much more challenging, and realistic. You can also use MTurk for speech annotation, etc, and I think Chris's NAACL paper [2] speaks to that.
CCB:
Transcribing English data is perfectly feasible on Mechanical Turk. It's unbelievably inexpensive. In the paper that I wrote with Scott Novotney, a PhD student here at Hopkins, we collected transcriptions at the cost of $5 per hour of transcription. Let me say that it again. It cost us $5 per hour transcribed. This is a tiny fraction of the cost that we normally pay professionals to transcribe speech. The costs are so low, that a successful business, CastingWords, has sprung out of doing transcription on Mechanical Turk.
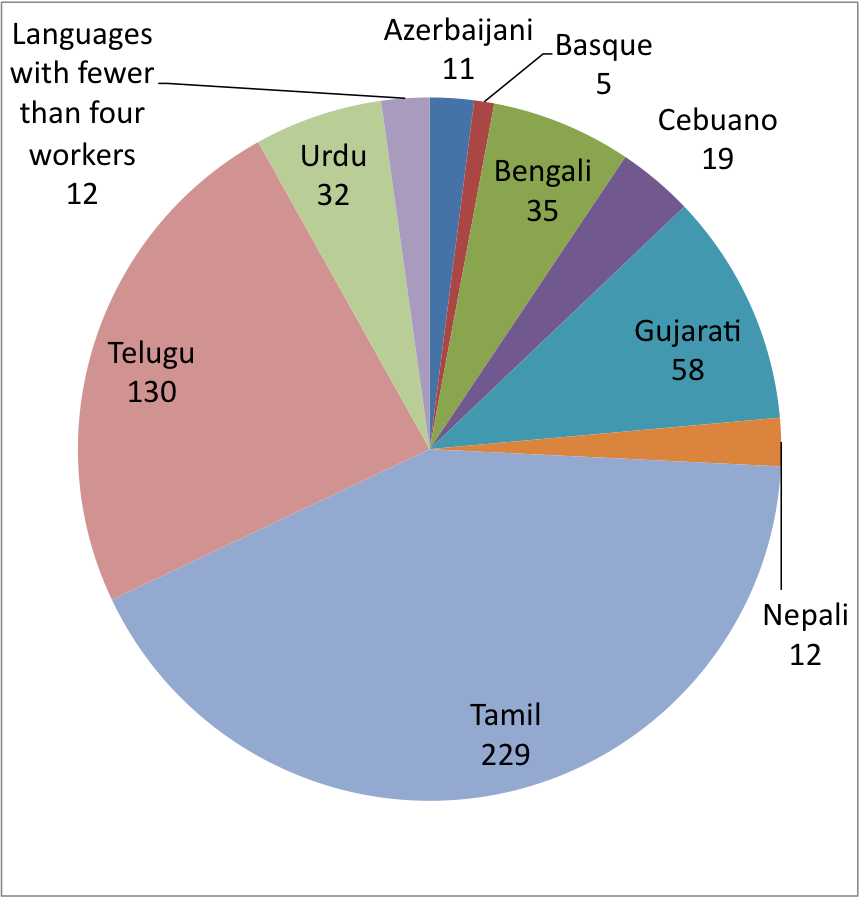
In my opinion, English is not so interesting. Personally, I'm really interested in diversifying to languages that we don't already have thousands of hours worth of transcribed data. I'm interested in creating speech and translation data for low resource languages. It is still an open question as to whether we can find speakers of our languages of interest on Mechanical Turk. To that end, I have been collecting translations for a number of languages to see if it is feasible. So far I have experimented with using Mechanical Turk to try to solicit translations for Armenian, Azerbaijani, Basque, Bengali, Cebuano, Gujarati, Kurdish, Nepali, Pashto, Sindhi, Tamil, Telugu, Urdu, Uzbek, and Yoruba. My initial experiments were simply to determine whether there were any speakers of those languages on MTurk by asking them to translate a list of words, and asking them to self-report on what languages they speak.
Here is the breakdown of the number of speakers of each language from Chris's initial results:
SLTC: You both mentioned in the overview workshop paper [3] that the affordability of collecting MTurk data means that unsupervised learning work may lose popularity. Can you share your viewpoints on this issue?
MD:
This is a point of disagreement between us. I still think there is a big market for unsupervised learning. MTurk has its limits, and not every task can be setup on MTurk. Instead, I think that there are many problems for which we want supervised solutions, but its difficult to invest in the data. Those problems, which may not be studied at all at the moment, will get attention as we can quickly generate data for those tasks.
CCB:
Yes, we disagree on this point. In general, labeled training data is exponentially more valuable than unlabeled training data. Many conference papers about unsupervised learning motivate the research by claiming that labeled training data is too hard to come by or too expensive to create. Mechanical Turk lets us create data extremely cheaply. My conclusion is that if we want to actually make progress on a task, we ought to collect the data. That has a greater chance of succeeding.
I think that it also gives rise to other interesting research questions: Can we predict the goodness of an annotator? If we solicit a redundant label what is the chance that it'll be better than the ones that I have collected so far? It also opens up interesting research directions in semi-supervised learning and active learning, as opposed to fully unsupervised learning. Most of the active learning papers that I have read are all simulated. This is a platform that allows you to do real, non-simulated active learning experiments. It would also allow you to test things like whether the items that the model selects for labeling are somehow inherently harder than randomly selected items.
As Chris mentioned, one of the key lessons learned from the workshop was MTurk HIT (Human Intelligence Task) design. The design of MTurk HITs represents a fraction of the work involved in what data collected from MTurk is ultimately used for - but design of the HIT can have a strong impact on the quality of results. In this sense, the HIT designer has the most control over MTurk worker reliability. The general consensus from the workshop was that short, simple tasks are most preferable. The workshop showed that MTurk and other crowdsourcing tools are feasible for a variety of speech and natural language tasks. It should be interesting to see how crowdsourcing as a resource evolves over time in speech and language research.
If you have comments, corrections, or additions to this article, please contact the author: Matthew Marge, mrma...@cs.cmu.edu.
SLTC Newsletter, July 2010
This article reports on a workshop held at NAACL-HLT 2010 in Los Angeles, CA, June 1-6 2010. The workshop was sponsored by Amazon Mechanical Turk and CrowdFlower with two goals in mind: elicit paper submissions through a shared task challenge and create a forum where researchers could share experiments using data annotated via crowdsourcing.
Businesses are using crowdsourcing to scrub their databases, tag images, categorize products and, in general, handle tasks that if performed in-house would be costly, tedious and require long lead times. Researchers in NLP are leveraging turkers, the crowd behind Amazon's service, for annotation and labeling tasks. Crowdsourcing is cost-effective and scalable but one of the major problems faced by requesters, the customers of the Mturk platform, is how to interpret the data retrieved. Turkers may work at random or try to beat the system, by using scripts to accept and complete HITs (Human Intelligence Tasks) automatically.
Many companies are now leveraging e-labor but not all of them want to or can manage the workflow themselves, especially when it comes to data mining. CrowdFlower provides a service whereby customers can make sense of the data pulled from the Amazon workforce and other crowds. The San Francisco startup offers statistically-based quality control technology to its customers, identifying high quality data from the pool of responses and weeding out poor performance or fraudulent activity. Lukas Biewald, the CEO of CrowdFlower, was the invited speaker at the NAACL workshop. He talked about the company's mission, leveraging pools of workers and offering analytics to extract high-quality data. Some of the questions asked focused on the workers' demographics, especially the country of origin. Most turkers, now totaling more than 400,000, are from the United States but there is a growing international population, mostly from India (see [1]).
For the shared task, participants were offered $100 to spend on MTurk and submit papers describing the experiments. The workshop also accepted papers addressing use cases for MTurk and methodologies to process the data. There were 10 oral (general research track) and 25 poster (shared task) presentations. The audience was very engaged; advantages and limitations of the service were equally discussed and there was a general consensus that crowdsourcing is an effective way of collecting labels for NLP tasks, if quality control measures are put in place.
The following are MTurk selected use cases presented at the workshop: speech data collection, word sense disambiguation, polarity assessment for opinion phrases, document relevance assessment, named entity recognition, knowledge extraction and word alignment for machine translation.
Several presentations at the workshop focused on using crowdsourcing for speech data. Kunath and Weinberger ([2]) conducted an experiment that had MTurk workers determine the native language of non-native English speakers (either Mandarin, Russian, or Arabic). The researchers found worker ratings to be of generally high quality, with promising consistency. Other work focused on the potential of using MTurk for collecting speech data. Novotney and Callison-Burch ([3]) accomplished one such task: they tasked MTurk workers with recording narrations of Wikipedia articles on their own. While MTurk was shown to be unreliable for collecting long narrations from most workers, this work highlighted the strengths of using the "crowd" to locate proficient narrators.
Mellebeek et al. ([4]) wanted to see if they could collect data to train their opinion mining module to detect polarity. The researchers were concerned about whether turkers would be as accurate as experts and whether they could collect enough Spanish data given the turker pool comprises mostly English speakers. Inter-annotator agreement scores were moderate, but when using majority voting to select the best labels and comparing these to expert annotations scores jumped higher. The number of assignments, that is, labels requested per HIT, is a variable that experimenters can and need to set to ensure they can extract high quality data.
Another interesting experiment was conducted by Lane et al. ([5]). The researchers developed a Java applet to collect speech on MTurk. They collected two sets of data; one set using English speaking paid subjects and another using Haitian Creole volunteers. The English speakers were recorded in a controlled environment to minimize low quality audio data and were assisted during the utterance collection. The Haitian Creole speakers were recorded in an unsupervised setting. Only 10% of the data from the English speakers was considered unfit for training acoustic models, while 45% of the Haitian Creole data was deemed unusable. The researchers conclude that proper training will bridge this gap. Developers of multilingual speech applications may want to turn to MTurk when their only option is remote data collection, as it may be the case with lesser spoken languages.
Evanini et al. ([6]) and Marge et al. ([7]) built on past work that used MTurk for speech transcription. Evanini et al. explored several techniques for combining multiple (3-5) transcriptions to improve the overall accuracy of non-native English speech transcriptions. They found that combining transcriptions produced transcriptions of read speech that were as accurate as those from expert transcribers. For spontaneous speech, combining multiple MTurk workers yielded transcriptions of marginally lower quality. Marge et al. focused on speech transcription and annotation in the meeting domain. Their transcription work explored using iterative posts of transcription tasks, where an initial pair of transcriptions of spontaneous speech were aligned, and reposted as a new task for workers to correct. The iterative approach proved promising, especially when used in combination with already-existing combination techniques. Their annotation task explored having MTurk workers perform an atypically long task - rating the noteworthiness of each utterance (transcribed in-house) from a meeting. Results found that despite the lack of training, turker annotations were in agreement with in-house trained annotators, especially when combined with a voting scheme.
In the last experiment we describe Finin et al. ([8]) collected annotations for named entities found in Twitter messages. One of the emerging uses of MTurk by the NLP community is the labeling of textual data found in social networking sites and feeds. The authors wanted to see if turkers would be as accurate as experts when labeling entities within this more informal linguistic domain. The authors used both MTurk and CrowdFlower to submit HITs in order to compare the two services. Crowdflower offers an analytics and turker management interface absent in MTurk; an obvious question is whether the former platform offers features that are worth paying for. The authors conclude that when using MTurk, performing agreement score calculations and leveraging a golden set of pre-annotated data are sufficient to obtain high quality data. For the unsophisticated requester CrowdFlower may be a great alternative though.
As an outcome of the workshop the researchers provided MTurk and CrowdFlower with feedback for improving their product. One comment from the audience encouraged opening up to requesters outside of the United States more formally. At present CrowdFlower allows one to fund accounts with a credit card so in theory requesters can reside anywhere, but in practice there is no international support yet. The Mturk and Crowdflower sites are in English only. Another topic discussed, which may be of interest to researchers applying for grants, was the use of turkers as research subjects and therefore whether institutional review boards' protocols should apply. A few members of the audience have gotten exemptions from institutional review boards so for the time being researchers can leverage MTurk if they properly document and apply for such exemptions.
Crowdsourcing is emerging as a cheap, flexible, fast method to obtain labels for NLP tasks. With increased use by the research community there will be an increase in the number of tools developed to analyze data and manage worker pools. Stay tuned for more conferences offering tutorials and workshops on the use of crowdsourcing (a workshop on crowdsourcing for search evaluation will be held in Geneva during the 33rd Annual ACM SIGIR Conference on July 23rd, 2010.)
Sveva Besana is a Research Engineering Manager at AT&T Interactive. Email: sbesana@attinteractive.com
Matthew Marge is currently pursuing a PhD in Language and Information Technologies at Carnegie Mellon University. His research interests include spoken dialog systems, human-robot interaction, crowdsourcing for natural language research, and natural language generation. Email: mrma...@cs.cmu.edu.
SLTC Newsletter, July 2010
In the UK 90% of blind and partially sighted people "watch" TV every two days. The current interfaces available for digital TVs and set-top boxes limit their user experience as 60% cannot use on-screen menu navigation. This article discusses ongoing efforts in the digital television industry to improve accessibility by using text-to-speech synthesis to voice the digital TV information.
It may appear slightly contradictory but a survey by the Royal National Institute for the Blind (RNIB) has shown that 75% of blind and partially sighted people “watch” TV every day with 90% watching every two days [1]. However the current interfaces available through digital TVs and set-top boxes (TVs will be used to refer to digital TVs, connected TVs and set-top boxes in the rest of this article) limits their user experience. 60% cannot use on-screen menu navigation so they are restricted to using up/down channel buttons or remembering the channel number to navigate. Not the quickest or most convenient of methods when the number of channels is in the tens and hundreds! The number of people with partial sight and blindness in the UK is estimated to be between 1.8 [2] and 2.7 million [3] so there are a substantial number of people whose viewing experience could be enhanced. And the problem will continue to grow – projections show that this figure will grow to approximately 3.99 million by 2050.
A number of partially sighted and blind people access electronic programme guides (EPG) today through their PCs where they have access to text-to-speech synthesis (TTS) to voice the information. Television industry groups in the UK and Europe are working on adding the same functionality to TVs. With TTS, many more viewers will be able to find out more about the programme they’re watching, what’s on now and next, control their digital video recording etc. 88% of those questioned by the RNIB said they would use an audible guide if available [1].
The industry association for digital television in the UK, the Digital TV Group (DTG), published a white paper on implementation guidelines and recommendations for TTS for TVs in December 2009 [4]. Although the DTG’s remit is for the UK, the proposals should be applicable to many countries. Two approaches to provide TTS are envisaged: embedded in the TV; a separate standalone unit. The DTG white paper attempts, from a user requirements perspective, to outline the minimum requirements each TTS enabled product should adhere to, e.g. the logical channel/service number should be spoken. Implementation guidance is given on what type of text should be spoken and when for both static data such as the service name e.g. “BBC1” and dynamic data such as the current programme information e.g. “3 ITV1 Coronation Street 7.30-8pm”. The interface and protocol between the external TTS box and the TV is being considered by groups such as DIGITALEUROPE, the European digital economy advocacy group for information technology, consumer electronics and telecommunications.
Hopefully we should start seeing TTS available as an option in set-top boxes and TVs within the next couple of years.
Thanks to Raheel Mallick and Edward Chandler of the RNIB for providing input to this article.
Kate Knill is Assistant Managing Director and Speech Technology Group Leader of Toshiba's Cambridge Research Lab. Her interests are speech recognition and speech synthesis. Email: kate.knill@crl.toshiba.co.uk.
SLTC Newsletter, July 2010
The United States National Institute for Standards and Technology (NIST) sponsored a speaker recognition evaluation (SRE) in the spring of 2010. The evaluation concluded with a workshop at Brno University of Technology, Brno, Czech Republic 24-25 June. The 58 participants in this year’s evaluation were from five continents and submitted 113 core systems. At the June workshop participants described their algorithms, NIST reported on evaluation results, and all participants engaged in joint discussions regarding data, performance measures, current and future tasks. This was the thirteenth SRE since 1996.
As in to previous years, the SRE 2010 evaluation consisted of one required task and eight optional tasks with varied amounts of training and recognition data. The required task focused on the “core” condition for training and recognition: one five-minute speech segment from either a telephone conversation or an interview for both training and recognition. The optional tasks were combinations of training with 10-seconds of speech, one five-minute conversation, and eight five-minute conversations (summed and individual sides), or and testing with 10-seconds of speech, one five-minute conversation, or a 2-wire (summed) five-minute conversation.
NIST introduced a pilot task, human assisted speaker recognition (HASR), in the 2010 evaluation. The goal of this new task was to create a reasonable baseline for future research on forensic-like examination of voices using both human and automated systems. In this pilot, humans and systems could work separately or in combination to same/different decisions on pairs of speech samples about three minutes long. Both experienced and naïve listeners from 15 sites participated.
NIST modified the evaluation metric this year to focus on the low false-alarm region of the detection error tradeoff curve for the core task and the eight-conversation train/test task by decreasing the both cost of a miss (from 10 to 1) and the target probability (from 0.01 to 0.001). The new cost function caused the minimum cost operating point to be between 0.01% and 0.1% false alarm percentage.
Most participants submitted fused combinations of Gaussian mixture models and support vector machines trained on Mel-frequency cepstral coefficients, with variations of joint factor analysis to counter the limited training data and multiple channel conditions. Calibration seemed to be more difficult with the new performance measurement. Some systems leveraged the automated speech recognition transcripts provided by NIST, and a few systems modeled prosodic features or phonetics.
One of the challenges of this year’s evaluation was determining how to use existing data to train the non-speaker-specific components of the systems, including background models, voice and channel factors, nontarget statistics, and nontarget test models.
This year’s evaluation set contained considerably more core trials than previous years, over 570,000. Additionally, there were nearly 6.5 million core-extended trials, needed to provide more statistical significance at the low false-alarm rates for the new evaluation metric.
New this year in the data were various levels of vocal effort by the speakers and conversations from speakers who also participated in older speaker collections. Repeated this year in the data were various microphones (seven this year) and both conversational and interview sessions. The training and testing sessions contained both matched and mismatched conditions across these elements.
NIST selected two subsets of the core test for the HASR data. HASR1 contained 15 trials, and HASR2 contained 150 trials. HASR1 data was a subset of HASR2 data. These subsets were chosen to be especially difficult for both humans and machines.
The best-performing systems provided equal error rates at or below 2% in the core conditions. As expected, the performance for the matched microphone conditions was better than for the mismatched microphone conditions. Unexpectedly, though, the top systems performed better when training on normal vocal effort and testing on low vocal effort than when testing on normal vocal effort.
The effects of aging on voice could not be clearly distinguished, partly due to limited data. Only 14 speakers participated in collections more than ten years old, and most of the speakers participated in collections less than three years old.
Performance on the HASR pilot surprised many: on these data, automated systems generally performed better alone than with human assistance. Error rates of 15-30% were typical for human listeners. It is important to note the data did not represent a typical forensic task in detail, but the results should provide an interesting starting point for much relevant research in this area.
NIST normally holds speaker evaluations and workshops in even-numbered years alternating with language evaluations and workshops in the odd years.
Thanks to Alvin Martin and Jack Godfrey for providing input to this article.
You can learn more about NIST’s speaker recognition evaluations at NIST speaker recognition evaluation web page, http://www.nist.gov/itl/iad/mig/sre.cfm.
If you have comments, corrections, or additions to this article, please contact the author: Tina Kohler, m.a.kohler [at] ieee [dot] org.
Tina Kohler is a researcher for the U.S. Government. Her interests include speaker and language processing.
SLTC Newsletter, July 2010
The rise of computer technology has influenced research in all disciplines, including the humanities. Humanities research that uses language technology includes classical lexicography with computational linguistics and authorship attribution using machine learning methods.
One of the first examples of language technology for humanities research was for the development of dictionaries, concordances, and similar research tools. Bamman and Crane (2009) provide a recent example in the Classics, describing the development of lexical resources in Latin and Greek literature. They describe traditional methods of reference work development, emphasizing the manual labor and the level of expertise of those doing the developing, as well as the tasks such as finding word examples in texts, clustering them by 'sense', and and labeling those senses. They note a key difference between classical text collections and modern corpora: "The meaning of the word child in a single sentence from the Wall Street Journal is hardly a research question worth asking, except for the newspaper's significance in being representative of the language at large; but this same question when asked of Vergil's fourth Eclogue has been at the center of scholarly debate since the time of the emperor Constantine". However, although certain texts and certain time periods (such as the Golden and Silver age in Latin literature) have been extensively studied to provide lexical resources such as definitions with "word in context" text excerpts and references, there are several centuries worth of texts that have not been so analyzed. In large part this is because of the expertise required in the time-consuming process of collecting citations in classical languages and merging them into distinct senses.
To complement the centuries' worth of expertly-crafted resources that currently exist, computational lexicography emerged in the late 1980s. Computational lexicography has produced resources on increasingly large corpora, and has used more complex algorithms to extract information regarding, for example, grammatical features. Bamman and Crane describe their vision of a lexical resource that includes a word's possible senses, a list of usage of each sense in the source texts, subcategorization frames, and selectional preferences by author. Bamman and Crane describe their work in developing such a resources. They use parallel texts (translations in different languages of the same text) to do word sense induction; this involves automated sentence and word alignments, which are then used to calculate translation probabilities. They also use parallel texts to train Bayesian classifiers for word sense disambiguation, and are creating treebanks in classical languages to develop parsers to study lexical subcategorization and selectional preference. In this way, they plan to produce tools that allow students a richer learning resource, and that allow scholars in the Classics to interact with the texts in more powerful ways.
Another humanities research area with a (relatively) long history is authorship attribution, in which a text's author is identified using a classifier and a training corpus of texts with known authors. Jockers and Witten (2010) note that unlike typical cases, classification here involves the style, rather than the content, of a document. They survey the field, note a consensus on high-frequency words and/or n-grams as the choice of features, and decry the lack of thorough comparisons of the relative effectiveness of the various possible classification algorithms. To fill this void, they compare a number of classification methods (k-nearest neighbors, support vector machines, nearest shrunken centroids, regularized discriminant analysis, and Delta) on a prototypical authorship attribution task: identifying the authorship of various disputed elements of the Federalist Papers of the American colonial era. On cross-validation and test data, they find that nearest shrunken centroids and regularized discriminant analysis perform best, and suggest they are worth applying further, as they had not been previously used for this task.
In these and other ways, humanities research continues to benefit from applying techniques from engineering and the sciences.
For more information, see:
SLTC Newsletter, July 2010
Children are the potential beneficiaries of some of the most compelling applications of speech and language technology. This article gives a brief overview of some of the challenges posed by automatic recognition of children's speech and indicates relevant activities in the speech and language technology research community.
Researchers in automatic speech recognition (ASR) have been interested in the challenge of computer recognition of children's speech since at least the early 1990s. The motivation is clear - children are the potential beneficiaries of some of the most compelling applications of speech and language technology in education. These include interactive tutors for reading, such as those developed in Project LISTEN [1] at Carnegie Mellon University in the USA, pronunciation coaching [2], and educational games. Unfortunately, it turns out that automatic speech recognition (ASR) is substantially more difficult for children's speech than for adults' speech. For example, in 1998 Wilpon and Jacobsen [3], reported the results of digit recognition experiments using acoustic models trained and tested on a range of age groups. They found that error rates were between 150% and 340% greater for children than for adults. Even if the system was trained on children's speech, error rates for children's speech were between 60% and 176% greater than one would expect for adults.
Clearly, some of the mismatches between child and adult speech stem from physiological differences. Children's vocal tracts are smaller than those of adults, so that important structure in children's speech occurs at higher frequencies. This is well illustrated by studies of children's vowel formant frequencies, such as that reported by Narayanan and Potamianos in 2002 [4]. Their results show an almost linear decrease in formant values along with a general 'compacting' of the vowel space as age increases. One of the implications of these findings is that any reduction in bandwidth will have a much greater effect on child speech than adult speech. For example, studies have shown that if bandwidth is reduced from 8kHz to 4kHz (telephone bandiwidth) the resulting increase in ASR error rate is more than 100% greater for children than for adults [5]. If there are no bandwidth restrictions these differences can be accommodated by Vocal Tract Length Normalisation (VTLN). However, if bandwidth is restricted the utility of VTLN is compromised.
Another explanation of the difficulty of automatic recognition of children's speech is the high level of variability in child speech compared with adult speech. In 1999 [6], Lee, Potamianos and Narayanan presented a comprehensive study of the magnitude and variation of a range of acoustic speech parameters as a function of speaker age. Their experiments showed higher levels of variability for children's speech, converging to those for adults between the ages of 12 and 15 years. There is also some evidence that this variability is not distributed uniformly across all children, and that ASR performance for a particular child is correlated with a teacher's judgement of pronunciation ability [7].
An obvious approach to reducing ASR error rates for children's speech is to apply generic adaptation techniques, such as Maximum A Posteriori (MAP) or Maximum Likelihhod Linear Regression (MLLR) adaptation, in addition to VTLN. Since the goal of the majority of effort in ASR research has been to improve systems for adult speech, these techniques are particularly useful to raise the performance of these 'adult' systems on children's speech. However, the results of this approach are unlikely to exceed the performance of a system trained on children's speech, and it has already been noted that this is substatially poorer than one would expect for adults.
Variability in adult speech arises as a consequence of many factors, including natural, conscious and subconscious variations in the production of individual sounds, variations in the 'inventory' of sounds and the ways in which they are used (for example, due to social and educational factors or a regional accent), and possibly variations due to an individual's level of speech production proficiency. For children the latter issue is potentially a major consideration. Speech acquisition by children, or the chronological sequence of stages at which children acquire the ability to produce individual or combinations of speech sounds accurately, is well documented in the speech therapy and phonetics literature, but largely ignored by the ASR community. McLeod and Bleile [8] present a detailed overview with an extensive bibliography. It is natural to ask whether this knowledge is computationally useful, and if so, how it can be used. For example, can speech development factors which can be characterised at the phonetic or phonological level explain the large variability in children's speech relative to adults' speech, or is variability due to these developmental factors swamped by variability due to poor articulator control?
It is interesting to speculate that efforts to develop computational frameworks to accommodate the evolution of speech production proficiency in children might lead to a better understanding of how to model the development of speech perception in children, and this, in turn, might lead to more 'human-like' approaches to general ASR.
Developments in research in speech technologies for children are reported at the major speech and language technology conferences. Relevant Special Sessions at past conferences include Speech technology in education at Interspeech 2006, Pittsburgh, 'Age and gender issues in speech technology' at Interspeech 2005, Lisbon, and 'Speech Technology for e-Inclusion' at Eurospeech 2003 in Geneva. Aspects of this topic which relate to education fall within the interests of the ISCA Special Interest Group on Speech and Language Technologies in Education (SLaTE) (see also SLaTE 2007, SLaTE 2009, L2WS2010 and the previous issue of this Newsletter). Of course, speech is just one component of the general Child-Computer Interface, and since 2008 the topic of speech technologies for children has been part of annual Workshops on Child-Computer Interaction (see WOCCI-2008, WOCCI-2009 and WOCCI-2010). A Special Issue of the ACM Transactions on Speech and Language Processing on the topic of Speech and Language Processing of Children's Speech for Child-machine Interaction Applications is currently in preparation.
For more information, see:
[1] J. Mostow, S.F. Roth, A.G. Hauptmann and M. Kane, A prototype reading coach that listens, In Proc. 12th National Conf. on Artificial Intelligence (AAAI'94),
Seattle, WA, pp 785-792, 1994.
[2] M J Russell, R W Series, J L Wallace, C Brown and A Skilling, The STAR system: an interactive pronunciation tutor for young children,
Computer Speech and Language, Vol. 14, Number 2, 161-175, April 2000.
[3] J. Wilpon and C. Jacobsen, A study of speech recognition for children and the elderly, Proc. ICASSP’96, Atlanta, USA, 1996.
[4] S. Narayanan and A. Potamianos, Creating conversational interfaces for children, IEEE Trans. Speech and Audio Proc., Vol. 10, No. 2., 65-78, 2002.
[5] M J Russell, S. D'Arcy and Li Qun, The effects of bandwidth reduction on human and computer recognition of children's speech,
IEEE Signal Processing Letters, Vol. 14, Number 12, pp 1044-1046, December 2007
[6] S. Lee, A. Potamianos and S. Narayanan, Acoustics of children's speech: Developmental changes of temporal and spectral parameters,
Journal of the Acoustical Society of America, Vol 10, 1455-1468, 1999.
[7] Q. Li and M. Russell, An analysis of the causes of increased error rates in children's speech recognition, Proc. ICSLP'02, Denver, CO, USA, 2002.
[8] S. McLeod and K. Bleile, Neurological and developmental foundations of speech acquisition, American Speech-Language-Hearing Assoc. Convention, Chicago, 2003 (see: http://www.speech-languagetherapy.com/ASHA03McLeodBleile.pdf).
Martin Russell is a Professor in the School of Electronic, Electrical and Computer Engineering at the University of Birmingham, Birmingham, UK. Email: m.j.russell@bham.ac.uk
SLTC Newsletter, January 2010
The use of Conditional Random Fields (CRFs) in speech recognition has gained significant popularity over the past few years. In this article, we highlight some of the main research efforts utilizing CRFs.
Hidden Markov Models (HMMs), a very popular tool in speech recognition, can be thought of as a generative model. In other words, it provides the joint probability distribution over observation sequences and labels. In contrast discriminative models, such as conditional random fields (CRFs) and Maximum entropy markov models (MEMMS), model the posterior probability of a label sequence given the observation sequence. In a CRF, the conditional probability of an entire label sequence given an observation sequence is modeled with an exponential distribution. CRFs are attractive for a few reasons. First, they allow for the combination of multiple features, perhaps representing different sources of knowledge, while sill providing a discriminative framework. In addition, CRFs are more suited to the use of unconstrained optimization algorithms, which generative models such as HMM are not.
There have been numerous efforts in using CRFs for phone classification. In [1], researchers explored the use of hidden CRFs (HCRFs), which are CRFs with hidden state sequences. This paper focuses on comparing the discriminative benefits of a CRF model to a generative HMM. Training the HCRF is done using stochastic gradient descent. The performance of HCRF is compared to maximum-likelihood (ML) trained HMMs, and maximum mutual information (MMI) trained HMMs on the TIMIT phonetic classification task. The HCRF offers roughly a 4% absolute improvement over the HMM-ML system and 3% over the HMM-MMI system, showing the benefits of a discriminative model compared to a generative model.
[3] explores the benefit that CRFs allow to combine multiple feature streams. Specifically, it looks at a combination of state features and transitions features. Transition features model the dependency between successive sequence labels. More importantly they provide a Markov framework which allows for the selection of the current label to be influenced by the previous labels. State feature functions are used to describe various phonetic attributes for a specific frame, including knowledge of voicing, sonority, manner of articulation, place of articulation, etc. Another advantage of the framework presented in [3] is that unlike HMMs, which assume that the observed data is independent given the labels, CRFs do not make any assumptions about the interdependence of the data.
The paper explores phone recognition in TIMIT, comparing a monophone CRF to a tandem system, which uses the output of a multi-layer perceptron (MLP) as features into a Gaussian-based HMM. In addition, a baseline HMM system using MFCC features was also used for comparison. The CRF is found to offer a 3% absolute improvement over the triphone HMM, a 4% absolute improvement over a tandem monophone HMM system. The CRF system offers comparable performance to a tandem triphone HMM system, but with much fewer parameters.
The use of CRFs for large vocabulary continuous speech recognition (LVCSR) is explored in [5]. This paper explores the use CRFs at the segment level, rather than the frame level which is most common in speech recognition systems. The states in the segmental CRF represent words, and various segmentations are considered which are consistent with the word sequence. The features used within the segmental CRF framework are defined at the segment level, and thus span over multiple observations. A set of multi-scale detector steams are to generate a set of segment-level features. Each detector stream detects a specific feature set and operates at different time scales, include frame, phone, multi-phone, syllable and word level. Having features defined at the word level allows long span features such as formant trajectories, duration, and syllable stress patterns. On the Bing Mobile database, the segmental CRF offers a 2% absolute improvement over an HMM baseline.
The use of discriminative language modeling using CRFs and the perceptron algorithm is explored in [4]. A typical language model to estimate word probabilities is a generative model which tries to maximize the word probabilities. In this paper, the CRF model is encoded as a deterministic weighted finite state automata. The automata is intersected with word-lattices generated from a baseline recognizer, which allows features to be estimated for model updates. The CRF training attempts to directly optimize error-rate, unlike generative methods. Using the CRF method for parameter estimation allows for a 1.8% absolute gain over the baseline generative LM.
Finally, [2] explores the use of CRFs for building probabilistic models to segment and label sequence data. A HMM, a popular choice for segmenting and labeling sequence data, is a generative model which assigns a joint probability to observations and label sequences. This requires enumerating all possible observation sequences, making it difficult to use multiple features or capture long-range dependencies of the observations. In contrast to generative models, discriminative models such as CRFs and MEMMs do not require a lot of effort on modeling the observations. In MEMMs, the output label associated with a specific state is modeled with an exponential distribution. Modeling in this fashion leads to something known as the label bias problem, where transitions which leave a state can only compete against each other rather than other transitions in the model. CRFs address the label bias issue with MEMMs by using a single exponential model for the entire label sequence given observation sequence. The authors compare CRFs to MEMMs and HMMs on a part-of-speech tagging task, and observe improvements using the CRF approach.
For more information, please see:
[1] A. Gunawardana, M. Mahajan, A. Acero and J. C. Platt, "Hidden Conditional Random Fields for Phone Classification," in Proc. Interspeech, 2005.
[2] J. Lafferty, A. McCallum and F. Pereira, "Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data," in Proc. ICML, 2001.
[3] J. Moris and E. Fosler-Lussier, "Combining Phonetic Attributes Using Conditional Random Fields," in Proc. Interspeech, 2006.
[4] B. Roark, M. Saraclar, M. Collins and M. Johnson, "Discriminative Language Modeling with Conditional Random Fields and the Perceptron Algorithm," in Proc. ACL, 2004.
[5] G. Zweig and P. Nguyen, "A Segmental CRF Approach to Large Vocabulary Continuous Speech Recognition," in Proc. ASRU, 2007.
If you have comments, corrections, or additions to this article, please contact the author: Tara Sainath, tsainath [at] us [dot] ibm [dot] com.
Tara Sainath is a Research Staff Member at IBM T.J. Watson Research Center in New York. Her research interests are mainly in acoustic modeling.
SLTC Newsletter, July 2010
One-on-one tutoring allows students to receive personalized attention and is found more effective than classroom learning. In a classroom, where one teacher presents material to 20 or 30 students, each student receives less personalized attention. Providing a personal tutor for each student is expensive and infeasible. Can automatic tutoring systems provide instructions, support, and feedback to a student and play the role of a one-on-one tutor? This and other educational system-related questions were addressed at the tenth conference on Intelligent Tutoring Systems (ITS) that took place in June, 2010 in Pittsburgh, USA.
Automatic tutoring systems are interactive applications that guide students through lessons and exercises, provide feedback, hints, and encouragement. Tutoring systems aim to improve student's learning by providing personal attention as a one-on-one tutor. Researchers at ITS presented techniques for modelling virtual tutors, learn tutoring strategies from human tutors, and evaluate effect of automatic tutoring approaches. The presented tutoring systems focused on different student levels, from elementary school to college, as well as medical students and soldiers.
The ITS conference started in 1988 and has been steadily gaining popularity. Currently the conference takes place every 2 years. The ITS2010 edition featured 62 oral paper presentations and 74 posters, including poster presentations for the Young Researchers Track, and a demo session with 17 demonstrations. Five invited speakers included psychologists and computer scientists from industry and academia.
The role of detecting and modelling emotions during tutoring was one of the topics emphasised at the ITS2010. In his invited speech, Dr. Stacy Marsella from the Institute for Creative Technologies, University of Southern California, spoke about the role of emotional modelling in systems with virtual agents. He described an approach to modelling emotion in a virtual agent that allows the agent to adapt to the environment by dynamically changing its goal, belief, and intention and modelling human coping behaviour. Dr. Beverly Park Woolf, an invited speaker from the University of Massachusetts, Amherst, described the emergence of social and caring computer tutors, which respond to both affect and cognition.
"Affective" tutoring systems try to detect the user's emotional state and change their behaviour to adapt to the user's state. The conference presented two sessions on "affect" and one on "metacognition". The presentations discussed relation between affective feedback and student's learning (D'Mello et al.), psychological state (Pour et al.), and self esteem (Jraidi and Frasson), link between psychological state and cognition during learning (Lehman et al.), between emotions, motivation, and performance (A. Chauncey and R. Azevedo).
Tutoring system are dialogue systems: they understand user's input, determine the next dialogue move, and generate the system's move. System's effectiveness (and hence student's knowledge gain) depend on the appropriateness of the dialogue move chosen by the system. The tutoring dialogue strategy determines whether at a particular point of the interaction, a system should give student a hint, repeat a question, ask a suggestive question, give the user an encouragement, or switch to a new topic. Two of the conference sessions presented evaluation and analysis of human of pedagogical strategies in human tutors and evaluation of strategies in tutoring systems. Natural language interactive system use machine learning for automatic detection of a system strategy (K. Boyer et al., M. Chi et al.). K. Forbes-Riley and D. Litman automatically detect metacognitive information, such as student's confidence and use this information in their system's dialogue move modelling.
Virtual humans are animated life-like characters that interact with users using a combination of speech and non-verbal behaviour. Some tutoring systems employ virtual agents to incorporate visual modality and personify tutoring systems. For a system that teaches intercultural negotiation skills (Ogan et al.) or a deception detection (H. C. Lane et al), a virtual agent is an essential component as students learn by observing virtual agent's behaviour. Using gaming environment for teaching is also gaining popularity in the tutoring domain. The ITS conference featured two sessions on intelligent games. In games, student cheating becomes possible, hence one of the sessions at ITS focused on ways of detecting users that try to "game" the system.
Most of the evaluation of tutoring systems involves measure of students' learning progress by comparing students' performance on pretest and posttest. Another approach to focus on long term student's learning (R. Gluga et al.).
Incorporating speech into tutoring system gives a user a more natural interface. However, speech recognition errors as in other dialogue systems present a challenge to this task. Using speech in tutoring system is especially difficult as the state space and vocabulary are larger than in traditional 'slot-filling' dialogue systems. Intelligent tutoring is a socially important domain that combines a range of research fields including Psychology, Artificial Intelligence, Dialogue, Multimodal Communication, and Speech Technology presenting open challenges to speech researchers.
If you have comments, corrections, or additions to this article, please contact the author: Svetlana Stoyanchev, s.stoyanchev [at] open [dot] ac [dot] uk.
Svetlana Stoyanchev is Research Associate at the Open University. Her interests are in dialogue, question generation, question answering, and information presentation.
SLTC Newsletter, July 2010
Phonetic Arts supplies speech synthesis technologies to the games industry. Although huge technological advances have led to a continuous improvement in the quality and complexity of the graphics generated by computer games, games audio is only just now moving beyond the concept of replaying a large library of static prerecorded lines. Phonetic Arts’ core product is a suite of software that enables games developers to build parametric voices from existing speech recordings and to recombine lines of dialog on-the-fly to massively increase the variability of speech in games. Our product suite, PA Studio, has been developed in partnership with many leading game studios, ensuring that we can provide the best possible speech solutions to the games industry. Phonetic Arts was formed in late 2006 and has grown to 14 staff, all based at Phonetic Arts HQ in Cambridge. It was founded by Paul Taylor, Ian Hodgson and Anthony Tomlinson. The original idea of bringing dynamic speech to games came after a meeting with the developers of one of the leading sports titles a number of years ago.
Currently, there are two main released products. PA Generator is a toolset for making parametric synthetic voices from an existing set of recordings. This has two uses - for generating placeholder dialog or for use with the low-footprint in-game engine. The other product is PA Composer, which provides games designers with an off-line method for recombining the existing recordings at the word level to generate high-quality speech files.
Phonetic Arts isn’t set up as a service provider - the tools to build these voices are designed for use directly by the customers. This allows the customers to build and prototype voices much faster than using an intermediary company. Indeed, with A-list actors being used increasingly frequently in games, it would often not be possible to send recorded dialog to a different company. Additionally, the current games market is increasingly based around characters and franchises, with more than half of the current games chart being sequels. In this situation, there already exists a large corpus of recordings before a project has even started, with as many as 20,000 lines of dialog for a single voice actor.
Together, Generator and Composer combine to form a useful bookending process in the game dialog recording process. Currently, placeholder dialog is often recorded ad-hoc by the audio programmer, or simply not added until near the end of the game. Getting realistic dialog in the game earlier makes functional testing (memory budgets are a key sticking point in games development) as well as design and pacing much easier. When the core voice artists have recorded their lines, the Composer wave-splicing technologies can eliminate the need for additional pickup sessions.
The potential advantages of these technologies for the games industry are numerous. Even when thousands of lines have been recorded, canned lines can become extremely repetitive for key game events, and variation of words and prosody would improve the game experience. For the sports games, anaphora are currently used (“He’s passed it back to his team-mate”) as the full set of possibilities are too large to store or even feasibly record. In the more extreme cases, there are stories of game releases held up for weeks due to a single copyrighted word used in the narration, or of entire voice-over systems being removed after poor feedback at the alpha play-test stage. Eliminating these sorts of mistakes will help games to be developed faster and with higher-quality, better integrated voice dialog.
There are still a number of challenges: games dialog is frequently much more expressive than any existing speech synthesis solution, and as expected with parametric speech, there is a constant call for higher quality synthesis. However, with a dynamic focused team and strong links with the biggest studios and developers in the industry, the possibilities ahead should be exciting and (literally) game-changing.
Matt Stuttle is Vice President, Research at Phonetic Arts. matt.stuttle@gmail.com