
Welcome to the Summer 2011 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter.
In this issue we are pleased to provide another installment of brief articles representing a diversity of views and backgrounds. This issue includes articles from 23 authors, including contributors and our own staff reporters and editors.
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions. You can submit job postings here, and reach us at speechnewseds [at] listserv (dot) ieee [dot] org.
Finally, to subscribe the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Jason Williams, Editor-in-chief
Pino Di Fabbrizio, Editor
Martin Russell, Editor
Chuck Wooters, Editor
Notes from ICASSP 2011, and Speech and Language Processing for In-Vehicle Applications
The IEEE Signal Processing Society, our parent organization, also produces a monthly newsletter, "Inside Signal Processing".
The ILHAIRE project (pronounce "ill-hair") is a new project funded under the Future and Emerging Technologies (FET) chapter of the 7th framework program of the European Community, starting in September 2011. Its purpose is to study the role of laughter during interactions between humans and machines. It will involve 9 partners across 6 European countries: University of Mons (Belgium, coordinator), CNRS (France), Univesity of Augsburg (Germany), Universita degli Studi di Genova (Italy), University College London (UK), Queen's University Belfast (UK), University of Zurich (Switzerland), Supelec (France), La Cantoche Production (France).
This book review discusses "Symbols and Embodiment: Debates on meaning and cognition", edited by Manuel de Vega, Arthur Glenberg, and Arthur Graesser, which contains many ideas useful to language technologists.
The 36th IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) was recently hosted in Prague, Czech Republic from May 22-27. The conference included lectures and poster sessions in a variety of speech and signal processing areas. In this article, some of the main acoustic modeling sessions at the conference are discussed in more detail.
This article describes the GIVE challenge, which is a shared task to evaluate natural language generation (NLG) systems. The NLG systems have to generate, in real-time, instructions that guide a human user through a virtual environment. The data-collection is carried out over the Internet. Currently, data is being collected for the third installment of the GIVE challenges. Go to www.give-challenge.org to try it out.
Graphics Processing Units (GPUs) were developed to deliver the video quality required by modern computer games. However they have much wider applications, including computationally intensive tasks in speech and language processing.
This article gives a short description of how emerging technologies, and more specifically, multimodal and multichannel signal processing, can improve the interaction between users and machines in the living-room “technology battle-field”.
SemDial 2011 (Los Angelogue), the 15th annual workshop on the semantics and pragmatics of dialogue, will be held in Los Angeles at the Institute for Creative Technologies, University of Southern California on 21-23 September 2011.
The just-completed Robotics: Science and Systems workshop on Grounding Human-Robot Dialog for Spatial Tasks aimed to identify key challenges related to situated dialogue for navigation and manipulation.
SLTC Newsletter, July 2011
Welcome to the next installment of the SLTC Newsletter of 2011. I hope all are enjoying the summer. ICASSP-2011 took place in May, with a tremendous success. The session on "Trends in Signal Processing: Speech & Language Processing," had an extensive turn out. I wish to thank and recognize Junlan Feng, Bhuvana Ramabhadran, and Jason Williams who worked to attend and organize the overview presentation slides and written summary which is being published in the next issue of the IEEE Signal Processing Magazine. The slides and text overview can also be found on the SLTC Webpage [1]. Papers in speech and language processing continue to the largest topic area at ICASSP, with 691 papers submitted, 336 accepted, and 2764 reviews completed (we averaged 4 blind reviews plus a separate "meta-review" of the four reviews for each paper; resulting in 5 reviews performed for each paper to ensure the highest quality papers were presented). With over thirty sessions, it was a challenge to present the research highlights in speech and language processing in such a short session, but Junlan and Bhuvana, along with input from Jason, did an outstanding job. This is clearly becoming a popular session to attend (having it on the last day – Friday, also helped).
I also want to encourage everyone to attend the IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU) [2] which will take place Dec. 11-15, 2011 in Hawaii, USA. The submission deadline for papers has now passed and papers are presently under review. The deadline for demonstration submissions is September 15; instructions for making a submission can be found on the ASRU 2011 website. The organization committee is putting together a well organized program with 3 keynote talks and 5 invited talks.
I also want to highlight a new conference being organized by the IEEE Signal Processing Society entitled: IEEE ESPA-2010: Inter. Conf. on Emerging Signal Processing Applications, Jan. 12-14, 2012 (Las Vegas, NV, USA) [3]. Paper submissions are due Aug. 15, 2011, and the submission process allows greater flexibility of paper/presentation format in order to encourage more industry engagement. This is the first time this conference will take place, and is intended to take place in Las Vegas each year.
This month, I wanted to say a few words on an emerging area where speech technology is rapidly expanding – in-vehicle applications. In the field of speech processing, many advancements have been made in speech recognition, speech synthesis, and dialog systems over the past thirty years. Speech technology in the car has seen a rapid expansion recently. In the 1980's, many vehicles emerged with built-in speech synthesis technology – emulating a USA television program Knight Rider[10], which featured a talking interactive vehicle. However, the speech engagement for vehicles in that period was limited to synthesis where the vehicle would remind the driver if the "the door is ajar" or to "fasten your seatbelts" based on built in sensor technology. While novel when it first appeared, drivers soon became annoyed at being told what to do, and without speech recognition, there was no true human-to-vehicle interaction. More recently vehicles have expanded their computing technology, as well as connectivity to the environment and transportation infrastructure. So how did we get here and where are we going?
The automobile has been in existence for more than 100 years, and has evolved significantly during the past three decades. Early automobiles were designed to move the driver and passengers from point A to point B. Performance, comfort, style, and safety have all emerged to be core components in today's automotive market. The level of Digital Signal Processing contained within vehicles continues to grow significantly. This is due in part to the rapid growth of sensor technology within cars, as well as the motivation to make cars safer and more fuel efficient. In recent years, the concept of a "Smart Car" has also emerged, in part due to the advancements of artificial intelligence and computer design being introduced into vehicles. In the United States, the DARPA Grand Challenge [4] represents an effort which was started in 2004 to develop driverless vehicles. These vehicles would be fully automated and allow GPS, multi-sensor fusion, and advanced decision directed and feedback controls/artificial intelligence to navigate as an autonomous vehicle over long distances (i.e., 10-150miles). To date, more than 195 teams from 36 US States and 4 countries have entered the competition. While the integration of advanced intelligence for smart cars is an admirable goal to achieve, it is clear that many individuals who own their own car enjoy the freedom of driving, and are not likely to want to give up the ability to control their vehicle soon (or perhaps increase their interactions with speech?). Sample technologies for in-vehicle applications include car navigation systems, infotainment systems including music/satellite radio/digital music players (MP3, iPod, etc.)/internet, and wireless cell phone technology. As such, dealing with the introduction of new technologies into the vehicle environment represents a major challenge in the field.
As people spend more time in their vehicles, and commuting time to and from work continues to increase as urban populations grow, drivers are attempting to perform many more tasks than simply driving their vehicles. The introduction of wireless technology, digital audio/music players, mobile internet access, advanced entertainment/multimedia systems, and smart navigation technologies into the car has placed increased cognitive demands on drivers. Yet, the typical driving test in countries continues to focus exclusively on the logistics of operating the vehicle itself, and does not consider the management of these outside technologies as part of the driver assessment for a license. The United States as well as many countries have therefore moved to pass laws that restrict the use of cell phones and text messaging while operating a vehicle[5,6]. The recent book "Traffic: Why We Drive The Way We Do," by Tom Vanderbilt[4], offers a number of perspectives on society, culture, and government engagement on driving and drivers. Driver distractions in the car are many, and have been documented by countless research studies. The average driver adjusts their radio 7.4 times/hour of driving, turn their attention to infants 8.1 times/hour, and are generally searching for something (e.g., sunglasses, coins, etc.) 10.8 times/hour (pg. 78, [7]). The average driver looks away from the road 0.06sec every 3.4sec. Mobile devices with "intense displays" such as MP3/iPod technology require more concentration to search for songs, pausing or skipping a song. While there are some differences of opinion, researchers have noted that any task that requires a driver to divert his/her attention (typically visual) away from the road for more than 1.5 seconds (some believe this is up to 3sec) is viewed as a distraction. Irrespective of the exact time threshold, such a guideline is important as a general rule, but clearly new advancements in speech and language technology could offer a more cognitively safe modality to achieve secondary tasks (note: the primary task of driving relies almost exclusively on vision, and to a lesser degree touch/feel; the audio/acoustic channel is not employed as much except for certain warning sensors and it is interesting to note that hard-of-hearing/deaf individuals are free to obtain driver's licenses and operate vehicles). However, it should be clear that not all drivers are equally skilled, and so speech/language interactive systems within the car offer opportunities to allow for vehicle to driver interaction without diverting the primary driving task that relies on vision.
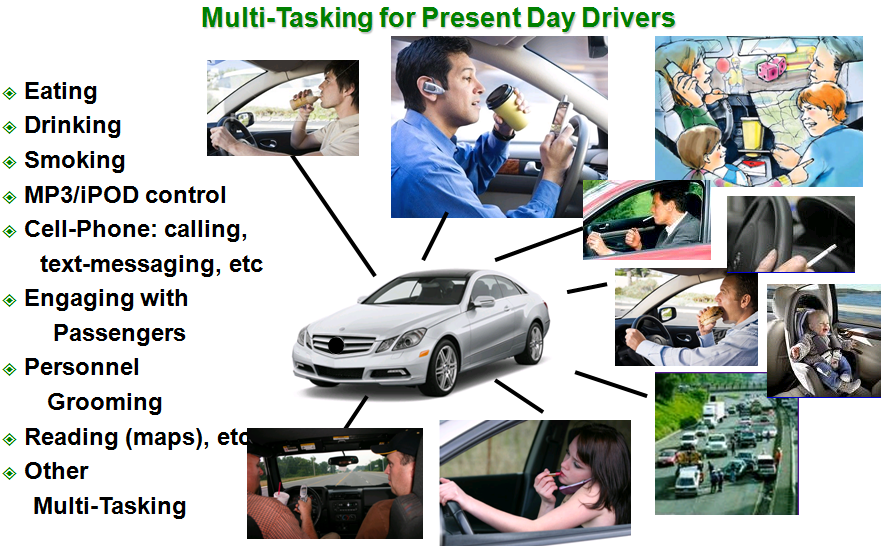
Speech recognition and interaction in the car is now moving into a new phase. In 2007, the Ford Focus[8] was one of the first vehicles to be equipped with commercial "SYNC" speech recognition. Since then, other auto manufactures (Honda Accord, Chrysler Sebring, Chevy Malibu, Mercedes, etc.[9]) have partnered with speech technology companies to advance this technology. The ability to engage with MP3/music players as well as voice navigation systems represents some of the core applications where speech recognition is being considered in the car environment. Robustness issues with respect to noise and environment represent one of the main challenges necessary to overcome.
It is clear that speech technology is making inroads to the vehicle market, however next generation speech interfaces need to be cognizant of the diverse range of driver capabilities and the resulting cognitive load placed on the driver in the context of using such technology while driving. We should all realize that if a speech application fails while we are talking on our landline or cell phones in a neutral task-free environment, the user might be annoyed; designing poor speech/dialog interfaces for use in the car environment can have significant consequences if the task load distracts the driver in any major way.
The USA is about to embark on a major naturalistic driving data collection. Naturalistic driving involves the miniaturization of data capture technology results in a recording platform that is seamlessly embedded into the driver's own vehicle, so it becomes a continuous window into everyday driving. The U.S. Transportation Research Board (TRB) is undergoing the SHRP2[11] program, which would capture drivers from +1500 vehicles continuously for two years. This corpus clearly would provide rich opportunities to integrate new digital signal processing advancements for built-in safety monitoring in the future.
The answers to questions relating to improved in-vehicle systems for safety are complex and require experts from diverse research fields including speech and language technology. Significant advancements that leverage knowledge from such areas as human factors, speech/language/dialog systems, cognitive science, signal processing, and artificial intelligence will ultimately lead to next generation vehicles which continue to move drivers and their passengers from point A to point B, but will also contribute to better driver-vehicle interactions which hopefully will lead to a safer driver experience as well.
With this, I wish you safe driving experience this summer, and hope you all get a chance to talk with your vehicle soon!
John H.L. Hansen
July 2011
John H.L. Hansen is Chair, Speech and Language Processing Technical Committee.
[1] IEEE SLTC webpage: http://www.signalprocessingsociety.org/technical-committees/list/sl-tc/
[2] IEEE Workshop on Automatic Speech Recognition and Understanding ( ASRU-2011) webpage: http://asru2011.org
[3] IEEE ESPA-2010: Inter. Conf. on Emerging Signal Processing Applications, Jan. 12-14, 2012 (Las Vegas, NV, USA) webpage: http://www.ieee-espa.org
[4] http://en.wikipedia.org/wiki/DARPA_Grand_Challenge
[5] http://www.iihs.org/laws/cellphonelaws.aspx
[6] http://www.cellular-news.com/car_bans
[7] T. Vanderbilt, "Traffic: Why we drive the way we do," A.A. Knopf, 2008.
[8] http://media.ford.com/article_display.cfm?article_id=32970
[9] http://www.em-t.com/Speech-Recognition-Technology-in-Your-Car-s/199.htm
[10] http://en.wikipedia.org/wiki/Knight_Rider
[11] http://www.trb.org/StrategicHighwayResearchProgram2SHRP2/
SLTC Newsletter, July 2011
The ILHAIRE project (pronounce "ill-hair") is a new project funded under the Future and Emerging Technologies (FET) chapter of the 7th framework program of the European Community, starting in September 2011. Its purpose is to study the role of laughter during interactions between humans and machines. It will involve 9 partners across 6 European countries: University of Mons (Belgium, coordinator), CNRS (France), University of Augsburg (Germany), Universita degli Studi di Genova (Italy), University College London (UK), Queen's University Belfast (UK), University of Zurich (Switzerland), Supelec (France), La Cantoche Production (France).
Laughter is a significant feature of human communication, and it is a problem for machines acting in roles like companions or tutors if they are blind to it. It has a dual function, and can be roughly distinguished into two types: hilarious laughter and social laughter. The former is a reaction to a stimulus (typically to a funny situation, a joke, a funny video, etc.). It can be experienced in isolation or in a group (which can cause laughter contagion).The latter only appears in social interaction (peer-to-peer or within a group), and is very frequent (more than one per minute, typically). This kind of laugh has a strong social function: in peer-to-peer conversation it is used as a means of mitigating the meaning of verbal utterances, eliciting backchannel information ("are you following my discourse?", "do you appreciate it?", "listen to me!") or suggesting turn-taking; in group conversation, it can be used to measure the level of cohesion of the group.
Laughter can be mixed with articulated speech (termed as speech laugh) or produced as sequences of meaningless syllables ("ha", "ho", "hm","hr",etc.). Social laughter can take both forms, while hilarious laughter is more of the second type.
Laughter also obviously has cultural specificity: people all over the world do not laugh at the same things, and not in the same way; and the effects are not the same.
The ILHAIRE project will build upon recent research in the fields of signal processing [1,2], psychology [3], Embodied Conversational Agent [4], imitation learning [5]. The long-term objectives of IHLAIRE are to help the scientific and industrial community to:
In order to reach these objectives, the project will lay the foundations of truly multimodal, multicultural laughter-enabled man-machine interaction, through the following measurable outcomes:
The ILHAIRE project will last for 3 years and will come to an end in August 2014. The FET program, which funds this project, is one of the most competitive funding schemes in Europe (less than 6% of acceptance rate) and focuses on fundamental research and potential breakthroughs. With this project, new paradigms for natural man-machine interactions and a high level of academic research are expected. The ultimate goal of the project is to reach naturalness and adaptation in human-machine interfaces but also to have a better understanding of the role of laughter in human-human and human-computer interactions.
[1] Petridis, S. and M. Pantic. Classifying Laughter and Speech using Audio-Visual Feature Prediction. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP 2010).
[2] Urbain, J., Niewiadomski, R., Bevacqua, E., Dutoit, T., Moinet, A., Pelachaud, C., Picart, B., Tilmanne, J. and J. Wagner. AVLaughterCycle, Journal of Multimodal User Interfaces, 4(1):47-58, 2010
[3] Ruch, W. and R.T. Proyer. Who fears being laughed at? The location of gelotophobia in the PEN-model of personality.Personality and Individual Differences, 46(5-6):627-630, 2009
[4] Bevacqua, E., Hyniewska, S.J. and C. Pelachaud. Evaluation of a virtual listener's smiling behaviour. In Proceedings of the 23rd International Conference on Computer Animation and Social Agents (CASA 2010), Saint-Malo, France, 2010
[5] Chandramohan, S., Geist M., Lefevre, F., Pietquin, O. User Simulation in Dialogue Systems using Inverse Reinforcement Learning. In Proceedings of the 12th Annual Conference of the International Speech Communication Association (Interspeech 2011), Florence (Italy), 2011
SLTC Newsletter, July 2011
The ILHAIRE project (pronounce "ill-hair") is a new project funded under the Future and Emerging Technologies (FET) chapter of the 7th framework program of the European Community, starting in September 2011. Its purpose is to study the role of laughter during interactions between humans and machines. It will involve 9 partners across 6 European countries: University of Mons (Belgium, coordinator), CNRS (France), University of Augsburg (Germany), Universita degli Studi di Genova (Italy), University College London (UK), Queen's University Belfast (UK), University of Zurich (Switzerland), Supelec (France), La Cantoche Production (France).
Laughter is a significant feature of human communication, and it is a problem for machines acting in roles like companions or tutors if they are blind to it. It has a dual function, and can be roughly distinguished into two types: hilarious laughter and social laughter. The former is a reaction to a stimulus (typically to a funny situation, a joke, a funny video, etc.). It can be experienced in isolation or in a group (which can cause laughter contagion).The latter only appears in social interaction (peer-to-peer or within a group), and is very frequent (more than one per minute, typically). This kind of laugh has a strong social function: in peer-to-peer conversation it is used as a means of mitigating the meaning of verbal utterances, eliciting backchannel information ("are you following my discourse?", "do you appreciate it?", "listen to me!") or suggesting turn-taking; in group conversation, it can be used to measure the level of cohesion of the group.
Laughter can be mixed with articulated speech (termed as speech laugh) or produced as sequences of meaningless syllables ("ha", "ho", "hm","hr",etc.). Social laughter can take both forms, while hilarious laughter is more of the second type.
Laughter also obviously has cultural specificity: people all over the world do not laugh at the same things, and not in the same way; and the effects are not the same.
The ILHAIRE project will build upon recent research in the fields of signal processing [1,2], psychology [3], Embodied Conversational Agent [4], imitation learning [5]. The long-term objectives of IHLAIRE are to help the scientific and industrial community to:
In order to reach these objectives, the project will lay the foundations of truly multimodal, multicultural laughter-enabled man-machine interaction, through the following measurable outcomes:
The ILHAIRE project will last for 3 years and will come to an end in August 2014. The FET program, which funds this project, is one of the most competitive funding schemes in Europe (less than 6% of acceptance rate) and focuses on fundamental research and potential breakthroughs. With this project, new paradigms for natural man-machine interactions and a high level of academic research are expected. The ultimate goal of the project is to reach naturalness and adaptation in human-machine interfaces but also to have a better understanding of the role of laughter in human-human and human-computer interactions.
[1] Petridis, S. and M. Pantic. Classifying Laughter and Speech using Audio-Visual Feature Prediction. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP 2010).
[2] Urbain, J., Niewiadomski, R., Bevacqua, E., Dutoit, T., Moinet, A., Pelachaud, C., Picart, B., Tilmanne, J. and J. Wagner. AVLaughterCycle, Journal of Multimodal User Interfaces, 4(1):47-58, 2010
[3] Ruch, W. and R.T. Proyer. Who fears being laughed at? The location of gelotophobia in the PEN-model of personality.Personality and Individual Differences, 46(5-6):627-630, 2009
[4] Bevacqua, E., Hyniewska, S.J. and C. Pelachaud. Evaluation of a virtual listener's smiling behaviour. In Proceedings of the 23rd International Conference on Computer Animation and Social Agents (CASA 2010), Saint-Malo, France, 2010
[5] Chandramohan, S., Geist M., Lefevre, F., Pietquin, O. User Simulation in Dialogue Systems using Inverse Reinforcement Learning. In Proceedings of the 12th Annual Conference of the International Speech Communication Association (Interspeech 2011), Florence (Italy), 2011
SLTC Newsletter, July 2011
This book review discusses "Symbols and Embodiment: Debates on meaning and cognition", edited by Manuel de Vega, Arthur Glenberg, and Arthur Graesser, which contains many ideas useful to language technologists.
One reason that working with language and computers is so interesting is that it leads to notoriously difficult problems. Trying to make robust interactive systems, especially in situated environments, leads the researcher to consider the problem of meaningful language, and the relationship between symbol systems, cognition, and language use.
"Symbols and Embodiment: Debates on meaning and cognition" is a good example of how such difficult research problems can be productively addressed by an interdisciplinary group. The book was developed as a follow-up to a workshop of computer scientists, neuroscientists, experimental psychologists, and other cognitive scientists. The main chapters of the book are expansions of presentations that were given at the workshop, and each chapter includes a transcription of the discussion that occurred after the presentation.
An introductory chapter presents the central questions of the book. The first set of questions considers a symbol system being used by an intelligent agent. To create meaningful behavior (such as language use), is it enough for this symbol system to be "arbitrary, abstract, and amodal"? Or should the symbols be embodied in perceptual systems, in the same way that empirical data suggests that humans use sensorimotor cognitive resources for symbol processing? Also (or alternately?) should the symbol systems be grounded by relating them to physical objects in the agent's world? Second, to what extent do the results showing the activation of brain regions for perception and action during language processing in humans actually suggest that meaningful language use in humans is embodied? Third, how do the first two questions relate to meaningful language use in computers: are humans and computers completely different, are they analogous, can computers only be used to simulate meaningful human language use, or can they be meaningful in the same way? Finally, what are the best ways to explore these questions?
The participants propose a number of different answers to these questions. Latent semantic analysis is discussed as an example of statistical symbolism (as opposed to less data-driven symbolic approaches) and in this context, meaning is based on word co-occurrence. This is supported by evidence that covariation reflects world knowledge, for example. Proponents of embodied cognition discuss empirical data supporting their view, and discuss theoretical models such as neuronal resonance and affordances as being central to meaning. Neuroscientific approaches describe both language-specific and meaning-specific structures in the brain, although the data is "currently fragmentary and partially contradictory" and thus unable to provide an entire answer by itself. AI approaches from the domains of robotics and intelligent tutoring systems show that interactive systems can be valuable without grounded and embodied representations, although they are less valuable as complete explanations of linguistic meaning; and furthermore, conversational robots benefit from grounded representations. These, and more, are the types of issues discussed in the book: informed by experiments, data, and implemented systems, yet highly theoretical.
Although the various authors of the book spend time defining terms such as "symbols", "representations", "grounding", and "embodied", they are (thankfully) happy enough to provide the definitions they have used in their own research, and proceed with their arguments. Perhaps because of the enormity of the problems of investigating meaningful language use, the authors find plenty of space to describe the research questions they are pursuing and how they differ from the others, rather than producing minute critiques of other researchers' ideas. For example, statistical symbolists point out the difficulty of handling abstract meaning in embodied approaches, and embodied theorists argue that statistical symbolism only reflects world knowledge because words correlated with experience, but all participants seem to sense that statistical-symbolist and embodied approaches are describing different parts of a much larger mystery.
In all, the book is a fascinating overview of how various disciplines are approaching the problem of meaningful language use, and how interdisciplinary teams can find common ground while disagreeing on many details. Perhaps this is because of a common acknowledgment of how little humans actually understand about meaningful language use, and the vast amount of research there is yet to be done on the topic. Even in this fairly wide-ranging collection there are perspectives that could have contributed; for example "grounding" in this collection refers exclusively to linking symbols to objects in a physical world, while other researchers have explored the importance of societal grounding and dialogue grounding in meaningful language use. Nevertheless, this is still a book worth examining for anyone interested in the topics discussed above.
For more information, see:
SLTC Newsletter, July 2011
The 36th IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) was recently hosted in Prague, Czech Republic from May 22-27. The conference included lectures and poster sessions in a variety of speech and signal processing areas. In this article, some of the main acoustic modeling sessions at the conference are discussed in more detail.
The session "Statistical Methods for ASR" focused on the use of various machine learning methods for ASR. For example, [1] discussed the use of segmental conditional random fields (SCRFs) as a methodology to integrate information from multiple feature streams. These features include those derived from acoustic templates, deep neural net phoneme detections, duration models, modulation features, and whole word point-process models. Experiments were conducted using a recently released SCARF toolkit, which allows for research using SCRFs. Results with the SCRF framework on both Broadcast News and Wall Street Journal tasks indicated between an 8-9% relative improvement over a strong baseline HMM system.
[2] explores the use of sparse representations for speech recognition, by introducing a Bayesian sensing Hidden Markov Model (BS-HMM). The paper explores making HMM training more generalizable to unknown data, as typically HMM parameters are estimated via maximum likelihood and are prone to overtraining. More specifically, this is done by representing speech data by a set of state-dependent basis vectors, and looks at a Bayesian sensing framework to ensure model regularization. The BS-HMMs are constructed using these basis vectors, as well as a precision matrix of sensing weights and reconstruction errors, representing how well the input feature is encoded by the basis vectors. The paper derives recursive solutions for these parameters. Experiments on a Large Vocabulary English Broadcast News task shows over 0.5% absolute improvement over a strong baseline speaker-adapted, discriminatively trained HMM system.
[3] explores the use of a discriminative model for speech recognition which jointly estimates acoustic, duration and language model parameters. Typically, language and acoustic models are estimated independently of each other. This results in acoustic models ignoring language cues and language models ignoring acoustic information. This paper looks at jointly estimating acoustic, durational and language model parameters, and specifically explores the use of parametric and smoothed-discrete duration models. Results on a large vocabulary Arabic task indicate a 1.5% absolute improvement in WER over a baseline HMM system which estimates the 3 parameters separately.
[4] looks at using ideal binary masks (IBMs) for phonetic modeling. Past studies have suggested that IBMs encode sufficient phonetic information for humans to perform speech recognition. The paper looks at augmenting traditional speech features with IBMs. Results on the TIMIT phonetic classification task offer more than a 1% improvement over the baseline MFCC features. The classification error of 19.5% is one of the best reported in the literature.
Most speech recognition systems collapse high dimensional speech features into lower dimensional features for practically used in speech recognition systems, but can potentially throw away valuable information. [5] looks at using a Restricted Boltzmann Machine (RBM) to capture features more relevant to recognition from raw speech signals. Results on the TIMIT corpus indicate that the detected features allow for better phonetic recognition performance relative to systems which use filter bank or MFCC features.
This article provided a summary of main acoustic modeling sessions at ICASSP, though other sessions covered topics including language modeling, speaker recognition, speech synthesis and robust ASR. The next ICASSP will be help in Kyoto, Japan from March 25-30, 2012.
[1] G. Zweig, P. Nguyen at al., "Speech Recognition with Segmental Conditional Random Fields: A Summary of the JHU CLSP Summer Workshop," in Proc. ICASSP. 2011.
[2] G. Saon and J.T. Chien, "Bayesian Sensing Hidden Markov Models for Speech Recognition," in Proc. ICASSP, 2011.
[3] M. Lehr and I.Shafran, "Discriminatively Estimated Discrete, Parametric and Smoothed-Discrete Duration Models for Speech Recognition," in Proc. ICASSP, 2011.
[4] A. Narayanan and D. Wang, "One the Use of Ideal Binary Masks for Improving Phonetic Classification," in Proc. ICASSP, 2011.
[5] N. Jaitly and G. Hinton, "Learning a Better Representation of Speech Sound Waves Using Restricted Boltzmann Machines," in Proc. ICASSP 2011.
If you have comments, corrections, or additions to this article, please contact the author: Tara Sainath, tsainath [at] us [dot] ibm [dot] com.
Tara Sainath is a Research Staff Member at IBM T.J. Watson Research Center in New York. Her research interests are mainly in acoustic modeling. Email: tsainath@us.ibm.com
SLTC Newsletter, July 2011
This article describes the GIVE challenge, which is a shared task to evaluate natural language generation (NLG) systems. The NLG systems have to generate, in real-time, instructions that guide a human user through a virtual environment. The data-collection is carried out over the Internet. Currently, data is being collected for the third installment of the GIVE challenges. Go to www.give-challenge.org to try it out.
Evaluating natural language generation (NLG) systems is a notoriously hard problem: On the one hand, corpus-based evaluations of NLG systems are problematic because a mismatch between human-generated output and system-generated output does not necessarily mean that the system's output is inferior. [1,2] found that while automatic metrics for comparing system generated output to corpus examples do, under certain conditions, correlate with human judgments of linguistic quality, they do not predict content quality or task performance. For this reason, shared task challenges should preferably include human evaluations of task effectiveness. On the other hand, task-based evaluations where human subjects interact with the NLG system in the laboratory can be hard to realize due to limitations in money, time, and access to a sufficiently large subject pool. The GIVE challenge is a shared task for evaluating NLG systems which makes a task-based evaluation feasible at reasonable cost and effort by collecting user data in a virtual environment over the Internet.
The GIVE challenge invites NLG researchers to build systems that generate natural-language instructions which guide a user in performing a task in a virtual 3D environment. The NLG systems are then compared through a task-based evaluation over the Internet. For the human experimental subjects, GIVE consists in playing a 3D game which they start from a website. Behind the scenes they get randomly paired with one of the participating NLG systems which then has to send them, in real-time, natural language instructions that guide the user to a successful completion of the task. This data-collection method makes it possible to run a large-scale task-based evaluation. To our knowledge, GIVE is the largest ever NLG evaluation effort in terms of the number of experimental subjects taking part. GIVE-1 was organized in 2008-09 and evaluated five natural language generation systems using almost 1200 user interactions. GIVE-2, which ran in 2009-10, evaluated seven systems on more than 1800 user interactions. GIVE-2.5 is currently ongoing.
In all three editions of GIVE so far, the task has been to retrieve a trophy from a safe. In order to do so, the user has to navigate through the environment to press a sequence of buttons that unlock the safe, open closed doors, and de-activate tiles that trigger an alarm when stepped on. GIVE-1 used discrete worlds based on square tiles, where the user could only jump from the center of one tile to the center of the next, and turn in 90 degree steps. The main novelty in GIVE-2 was that it permitted free, continuous movements in the worlds. This made it impossible for the NLG systems to generate very simple instructions of the type "move one step forward", making the NLG task more challenging. Except for the lay-out of the game worlds, the GIVE-2.5 task is identical to GIVE-2, so that GIVE-2 systems can be improved based on experiences from the evaluation, and to give more people the opportunity to participate.
This year, 8 systems (created by teams from six universities in five different countries) are being evaluated. While in the previous editions of GIVE, systems varied in their content planning, utterance planning and realization strategies, all systems took a rule-based approach to instruction generation. In GIVE-2.5 two teams have used different kinds of machine learning, and one system uses a planning-based approach. We welcome this variety, and hope that the evaluation data we are gathering will allow us to gain some insights on the strengths and weaknesses of the different NLG approaches.
Please visit www.give-challenge.org to try out the NLG systems and to contribute valuable evaluation data.
The GIVE software collects some objective measures (such as, task success, completion time, number of user actions, number and length of instructions). In addition, the user is asked to fill in a questionnaire assessing the perceived effectiveness and understandability of the instructions. The data collected in this way in GIVE-1 and GIVE-2 does, in fact, differentiate between systems and can, thus, be used for a comparative evaluation.
To further validate the web-based data collection approach, we repeated the GIVE-1 evaluation in a laboratory setting with 91 participants. The results were consistent with those of the web-based evaluation. That is, where both studies found a statistically significant difference, they agreed. But because of the larger number of subjects the Internet based study found more such differences and allowed for more fine-grained analyses of the effects that the design of the virtual environment and the demographic features of the users have on the effectiveness of the NLG systems [3].
The questionnaire items were designed to cover various aspects of the generated instructions (for example, referring expressions, choice of words, naturalness etc.). However, even though both the objective measures and the subjective ratings bring out differences between the systems, the subjective ratings generally seem to merely echo the objective measures. It is therefore unclear to what extent they give any useful feedback about specific aspects of the NLG systems that goes beyond the objective measures and could help the developers improve their system. In GIVE-2.5 we, therefore, cut down the number of questionnaire items and are encouraging users to give more free-form feedback.
Although GIVE was designed to focus on situated generation in a dynamic environment, issues related to the interactive nature of the task played a much more important role in developing a successful instruction giving system than we had anticipated. For example, the GIVE-2 teams spent a considerable amount of effort on methods for timing the instructions correctly, for monitoring the user and for reacting appropriately to his/her actions. Furthermore, similar to previous work on situated generation [4], we also saw examples indicating that generation for interactive systems may require new approaches to some traditional NLG tasks. For example, instead of describing a button that needs to be pressed using a complex referring expression, it may be more effective to first guide the user to a spot where a simpler referring expression is sufficient, or to first use an ambiguous description and then steer the user in the right direction by giving feedback to his/her movements.
GIVE-3 is planned for 2012. It will feature a modified task, which is currently under discussion. In addition a sister challenge of GIVE called GRUVE (Generating Routes under Uncertainty in Virtual Environments) is going to be organized for the first time in 2012 by Oliver Lemon and Srini Janarthanam.
Go to www.give-challenge.org to participate in the public evaluation of GIVE-2.5, and to www.give-challenge.org/research to find out more about the setup of the challenge and the results of the previous two rounds. Feel free to contact Kristina Striegnitz (striegnk@union.edu) with any questions, comments or suggestions about GIVE.
The interest in shared tasks has grown in the NLG community during the past few years (as Belz and Gatt have described before in this newsletter [5]). A number of shared tasks are now organized each year. They are loosely coordinated by Generation Challenges, an umbrella event designed to provide a common forum for shared-task evaluation efforts that involve the generation of natural language. This year, three tasks are organized as part of Generation Challenges: Surface Realization, Helping Our Own (text correction of academic articles written by non-native speakers), and GIVE. In addition, two new tasks and the second edition of the Question Generation Challenge are in preparation.
The GIVE-2.5 Organizing Committee: Alexandre Denis, Andrew Gargett, Konstantina Garoufi, Alexander Koller, Kristina Striegnitz, Mariët Theune
The GIVE Steering Committee: Donna Byron, Justine Cassell, Robert Dale, Alexander Koller, Johanna Moore, Jon Oberlander, Kristina Striegnitz
SLTC Newsletter, July 2011
Graphics Processing Units (GPUs) were developed to deliver the video quality required by modern computer games. However they have much wider applications, including computationally intensive tasks in speech and language processing.
History is littered with unexpected consequences and improbable successes. For example, few people would have predicted that enabling a single mother to sit in an Edinburgh cafe writing books about the adventures of an underage magician would result in improvements in child literacy (as with J K Rowling and "Harry Potter"). Similarly, financing the cost of developing the next generation of super computers by means of a surcharge on the graphics cards used by computer gamesters would not strike most people as a recipe for success. However, that is exactly what has happened.
After a generation in which every new computer seemed to go at least twice as fast as the last one, increases in clock speed virtually evaporated when the speed reached 3 GHz. The problem is that although the sizes of their geometries are still decreasing, the amount of power used by a Central Processing Unit (CPU) device increases with clock speed. It is the device's inability to get rid of the consequent waste energy in the form of heat that has limited the maximum speed of a CPU. The solution to this conundrum is to increase the number of processors in a system rather than the clock speed of an individual processor. This can be done either by increasing the number of processors in a CPU, typically to two or four, or by having a separate bank of processors.
The "bank of processors" approach had hitherto been used to create devices capable of delivering the picture quality required for modern computer games, by carrying out the graphics processing required to generate the video. However such a Graphics Processing Unit (GPU) can also be used to perform many other tasks, including those which might otherwise be performed by a Digital Signal Processor (DSP). A typical GPU, for example the Nvidia GeForce GTX260, has 216 processors each clocked at 1.242 GHz. Although this is slower than a CPU’s 2.6GHz, with the GPU architecture quite remarkable speedups can be achieved.
GPUs were initially difficult to program due to their restrictive programming model. However, the introduction of NVIDIA's Compute Unified Device Architectures (CUDA) framework has simplified development, allowing the GPU to become a more mainstream tool. CUDA is a C like language for writing kernels, the functions that execute concurrently on the GPU. There are also high-level tools, such as GPUmat which enable MATLAB to use a GPU for computation, and allow programmers to run their tasks on the GPU without extensive knowledge of the GPU or the CUDA. However, these high-level tools do not offer the high flexibility of CUDA.
In a speech processing task, such as Language Identification (LID) using Gaussian Mixture Models (GMMs), the calculation of the log posterior probability of an observation vector reduces to a weighted sum of squares. This operation is carried out many times, particularly in the system’s training phase. On the CPU version of our 4096 component GMM based LID system, this calculation for three hundred hours of speech takes approximately 174 hours. On the GPU the time taken reduces to 14.6 hours. The speedup factor is more than 11.9. While gains like this are frequently observed, a more typical value of speed up for most applications would lie between three and ten (Lee et al. (2010)). The improvement achieved depends on the computation being spread across all or at least most of the processors in the array, so that the algorithm is executed in parallel. Some algorithms do not lend themselves readily to this. For example, computing the current output of an IIR filter requires not only all the input data to the current point, but also all of the outputs up to and including the previous output sample. It is therefore not possible to partition the execution of the filter between independent processors and the benefits of the GPU are therefore forfeit. The FFT is an interesting case (Cui et al. (2009)), since for shorter transforms of less than a thousand points, the GPU offers no improvement over the CPU. In fact the 256 point FFT used in the speech analysis phase of our LID system performs slightly better on the CPU. In these cases a change of algorithm is required to exploit the potential of the GPU. For example it is possible to replace the FFT by an FIR filter bank comprising 20 pairs of in phase and quadrature filters. This increases the speed of speech analysis in our LID system by a factor of 2.74, reducing the time required for the task from 4 hours to 1.45 hours.
Over the last 30 years the price of one megaflop of computing power has fallen from $36,000 to about 0.035c, a factor of 108 making the home supercomputer possible.
That's Real Magic!
For more information see:
Michael Carey is an Honorary Professor, Abualsoud Hanani is a PhD student working on language and regional accent identification, and Martin Russell is a Professor, in the School of Electronic, Electrical and Computer Engineering at the University of Birmingham, Birmingham UK. Email: [m.carey, Aah648, m.j.russell]@bham.ac.uk
SLTC Newsletter, July 2011
Nobody can predict with 100% accuracy what the future will bring for us, so we won't pretend we have all of the answers. However, we do know that technology use in the living room is closely related to the future of the Internet, affecting how we consume media, how we communicate with friends, how we play games, and how we shop. In this context, it is a given fact that platforms that bring the Internet into the home will allow seamless consumption of multimodal data across PCs, mobile devices and TVs under a thin application layer that is completely transparent to the user, often jumping from one device to the other within the same session. Users will have access to their multimodal content regardless of their location, in the house or outside, and regardless of which device is being used. However, given the enormous variety and the sheer amount of current and future media that we are, and will be, able to access, one of the difficult challenges that will define the success or failure of our vision of a "smart" living room is how we will access, search and retrieve this content in an easy, intuitive way. Possible solutions to these and other challenges, mostly related to a proper user interface for the "smart living room of the future", will be explored in this article. Our not-so-wild guess is that the battle of domination amongst the future content-related technologies will last for many years. It is obvious that, with the introduction of applications and devices like Google TV, Microsoft Kinect and other products, this battle has already started.
The rest of this article is not, by any means, meant to provide a deep dive into all the relevant topics, but it is rather meant as a short description of how emerging technologies, and more specifically, multimodal and multichannel signal processing, can improve the interaction between users and machines in the living-room “technology battle-field”.
Today, the most common home controlling interfaces are still based on buttons, touch screens, and keyboards, on remote controls and computer-like devices such as PDAs, smartphones, and tablet PCs. However, the principal trend is towards a more ubiquitous use of handheld devices in home automation, largely promoted by the success of the iPhone/iPad and Android-based devices. Despite the fact that more and more smartphone or tablet applications provide speech interfaces, they do so in a rather limited and strictly constrained way, mainly for command and control purposes, where the users speak highly stylized phrases into a close microphone. With these devices, the vision of a natural interaction platform using speech and/or gestures remains distant and seems rather exotic.
In any case, key-players in the present media industry already offer some technological options for users that want to turn their living room into a hi-tech room with a futuristic flavor. Some of these options (but certainly, not all) are:
 |
 |
A current trend is the exponential growth of multimodal content, making media search and retrieval quite challenging. It is absolutely imperative to develop a novel and friendly way to sift through huge volumes of content, given that the currently common solutions for browsing content, based on some alphabetical listings, is certainly inadequate. The current search experience is frustrating but unavoidable given for example, the hundreds of TV channels present in any cable Electronic Program Guide (EPG). It appears that speech and multimodal interfaces could provide a more natural and efficient means for addressing such challenges. It is far more natural for people to say what they wish to watch, for instance, in order to search for existing recordings or point to some part of the TV for further probing. Microphone arrays, cameras or Kinect-like devices can provide the necessary hardware to implement such speech- and gestures-based interaction. This interaction combined with “intelligent” recommendation systems, such as the Netflix recommendation system proposed by AT&T Labs, will further improve the usability and naturalness of data searching systems.
The goal of a more natural Human-Computer Interface (HCI) is to build a system that allows users to use gestures along with grammar-free speech to search TV listings, record/or play TV shows, and listen to music. Such a system should not be limited to media-center related applications but, instead, should be built as a more generic system component or service, supporting a wide variety of applications and devices. By allowing users to employ gestures and speech as input to the system, naturalness can certainly be improved, whilst the TV screen provides visual system feedback.
We feel that the right starting point for building such a natural HCI is to base it on multimodal data processing, i.e. speech- and gesture-based interaction with the computer that will be capable to parse and “translate” such user input into commands and actions. For example, gesture-related information can be extracted from the visual image recorded by one or more cameras in the room. In addition to that, microphone arrays will capture and deliver much cleaner audio to the speech recognizer, alleviating the need of the user to rest almost motionless or to wear a close-talking microphone, instead of following him around as he/she moves in the room. In the latter approach, there are some major problems that must be addressed: efficient and robust real-time processing of the user-tracking video and audio components, and how well these two modalities can be parsed and combined to provide the “desired action”. Until very recently, examples of easy-to-buy devices providing sensors that support this kind of natural HCI could be counted by the fingers of one hand. This is the primary reason why Microsoft’s Kinect is such a huge success. It combines all the necessary sensors, i.e. audio and visual sensors to probe the world, into a single, inexpensive, easy-to-use package.
Furthermore, there is some good news concerning the “heavy” processing of huge volumes of multimodal data. Current experience has shown that it is not necessary for much of the processing of the multimodal data to be done on local machines in the home; but it could be provided by synaptic application servers in the “cloud”. The advantage of this approach is that the powerful and expensive machines can be centralized and the “Living Room of the Future” can be web connected to them. Therefore, end-user machines will only have to provide thin (and inexpensive) client services that communicate with these application servers, thus offering an affordable and scalable processing solution.
There are some discrete steps that should be considered when building a multimodal interface. A first step towards localized and personalized applications in the home is an accurate real-time face tracking scheme. Accurate face tracking can be quite challenging when the ambient conditions are unconstrained and vastly varying. Besides the environmental conditions that is, lighting, furniture, physical layout of the rooms, etc., human behavior also increases the complexity of this task. For example, natural gestures create occlusions caused by hands in front of the speaker face or by other people, clothes, etc, which should be adequately and smartly addressed before commercializing such systems.
Any effective face detection and classification systems have to employ certain basic functionalities: First, all the faces/users present in the room have to be detected, after translating the 3D information onto a 2D image plane. It is obvious that projecting the real world onto a 2D-plane contains challenges, for example, the 3D faces have to be correctly projected onto a “normalized” view. At present, the problem of accurately detecting a multitude of faces present in a room remains unsolved in general; especially when the users are allowed to have any orientation in reference to the camera, instead of just facing it “head on”, which is the working assumption for present systems. Alleviating such constraints makes the detection task extremely complex and challenging.
As soon as the “presence” of faces in a camera’s field of view is detected, visual features have to be extracted and the faces have to be recognized, accordingly. The features, similarly to previous steps, should be translation-invariant and robust to changes in lighting and other random environmental conditions. The output of this process is extremely valuable since the HCI system will know exactly who is in the room and where each person is located.
The system can adapt and provide personalized services according to the recognized users. Profiles are available for the most frequent users that can be personalized, thus tremendously simplifying further communication with any system tasks. Amongst the different elements of a user profile that could be personalized are the covered multimedia content, and (more practically) the speech recognition acoustic and language models that are vital for top-notch recognition accuracy. It is obvious that an interaction that is personalized significantly enhances the feeling of naturalness, something that is our main interest here.
Finally, a user tracker, when considering the users' position, can direct multimodal data to the users, providing personalized simultaneous content to different users in the same room. This kind of personalized multimedia content delivery to a particular point in the room, shares the same physical principles with microphone array audio processing. (Note that the current video technology enables 3D projection without the use of special glasses when the viewer's position is known.)
Natural spontaneous speech interaction with distant microphones is an important step towards development of hands-free human-computer interfaces. Such interaction has to provide noise immunity, robustness and flexibility despite the obvious variability of environmental conditions, such as ambient noise level, reverberation, or multiple simultaneous conversations.
Voice recognition has been progressively introduced in this demanding application field. However, so far its use appears to be heavily constrained, demanding the use of headsets, or a close-talking mobile device. The far-field ASR, at this moment, can achieve quite unsatisfactory performance, prohibiting any immediate commercial deployment. One more interesting point is that the most commonly used devices for such tasks are microphone arrays built primarily for videoconferencing applications. Therefore, they are quite expensive and still far away from wider public availability. The lack of commercial devices employing more than two microphones is noticeable and indicative of the technological gap that remains to be addressed.
One of the biggest challenges for a massive introduction of ASR technologies in home automation systems is the increase of robustness against spontaneous speech, noise interference and uncontrolled environmental acoustic conditions. The input speech variability related to microphone location is one of the most critical issues often causing degradation in ASR performance.
However, the combination of visual information with (acoustic) microphone arrays will certainly provide accurate directional beams to very narrow spots in the room. In this respect, we are not that far from systems that will enable users to efficiently interact with devices in a crowded room, with music playing in the background and other people chatting, even when the microphones are mounted in some distance. For the time-being, accurate localization is achieved using more (than two) microphones (and thus, increase the overall computational load and respective cost). However, new algorithms, better array designs and more powerful machines are introduced and made available every day.
The ultimate living room of the future is expected to provide distant speech interaction based on ad-hoc microphone networks with hundreds of microphones, randomly distributed. Although many- and cheap - microphones will be installed, only a small subset of them will be active at a time, to provide the necessary speech-based human-computer interaction imposed by the given changing conditions, allowing users on the move to utter commands or describe tasks that now can only be executed using haptics or by pressing buttons, e.g., to search for some video-clip and stream it to the media-center.
Since HCI, even when constrained to the “living room”, as a problem is quite broad and involves many research disciplines including speech processing, computer vision, psychology, artificial intelligence, and many others, an exhaustive listing of all the challenges that have still to be answered is simply not realistic. Therefore, the main goal of this article was only to highlight some of the challenges and start a fruitful discussion about the development of how close we are in building of natural-feeling human-computer interfaces that are based on, or can track and understand the users’ behavior and preferences. However, several research challenges have to be addressed before claiming any real victory in this effort.
Solutions will come from the use of multimodal and multichannel signal processing schemes that will provide an accurate description of the extremely complicated acoustic and visual scene of a real-life living room, separating speech coming from multiple concurrent users and deciding who are the ones that it should “listen” to. In this working scenario, possible interfering sources (e.g., phone ringing, radio, background noise external to the house, other people’s speech, baby’s cry etc.) have to be suppressed, thus improving speech signal quality and consequently the far-field performance of any functional speech recognizer.
Dimitrios Dimitriadis (S'99, M'06) Dipl.-Eng. (ECE), 1999, and Ph.D.-Eng. (ECE), 2005, National Technical University of Athens, Athens, Greece.
From 2001 to 2002 he was an intern at the Multimedia Communications Lab at Bell Labs, Lucent Technologies, Murray Hill, NJ. From 2005 to 2009 he was postdoctoral Research Associate at the National Technical University of Athens, where he also taught courses in Signal Processing. He is now Principal Member of Technical Staff with the Networking and Services Research Laboratory, AT&T Labs, Florham Park, NJ. His current research interests include speech processing, analysis, synthesis and recognition, multi-modal systems, nonlinear and multi-sensor signal processing.
Dr. Dimitriadis has authored or co-authored over fifteen papers in professional journals and conferences. He is a member of the IEEE Signal Processing Society (SPS) since 1999 where he is serving as a reviewer, too.
Email: ddim@research.att.com
Juergen Schroeter: Dipl.-Ing. (EE), 1976, and Dr.-Ing. (EE), 1983, Ruhr-Universitaet Bochum, W. Germany; AT&T Bell Laboratories, 1986-1995, AT&T Labs - Research, 1996-
From 1976 to 1985, Dr. Schroeter was with the Institute for Communication Acoustics, Ruhr-University Bochum, Germany, where he taught courses in acoustics and fundamentals of electrical engineering, and did research in binaural hearing, hearing protection, and signal processing.
At AT&T Bell Laboratories he has been working on speech coding and synthesis methods employing models of the vocal tract and vocal cords. At AT&T Labs, he is heading research on Speech Algorithms and Engines.
Dr. Schroeter is a Fellow of IEEE and a Fellow of ASA.
Email: jsh@research.att.com
SLTC Newsletter, July 2011
SemDial 2011 (Los Angelogue), the 15th annual workshop on the semantics and pragmatics of dialogue, will be held in Los Angeles at the Institute for Creative Technologies, University of Southern California on 21-23 September 2011.
The SemDial series of workshops began back in 1997 with a goal of bringing together researchers from various backgrounds to apply formal methods to the study of dialogue phenomena and to narrow the gap between theory and practice in the design of dialogue systems. Since then there have been 14 workshops held annually at various locations in Europe. These workshops provide an interdisciplinary venue to discuss current research on the semantics and pragmatics of dialogue in diverse fields such as artificial intelligence, computational linguistics, formal semantics/pragmatics, philosophy, psychology, and neuroscience.
The upcoming SemDial 2011 (Los Angelogue) workshop marks the first time the series leaves Europe. The workshop invited papers on all topics related to the semantics and pragmatics of dialogues, including both theoretical topics such as models of common ground and mutual belief, or goals, intentions and commitments in communication, as well as more applied topics such as natural language understanding and reasoning in spoken dialogue systems and dialogue management in practical implementations.
The submission deadline for full papers was in June, and the organizers expect to announce the program by early August. As usual the program will feature a single track of approximately 15–20 refereed technical talks, with a balanced mix from theoretical, computational and psycholinguistics. This year's workshop will also feature four invited talks, delivered by Patrick Healey, Jerry Hobbs, David Schlangen, and Lenhart Schubert. Typical attendance at past workshops has been 60–70 participants.
There will also be a poster session for presenting late-breaking results, ongoing project descriptions and system demonstrations. The deadline for posters and demos is August 7, 2011, and notification will be by August 12.
In recent history, SemDial workshops have been preceded by satellite workshops that address specific issues in dialogue phenomena. This year SemDial 2011 will be immediately preceded by a separate workshop on overlap in dialogue, and together the two workshops constitute a full week of dialogue activity at ICT. The workshops offer a great opportunity to listen to talks about the latest research in dialogue theory, meet colleagues and hold discussions. For further information and to submit a poster or demo, visit the web site SemDial 2011.
As Speech & Language technology researchers take on the challenge of building more complex (beyond simple information exchange) and natural dialogue systems, issues in semantics and pragmatics of dialogue become more relevant. The SemDial 2011 workshop offers a venue for Speech & Language technology researchers to learn about the state-of-the-art in theoretical linguistics and psycholinguistics and to have lively interactions with dialogue researchers from a variety of disciplines.
Sudeep Gandhe is a PhD student at University of Southern California and a Graduate Research Assistant at Institute for Creative Technologies, USC. His research interests include Virtual Human dialogue systems and their rapid prototyping & evaluation.
Ron Artstein is a Research Scientist at the Institute for Creative Technologies, USC, working on data collection and evaluation for dialogue systems. He was program co-chair for SemDial 2007 in Rovereto, Italy, and is presently a member of the SemDial board and of the organizing committee for SemDial 2011.
SLTC Newsletter, July 2011
The just-completed Robotics: Science and Systems workshop on Grounding Human-Robot Dialog for Spatial Tasks aimed to identify key challenges related to situated dialogue for navigation and manipulation.
Robots and other artificial agents situated in the world will need to perform spatial tasks by combining evidence from language and sensory input from the environment. The just-completed Robotics: Science and Systems workshop on Grounding Human-Robot Dialog for Spatial Tasks aimed to bring researchers from these fields together to identify key challenges related to this very issue, namely situated dialogue for navigation and manipulation.
The workshop was held on July 1, co-located with the Robotics: Science and Systems Conference. One of the primary goals of this workshop was to bring together researchers from robotics, computational linguistics, dialog and planning to discuss how to perform effective human-robot interaction for spatial tasks. We feel the workshop was a great success, with 11 submissions from groups approaching spatial human-robot interaction from varied angles (e.g., dialogue, mapping, verb semantics). All authors participated in a poster session that not only had attendees sharing ideas, but the authors of the work themselves visiting each other's posters!
Following the poster session, the workshop featured an eclectic discussion session led by four panelists from the robotics and spoken dialogue communities. The panelists were Dieter Fox (University of Washington), Hadas Kress-Gazit (Cornell University), Alex Rudnicky (Carnegie Mellon University), and David Traum (University of Southern California). Each panelist first presented their thoughts on questions related to spatial natural language understanding, standardizing human-robot dialog, semantic mapping, and dialog management, among other topics. A compilation of the ideas from the workshop is forthcoming and will be posted to the workshop webpage.
One of the highlights of the discussion was how to approach the dialog for spatial tasks problem: should agents take a top-down approach, where they learn the mapping of word sequences to actions for spatial tasks (very much like commercial dialogue systems) or take a bottom-up approach, where agents learn the meaning of individual verbs and formally verify that planned actions can be accomplished in the world (very much like formal methods from the robotics community, only using language). The panel provided clear arguments for both approaches, and we expect this discussion to continue as the field develops.
The workshop follows up on several past related workshops, including the AAAI Fall Symposium on Dialog with Robots and the Workshop on Computational Models of Spatial Language Interpretation and Generation. With a successful poster session and enlightening panel discussion, we believe we achieved our goal of exciting the robotics community about human-robot interaction and the problems related to spatial tasks that robots will one day need to accomplish.
If you have comments, corrections, or additions to this article, please contact the primary author: Matthew Marge, mrma...@cs.cmu.edu.
Matthew Marge is a doctoral student in the Language Technologies Institute at Carnegie Mellon University. His interests are spoken dialog systems, human-robot interaction, and crowdsourcing for natural language research.