Speech and Language Processing Technical Committee Newsletter
August 2012
Welcome to the Summer 2012 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter! In this issue we are focusing on news from recent conferences (such as an overview of speech and related papers at ACL 2012 by Asli Celikyilmaz) and workshops (such as the Odyssey 2012 by Nancy Chen and Haizhou Li and NAACL workshops by Svetlana Stoyanchev and Antonio Roque). This issue of the newsletter includes 11 articles from 11 guest contributors, and our own staff reporters and editors.
Thank you all for your contributions!
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions.
Finally, to subscribe to the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Dilek Hakkani-Tür, Editor-in-chief
William Campbell, Editor
Patrick Nguyen, Editor
Martin Russell, Editor
From the SLTC and IEEE
From the IEEE SLTC chair
John Hansen
Philip Loizou, Pioneer in Signal Processing for Cochlear Implants and Speech Enhancement passes away at 46
John Hansen
Recent Initiatives for Improving Our Transactions
Li Deng
This article reports progress on three major initiatives over the past several months to improve the quality and impact of IEEE Transactions on Audio, Speech, and Language Processing
Call for Nominations: Speech and Language Technical Committee (SLTC) Member Positions
Larry Heck
The Member Election Subcommittee of the SLTC is seeking nominations for new SLTC Members. The nomination deadline is set as 15 September 2012.
Speech and Language Technologies for STEM (Science, Technology, Engineering and Mathematics) Education
Abeer Alwan, Maxine Eskenazi, Diane Litman, Martin Russell, and Klaus Zechner
Over recent years education has become an established application area for speech and language technology. The first STiLL (Speech Technology in Language Learning) took place in Marholmen in Sweden in 1998, and 2006 saw the creation of the ISCA SIG (Special Interest Group) on Speech and Language Technology in Education (SLaTE). Currently, SLaTE is dominated by applications in literacy and language learning, and a study of the technical programs of the biennial SLaTE workshops, from 2007, 2009 and 2011, reveals just a small handful of contributions outside this area. However, it seems likely that there are compelling applications of speech and language technology in other areas of learning, and particularly in the STEM subjects (Science, Technology, Engineering and Mathematics). This article reviews some existing work on applications of speech and language technologies in STEM education, and previews the Special Session on “Speech Technologies for STEM” at Interspeech 2012 in Portland.
The Silent Speech Bandwidth Revolution in Mobile Telephony
Tim Fingscheidt
As mobile telephony today allows not only for the conservative low-latency circuit-switched design, but also for packet-switched IP multimedia subsystem (IMS) or voice over IP designs, mobile speech communication supporting wideband or even more speech bandwidth is possible in a variety of ways. We just need to ask for it - and experience what we have waited for the last 150 years, given, that our communication partner's phone and provider supports the same speech bandwidth.
An Overview of Speech and Related Papers @ ACL 2012
Asli Celikyilmaz
ACL 2012 covered a broad spectrum of disciplines working towards enabling intelligent systems to interact with humans using natural language,
and towards enhancing human-human communication through services such as speech recognition, automatic translation, information retrieval,
text summarization, and information extraction. This article summarizes the speech papers specifically advances on acoustic and
language modeling as well as speech related papers on language acquisition, phonemes and words.
The selected articles are noteworthy of their individual fields as the novel approaches presented in these papers outperform the baselines.
The Dialog State Tracking Challenge
Jason D. Williams
A new corpus-based research community challenge task to accurately estimate the goal of a user interacting with a spoken dialog system.
Dimitri Kanevsky Recognized by White House for Champion for Change Award
Tara N. Sainath
Dr. Dimitri Kanevsky, a researcher in the Speech and Language Algorithms group at IBM T.J. Watson Research Center, recently received the "Champion for Change" Award at the White House.
CL for Literature Workshop at NAACL/HLT 2012
Antonio Roque
The Computational Linguistics for Literature Workshop was recently held at NAACL-HLT 2012 in Montreal on June 8.
Overview of the Workshop on Future directions and needs in the Spoken Dialog Community: Tools and Data
Svetlana Stoyanchev
The Workshop on Future directions and needs in Spoken Dialog Community was collocated with NAACL2012. The goal of the workshop was to find common threads for binding dialog research community together and fostering growth of the field and the community. This article overviews the topics addressed at the workshop and presents discussion outcomes from the break-out sessions of the workshop.
Odyssey 2012: The Speaker and Language Recognition Workshop
Nancy Chen and Haizhou Li
Odyssey 2012 was held on 25-28 June in Singapore with the theme "Celebrating the Diversity of Speakers and Languages".
From the SLTC Chair
John H.L. Hansen
SLTC Newsletter, August 2012
Welcome to the next installment of the SLTC Newsletter of 2012. In this installment, I would like to talk a bit about advancements in speech, language, and hearing with respect to our IEEE Signal Processing Society. The field of speech processing has evolved dramatically over the past forty years as the field of signal processing was established and continued to mature. Initially, the migration from analog to digital for speech focused on advancements in speech coding. However, as mobile technology advanced, the need to integrate voice for command and control, as well as information access, expanded. Today, speech recognition, voice or topic search in audio/movie streams, speaker verification, language identification, and a host of other specific applications where voice is a factor have emerged. While advancements in speech processing centered primarily on signal processing concepts, over the last decade, it has become clear that the next generation of voice interactive technologies will require students and practicing engineers to be more than "just" signal processors with experience in speech. In fact, one might argue that leveraging knowledge from speech science, speech physiology, hearing science, perception, linguistics, and acoustic phonetics is critical in making inroads into some of the most challenging research topics in the field. In one of my recent Chair letters, I noted several "Grand Challenges" in speech today including "speech-to-speech translation", which if solved would reduce one of the most fundamental challenges that limit human interaction (i.e., 'we don't speak the same language!'). Wikipedia lists more than 6000 languages spoken in the world, with more than 300 spoken by more than 1M people. Yet, one could argue that fewer than 30 of these languages have received any significant treatment in the speech recognition field. We just experienced an outstanding IEEE ICASSP-2012 conference in Kyoto, Japan (March 25-30), with approximately 300 papers relating to speech and language processing presented (the next IEEE ICASSP will be held in Vancouver, Canada, May 26-31, 2013,http://www.icassp2013.com/; Tutorial and Special Session Proposals due by Sept. 10, 2012). However, our SLTC community continues to reach out to support other conferences and workshops related to speech, spoken language, audio, multi-media processing, and other areas.
Our Technical Committee (SLTC) has been committed to supporting the diversity of speech and language topics, as well as reaching out to new communities. I would like to encourage those working in the field of speech who attended IEEE ICASSP to consider attending the upcoming Interspeech-2012 conference (http://interspeech2012.org/), which will be held in Portland, OR (USA) Sept. 9-13. Interspeech draws from its roots in two conferences - the ICSLP (Inter. Conf. of Spoken Language Processing) conference series, which began in 1990 with emphasis on acoustic-phonetics, linguistics, speech science, perception, etc., along with the Eurospeech conference series, which emphasized both speech technology and speech processing research. The Interspeech conference, at least from my perspective, has never been in competition with IEEE ICASSP, but in fact complements the signal processing emphasis we enjoy in the papers presented at ICASSP. In fact, over the years there has been a significant increase in the amount of "speech/language/hearing" science in papers at ICASSP, and one might argue that the presence of ICASSP has served to increase the level of engineering and speech/language technology seen at Interspeech. In any event, I would like to encourage our membership and participants of IEEE ICASSP to venture out (if you have not done so already!) and consider attending Interspeech. Increasing the science content and knowledge of our field can only serve to strengthen the impact of the technical advancements from our work!
Finally, in this issue, you will see a number of topics of interest. The election process for SLTC members will begin shortly, so if you know of someone you feel would want to run for a position, or if you yourself would like to, please see the announcement in this newsletter. Job opportunities, and other workshops and current news, are available. Finally, I would note that the community recently lost a gifted researcher in the fields of speech enhancement and cochlear implant research. Philip Loizou passed away and a summary of his activities is also included in this newsletter.
I wish you all the best until the next SLTC Newsletter...
John H.L. Hansen is Chair, Speech and Language Processing Technical Committee.
Philip Loizou, Pioneer in Signal Processing for Cochlear Implants and Speech Enhancement passes away at 46
It is with sadness that the Dept. of Electrical Engineering, Univ. of Texas at Dallas (USA) reports that Prof. Philipos Loizou, a Professor of Electrical Engineering and pioneer in the fields of hearing aids and speech enhancement, and whose work has helped restore partial hearing to countless people, passed away on Sunday, July 22, 2012 due to cancer. He was 46, and is survived by his wife and 11 year old son.
Philipos C. Loizou received the B.S., M.S., and Ph.D. degrees from Arizona State University (ASU), Tempe, AZ, in 1989, 1991, and 1995, respectively, all in electrical engineering. From 1995 to 1996, he was a Postdoctoral Fellow in the Department of Speech and Hearing Science, ASU, where he was involved in research related to cochlear implants. From 1996 to 1999, he was an Assistant Professor at the University of Arkansas at Little Rock, Little Rock, AR. He later moved to join the Department of Electrical Engineering, University of Texas at Dallas, Richardson, TX, where he helped co-found the Center for Robust Speech Systems (CRSS) in the Jonsson School and directed the Speech Processing and Cochlear Implant Labs within CRSS. He served as Professor of Electrical Engineering and held the Cecil and Ida Green Chair in Systems Biology Science at UT Dallas.
Philip Loizou was an internationally known leader in signal and speech processing, speech perception and cochlear implant research. He formulated advancements in both signal processing and cochlear implant devices for electrical stimulation of the inner ear of profoundly deaf people. His algorithms also helped improve the performance of cochlear implants by programming the device to operate more effectively in a range of listening conditions. More recently, he developed an interface that enables smartphones and personal digital assistants (PDAs) to process acoustic signals, including speech and music, through a microphone worn behind an individual's ear. The advanced processing included noise suppression and signal conditioning to produce processed stimulus signals to electrodes implanted in the inner ear. This interface was approved by the U.S. Food and Drug Administration (FDA), and Loizou was overseeing a clinical trial on the interface with more than a dozen collaborating universities, medical centers, and laboratories.
"He was one of the first persons to explore specific speech enhancement algorithms that directly improve intelligibility - previously believed not to be possible," said Dr. John Hansen, head of the Department of Electrical Engineering, Univ. Texas at Dallas. "More than his research, Philip was a true scholar - always looking to make contributions which would help improve the quality of life of people with hearing loss."
Loizou attributed much of his success to his students. "I've had very hardworking and dedicated students," he said earlier this year. "Without them, I find it's difficult for me to progress in my research so I owe a lot of praise to them."
He has served as principal investigator (PI/co-PI) on over $9.4M in external funding in his career from U.S. National Institutes of Health, U.S. National Science Foundation, Texas Instruments, Cochlear Corporation, U.T. Southwestern Medical Center, U.S. Air Force, Starkey Corp., Advanced Bionics Corp., and collaborated with many groups, having received the NIH Shannon Award in 1998. He was known for mentoring his students and helping mentor other faculty members in their quest to obtain research support from the NIH.
"He sought out collaborations which would later become some of the most profound contributions in the field," Hansen said. "In addition to his work, he was a valued colleague, mentor and academic citizen. In true Philip style, he always brought a careful, thoughtful approach to all he did and made all around him better."
"There is a lot of research one can do to make cochlear implants more natural for patients, and easier for them to use", was another comment Philip shared with his collaborator Nasser Kehtarnavaz (Professor, Electrical Engineering).
During his career, he graduated 8 Ph.D. and 15 MSEE students. He has published 93 Journal papers (primarily in The Journal of the Acoustical Society of America and IEEE journals as well as in other journals such as: Ear and Hearing; American Journal of Audiology; Speech Communication; and Hearing Research), 54 peer-reviewed conference papers, 5 book chapters, and 3 textbooks including: Speech Enhancement: Theory and Practice, Taylor and Francis, Boca Raton, FL (2007); An Interactive Approach to Signals and Systems Laboratory (Austin, TX: National Instruments), with co-authors Kehtarnavaz, N. and Rahman, M. (2008); and Advances in Modern Blind Signal Separation Algorithms: Theory and Applications, Morgan & Claypool Publishers (with co-author Kokkinakis, K. (2010)).
Philip was an elected member of the IEEE Speech-Language Technical Committee (SLTC) (2006-09) for the IEEE Signal Processing Society, and served as member of the Organizing Committee for IEEE ICASSP-2010 (Dallas, TX; USA) overseeing Tutorials. He also served as Associate Editor during his career for IEEE Signal Processing Letters (2006-08), IEEE Trans. on Speech and Audio Processing (1999-02), and most recently IEEE Trans. Biomedical Engineering and International Journal of Audiology. He was elected to the grade of Fellow of the Acoustical Society of America for his work on cochlear implants and speech enhancement.
Loizou grew up on the Island of Cyprus in the Mediterranean Sea. He enjoyed outdoor activities with his family including hiking, nature, playing/coaching soccer, and especially fishing with his 11-year-old son, Costakis. He is also survived by his wife, Demetria whose background is also in speech and hearing. They were married for 18 years and treasured their common Greek Cypriot culture including dance and regular trips to visit family and friends in Cyprus.
In honor of Philip Loizou's contributions to the field and his commitment to help improve the quality of life of people with hearing loss, the Department of Electrical Engineering, University of Texas at Dallas, has established a Memorial Scholarship Fund in support of his son, Costakis Loizou (which will be available through UTDallas Marketplace). If you are interested in contributing, please contact Sandra Zemcik (zxf018400@utdallas.edu; +1-972-883-4381; an online Scholarship location will be available at: https://ezpay.utdallas.edu/C20239_ustores/web/store_main.jsp?STOREID=156).
Recent Initiatives for Improving Our Transactions
In my inaugural editorial "Riding the Tidal Wave of Human-Centric Information Processing," which appeared in the January 2012 Issue of IEEE Trans. Audio, Speech, and Language Processing (T-ASLP), various aspects of a preliminary plan to improve our T-ASLP have been outlined. Here, I would like report some recent progress on implementing this plan, thanks to the many helps from our Associate Editor (AE) team and other volunteers including many readers of this Newsletter. Your feedbacks are gratefully appreciated on any of the topics discussed below, and I thank you as part of our community for contributing, either in the past already or/and in the coming years, to the quality and the impact our T-ASLP in whatever role you can play either as an author, AE, reviewer, guest editor, or simply as a community member to help me or any of the above volunteers.
I. New format for ICASSP and Interspeech papers
Several months ago, we initiated the effort of revising the over 30-year-old ICASSP paper format. After extensive discussions by all Technical Committees of our IEEE Signal Processing Society (SPS) and by the SPS Executive Committee, the proposal was finally endorsed in April 2012. The updated ICASSP-2013 website http://www.icassp2013.com now has the following concise information regarding the new format:
Submission of Papers: Prospective authors are invited to submit full-length papers, with up to four pages for technical content including figures and possible references, and with one additional optional 5th page containing only references. A selection of best papers will be made by the ICASSP 2013 committee upon recommendations from Technical Committees.
The additional optional 5th page is motivated by the desire to improve the quality of the ICASSP papers in terms of covering adequate background work on the prior art of the new work, which is an important research methodology. It is also motivated by the need to better connect between ICASSP papers and our society's journal publications including our T-ASLP. This new format, with the additional reference space, will help the readers as well as authors to pay more attention to the fully documented work carried out in the past but related closely to the current work, improving our T-ASLP's impact as well as other journals of our SPS. I thank Prof. John Hansen, Prof. Doug O'Shaughnessy, and other TC members for supporting this effort and for making valuable suggestions.
Soon after the ICASSP-2013 format change was approved, the benefits of the change were quickly embraced by ISCA, who subsequently endorsed a similar change for Interspeech. This is to take effect starting Interspeech-2013 (too late for Interspeech-2012). I thank Prof. Isabel Trancoso and other ISCA leaders for making this happen. As we all know, the Interspeech community is closely aligned with us and we share many common members including community leaders. The new format in Interspeech papers is expected to improve the influence of not only our T-ASLP but also journals of Speech Communication and of Computer Speech and Language, both associated with ISCA.
II. Connecting T-ASLP Papers with Their Conference Paper Origins
To support the above format change and to aid the potential authors in providing more comprehensive background information about their new work to readers, we have initiated the effort of making connections between the already published T-ASLP papers and their conference paper origins. I thank our AEs (in particular, Profs. Wanmai Mak, Rodrigo Guido, Woon-Sen Gan, and Yang Liu) who joined me in this effort and spent a lot of voluntary time in exploring software tools and in manual editing when necessary. The results of this effort are the three files whose links are provided in the link below:
When you click on this link, you will find three links to three sets of data source, in the categories of Audio, Speech, and Language, respectively.
The data source provides connection information between each of the recent T-ASLP papers and the earlier conference paper(s) by the same authors who expanded the conference paper(s) into the T-ASLP's full journal paper. For example, all recent speech papers published in T-ASLP with their possible conference paper origins can be found in:
Since I assumed the duty of EIC for our T-ASLP late last year, I have dedicated my time to read many recent papers in our Transactions. I found that quite a number of our T-ASLP papers with high quality had nevertheless been unknown to me although I knew the work from earlier ICASSP or Interspeech papers by the same authors. I also found that these conference papers often contained much less complete information and were not written as carefully as the T-ASLP papers expanded later. I hope you would all agree with me that for a young researcher or a student, it helps more, or at least as much, to have the complete or expanded information provided to him/her by the authors who took serious effort to write up a full journal paper. This should be especially true if their earlier conference papers were written in a rush due to conference deadlines, which I admit have happened to me in numerous occasions.
So far, we have accomplished compiling all papers published in T-ASLP from January 2010 to June 2012 with their likely conference papers origins established, as estimated using a semi-automated tool explored and exploited by our volunteer AEs (and thus may be subject to errors). We plan to update such information about once in a month when new papers are coming out. To make the future information more precise and to reduce the workload of updating, I have instructed all our AEs to remind the authors whose T-ASLP papers are accepted to follow our society's guideline of including their possible conference paper origin info (if applicable) in preparing their final drafts of the papers. I thank all potential authors for the full collaboration in this regard. I also welcome new ideas on making our process more automatic and on extending the conference paper origin information to the T-ASLP issues earlier than January 2010. Finally, I thank you --- those who wrote recent and past T-ASLP papers as the expansion and/or synthesis of your earlier conference papers --- in advance for spotting possible errors in and adding missing entries to the existing information pointed to by the three links above.
III. New Policy Governing Cross-Society Joint Special Issue
To run a publication with major impact, it is important to expand the existing readership. Last year, while I was the EIC running IEEE Signal Processing Magazine, I worked with the EIC and associate EIC of IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI) to create a joint special issue with common interest to computer vision, machine learning, and signal processing communities. This offered a prime opportunity to bring vast readership from IEEE Computer Society to our SPS (and vice versa). The Computer Society quickly embraced this opportunity and approved this joint effort within three days of our proposal. Unfortunately, our SPS did not approve it, partly due to an old clause in the SPS policy, losing this prime opportunity that would boost our SPS publications' impact. Since then I have been working with the SPS leaders and I am happy to report to you that this policy has been revised successfully to the effect that the old harmful clause has been removed. To my understanding, any other potential block for striking a joint special issue with another journal has been eliminated.
Applying this new policy to our T-ASLP, I see vast opportunities to improve our T-ASLP's potential impact. As an example, as I wrote in my inaugural editorial, multimodal natural user interface exploiting audio-visual speech processing and computer vision techniques (e.g. coordinated gesture and voice recognition) is a popular interdisciplinary topic with high technological importance in today's human-centric computing age. A related topic of applied artificial intelligence exploiting audio, speech, natural language and visual understanding with closed loop (e.g., generalized "dialog") is of even more significant technology value. It is not difficult to see that such topics can form excellent joint special issue between our T-ASLP and another journal outside of our SPS. If you as one or a group of established researchers/educators would like to organize such a joint special issue on our T-ASLP side (or on the side of another journal), let me know and if appropriate I will help make necessary connections.
IV. Summary
In the above, I have outlined three major initiatives over the past several months aimed to improve the quality and impact of our T-ASLP. There are other efforts ongoing (e.g., merging our T-ASLP from the IEEE side with the ACM counterpart), and I plan to report to you in the near future. Note that most of our initiatives are aimed for long-term rather than short-term effects.
In short, there are many excellent opportunities to improve our T-ASLP, given the increasing importance and societal impact of the technologies developed in our community. I would like to solicit your feedbacks on the initiatives outlined above as well as new ideas to improve our T-ASLP further. I also seek your volunteering helps in any of the capacity of an author, editor, reviewer, guest editor, or simply as a community member who helps promote good articles published in our T-ASLP.
Li Deng is a Principal Researcher at Microsoft Research and Editor in Chief of IEEE Trans. Audio, Speech, and Language Processing.
Call for Nominations: Speech and Language Technical Committee (SLTC) Member Positions
The Member Election Subcommittee of the SLTC is seeking nominations for new SLTC Members. Nominations should be submitted to the Chair of the Member Election Subcommittee at larry.heck@ieee.org, with cc toney@informatik.rwth-aachen.de ,bhiksha@cs.cmu.edu, and Fabrice.Lefevre@univ-avignon.fr. Please provide the name, contact information and biography with the nomination.
The nomination deadline is set as 15 September 2012. New member candidates can be self-nominated or nominated by current SLTC members.
Members will serve a term of three years.
Past SLTC members are eligible to be nominated for a second term.
Current SLTC members may also be nominated for a second consecutive term, but would then not be eligible to vote in this new member election. Additional terms are allowed after leaving the SLTC, but at least a 3-year gap in service is required.
New members must be willing to review papers that are submitted to the Society's conferences within the area of the SLTC, review papers for workshops owned or co-owned by the SLTC, serve in the subcommittees established by the SLTC, and perform other duties as assigned. SLTC members will be elected by the members of the SLTC itself based on the needs of the SLTC. The election results will be finalized by 15 November 2012.
Please use the nomination form outlined below and submit a completed nomination form no more than one page in length:
Name of nominee:
Short Biography (not more than 150 words):
Affiliation:
Address and phone number, email:
Link to web page (optional):
IEEE SPS membership (yes/no):
IEEE Volunteer work and leadership activities:
Other professional volunteer work:
Previous SLTC/AE memberships (list periods of service):
Confirmation that the member will serve if elected:
Area of suggested expertise of the nominee (choose ONE from among the
following):
The candidate must be a member of the IEEE Signal Processing Society.
The candidate should be willing to serve if elected. This means active participation including prompt paper reviews for 4 ICASSPs (2012-2015), active participation in accomplishing SLTC sub-committee duties, and best efforts to attend meetings and responding appropriately to action items.
Speech and Language Technologies for STEM (Science, Technology, Engineering and Mathematics) Education
Over recent years education has become an established application area for speech and language technology. The first STiLL (Speech Technology in Language Learning) took place in Marholmen in Sweden in 1998, and 2006 saw the creation of the ISCA SIG (Special Interest Group) on Speech and Language Technology in Education (SLaTE). Currently, SLaTE is dominated by applications in literacy and language learning, and a study of the technical programs of the biennial SLaTE workshops, from 2007, 2009 and 2011, reveals just a small handful of contributions outside this area. However, it seems likely that there are compelling applications of speech and language technology in other areas of learning, and particularly in the STEM subjects (Science, Technology, Engineering and Mathematics). This article reviews some existing work on applications of speech and language technologies in STEM education, and previews the Special Session on “Speech Technologies for STEM” at Interspeech 2012 in Portland.
Introduction
It is well known that the effectiveness of educational software can be greatly enhanced by the incorporation of speech and language technology. Since speech is a natural way to communicate, it is accepted by students as a valid means of interacting with tutoring and learning systems. The potential advantages of speech will already be very familiar to readers of this newsletter: It enables those whose hands are busy to maintain interaction with the tutoring system (for example, when learning to manipulate something in a science laboratory); it allows students to gesture with their hands while they interact with the system; it promotes a larger number of interactions; it enables much more fluid and natural feedback in the learning process (for example, when students are asked to perform a think-aloud exercise); it enables those whose eyes are busy, such as in a fast-paced educational game, to have richer interaction with the system and it has been shown to increase learning; it enables those who cannot yet read to fully interact, instead of relying on passive work or on the use of icons; and it enables non-native elementary students to have a more fulfilling learning experience.
Applications of Speech and Language Technology in STEM Education
Some groups are already working on applications of speech and language technology in STEM education. An early example, in the domain of circuit design, is described in (Smith, 1996). More recently, "My Science Tutor" is an intelligent science tutor that is being developed for children aged between 7 and 11, which allows the child to communicate with the virtual tutor using speech (Ward et al. 2011). Initial results suggest that the use of a conversational multimedia virtual tutor promotes student engagement, interest and motivation. However, for automated interactive literacy and language tuition, the advantages of speech and language technology extend beyond the provision of a natural and intuitive interface. For example, these are the key enabling technologies for automatic pronunciation verification. Similarly, speech can also be more than an interface for interactive STEM tutors. Speech provides a window into the learner's emotional state, which can be used to infer key factors such as the learner's degree of engagement and uncertainty. This, in turn, can influence the system's response to a correct or incorrect answer from the learner. For examples in physics tuition and shipboard damage control, see (Forbes-Riley and Litman, 2011) and (Pon-Barry et al, 2006), respectively.
Systems that use text for natural language interaction with STEM tutoring systems are more common than than those that use speech. The relative educational benefits of speech and text-based interaction with intelligent tutoring systems that support natural language dialogues are discussed in (D'Mello et al. 2011). Text-based intelligent STEM tutors have been investigated for physics (for example, Chi et al. 2011, Katz et al. 2011, Vanlehn et al. 2007, Katz et al. 2007), computer science (for example Kersey et al. 2010) and thermodynamics (for example, Rose et al. 2004)
Interspeech 2012 Special Session on Speech Technologies for STEM
The relative lack of significant activity in this area led to a successful proposal for a Special Session on “Speech Technologies for STEM” at Interspeech 2012 in Portland, Oregon (to be held on Tuesday 11th September 10:00-12:00). This session is intended to serve as a starting point for exploration of this new direction, revealing what has been learned so far about the use of speech and language in education that can be applied across learning disciplines, demonstrating what has been done so far in the area of STEM learning, and charting out possible research directions for future work. The special session will be sponsored by the U.S. National Science Foundation (NSF) as a vehicle to explore the possibility of a new research initiative based on its findings.
Eight papers will be presented at the Special Session, including papers that address some of the issues concerning the application of speech and language technology in STEM education that are discussed above. In addition, the session will cover the more general use of speech technology and spoken dialogue systems for education, intelligent tutoring systems using speech, the development of spoken language resources for educational applications, and the proper assessment of speech and speech technology applications.
Ronnie W. Smith, "An Evaluation of Strategies for Selective Utterance Verification for Spoken Natural Language Dialog", Proceedings of Fifth Conference on Applied Natural Language Processing, ANLP’96, 1996.
Wayne Ward, Ronald Cole, Daniel Bolaños, Cindy Buchenroth-Martin, Edward Svirsky, Sarel Van Vuuren, Timothy Weston, Jing Zheng, and Lee Becker, "My science tutor: A conversational multimedia virtual tutor for elementary school science". ACM Trans. Speech Lang. Process. 7, 4, Article 18, 2011.
Kate Forbes-Riley and Diane Litman, "Benefits and challenges of real-time uncertainty detection and adaptation in a spoken dialogue computer tutor", Speech Communication, 53, pp 1115-1136, 2011.
Heather Pon-Barry, Karl Schultz, Elizabeth Owen Bratt, Brady Clark, and Stanley Peters, .Responding to student uncertainty in spoken tutorial dialogue systems,. International Journal of Artificial Intelligence in Education, vol. 16, pp. 171.194, 2006.
Sidney K. D'Mello, Nia Dowell, and ArthurGraesser, "Does it really matter whether students' contributions are spoken versus typed in an intelligent tutoring system with natural language? ", Journal of Experimental Psychology: Applied, Vol 17(1), 1-17, 2011.
Min Chi, Kurt VanLehn, Diane Litman, and Pamela Jordan, "An Evaluation of Pedagogical Tutorial Tactics for a Natural Language Tutoring System: A Reinforcement Learning Approach",. International Journal of Artificial Intelligence in Education, 21(2), 83-113, 2011.
Sandra Katz, Patricia Albacete, Pamela Jordan and Diane Litman, "Dialogue Analysis to Inform the Development of a Natural-language Tutoring System for Physics", Proceedings Workshop on the Semantics and Pragmatics of Dialogue (SemDial), Los Angeles, CA, 2011.
K. Vanlehn, A. Graesser, G. T. Jackson, P. Jordan, A. Olney and C. Rose, "When are Tutorial Dialogues More Effective than Reading?" Cognitive Science 31(1), 3-62, 2007.
Sandra Katz, John Connelly and Christine Wilson, "Out of the lab and into the classroom: An evaluation of reflective dialogue in Andes". In R. Luckin, K. R. Koedinger, & J. Greer (Eds.), Artificial Intelligence in Education: Building Technology Rich Learning Contexts that Work, 425-432, 2007.
Cynthia Kersey, Barbara Di Eugenio, Pamela Jordan, and Sandra Katz, "KSC-PaL: A Peer Learning Agent", The 10th International Conference onIntelligent Tutoring Systems, ITS 2010.
Carolyn P. Rose, Rohit Kumar, Vincent Aleven, Allen Robinson and Chih Wu, "CycleTalk: Data Driven Design of Support for Simulation Based Learning", International Journal of Artificial Intelligence in Education, Special Issue "Best of ITS 2004" , 16, 195-223, 2004.
Abeer Alwan is with the Speech Processing and Auditory Perception Laboratory in the Electrical Engineering Department at UCLA, USA (email: alwan@ee.ucla.edu); Maxine Eskenazi is Principal Systems Scientist at the Language Technologies Institute, Carnegie Mellon University, Pittsburgh, USA (email: max+@cs.cmu.edu); Diane Litman is with the Department of Computer Science at the University of Pittsburgh, USA (email: litman@cs.pitt.edu
); Martin Russell is in the School of Electronic, Electrical and Computer Engineering at the University of Birmingham, UK (email: m.j.russell@bham.ac.uk); Klaus Zechner is a Managing Senior Research Scientist at the Educational Testing Service (email: kzechner@ets.org)
The Silent Speech Bandwidth Revolution in Mobile Telephony
Just over 150 years after Philipp Rice’s first successfully working “telephone” in 1861, we are still quite familiar with the pitfalls and restrictions of the limited bandwidth of the past centuries’
–and widely today’s–telephony.
The classical wireline “narrowband” speech bandwidth
ranged from 300-3400 Hz, resulting in a syllable intelligibility of about 90%.
Why could we still understand each other quite well? A researcher in automatic
speech recognition would respond: Because
we employ a “lexicon” and a sophisticated “language model” exploiting contexts.
In business calls many of us communicate in a foreign
language, experiencing a drop in intelligibility due to the limited speech
bandwidth of the phone. Of course our personal lexicon and language model are
weaker in a foreign language. Another example is proper names and geographic
names, where we often experience a lack of robustness in phone conversation: Our
language model does not help here. So we spell these words, with the
consequence that intelligibility gets even worse. So finally we are forced to
employ a spelling alphabet… Are we really living in the age of global
communication? In the 21st century?
Wideband Speech: The First Steps
Luckily, wideband speech, with a bandwidth from 50-7000
Hz, provides a comfortable syllable intelligibility of 98%. It has been
supported in digital speech transmission since 1988 with the ITU-T G.722
wideband speech codec in ISDN and teleconferencing systems. The same
speech codec was employed in a new generation of DECT standards in 2007
introducing cordless telephony with
wideband speech. Let us consider intellectual property rights (IPRs): Is it by
chance that it took 20 years for digital wideband speech to become cordless?
In mobile telephony, the adaptive multi-rate wideband speech codec (WB-AMR) was
standardized in 2001 within the 3rd Generation Partnership Project
(3GPP), in the same year adopted by ITU-T as G.722.2. Some of us hoped to
see mobile wideband speech in the market soon, but the 2001 telecom/IT crisis
severely postponed investments on that long-awaited technology.
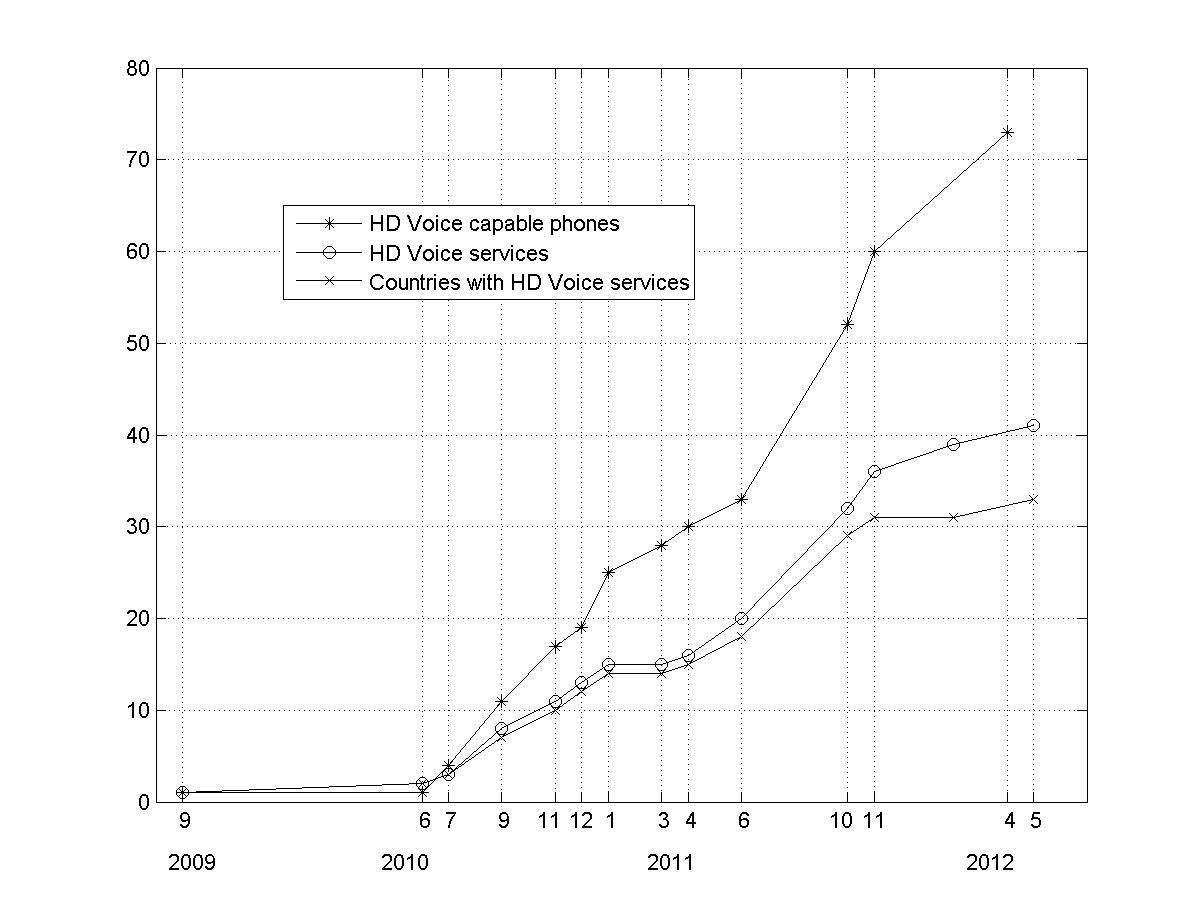
HD Voice
It was about 10 years later that so-called high-definition (HD) Voice services supporting
mobile wideband speech were actually implemented (see Figure). After a first
mobile network in Moldova in 2009, the past 3 years have seen a tremendous
increase of HD Voice mobile networks and phones [1]. Luckily, IPR issues did not seem
to be a blocking point.
Figure: Implementation of mobile HD Voice services (wideband speech networks) and
availability of HD Voice capable phones (Sources to the numbers: [1])
For mobile telephony we could consider it a
revolution. However, it happened quite silently, but it is now that we can ask
in more than 30 countries for high-quality mobile phones supporting HD Voice,
given the right contract with the right provider. Many providers offer HD Voice
with no additional cost but restrict it – sometimes – to 3rd
generation and Long-Term Evolution (LTE) networks.
In voice over IP
– let’s take Skype-to-Skype calls as an example – we can enjoy wideband speech
already for a while, and in 2009 Skype introduced speech coding with speech
sampling rates of up to 16 and 24 kHz, the latter providing even more than
wideband experience. In recent years, both ITU-T and MPEG standardization
bodies have released speech and audio codecs for wideband voice over IP, super-wideband
(50-14000 Hz), or even full-band (20-20000 Hz). We should just note that whoever
claims high audio fidelity still requires a bit more latency and/or a slightly higher
bitrate as opposed to classic speech codecs, not necessarily being robust to
bit errors as they occur in low-latency circuit-switched mobile phone calls.
As mobile telephony today allows not only for the conservative low-latency circuit-switched design, but also for
packet-switched IP multimedia subsystem (IMS) or voice over IP designs, mobile
speech communication supporting wideband or even more speech bandwidth is
possible in a variety of ways. We just need to ask for it – and experience what
we have waited for the last 150 years, given, that our communication partner’s
phone and provider supports the same speech bandwidth. The missing technical
equipment at the far-end, however, is a known issue with innovations in
telecommunications; just think of the first fax machine owner. Yet at some point
the fax eventually forged ahead into the offices, likewise HD Voice may do into mobile phones...
Reference
[1] Global Mobile Suppliers Association GSA, www.gsacom.com
If you have comments, corrections, or additions to this article, please contact the author: Tim Fingscheidt, fingscheidt [at] ifn.ing.tu-bs.de.
Tim Fingscheidt is Full Professor at Technische Universität Braunschweig, Germany. His interests are speech transmission and enhancement.
An Overview of Speech and Related Papers @ ACL 2012
ACL 2012 covered a broad spectrum of disciplines working towards enabling intelligent systems to interact with humans using natural language,
and towards enhancing human-human communication through services such as speech recognition, automatic translation, information retrieval,
text summarization, and information extraction. This article summarizes the speech papers specifically advances on acoustic and
language modeling as well as speech related papers on language acquisition, phonemes and words.
The selected articles are noteworthy of their individual fields as the novel approaches presented in these papers outperform the baselines.
For further reading please refer to the proceedings [1].
Introduction
This year, Jeju Island, South Korea hosted the 50th Anniversary of the Association for Computational Linguistics (ACL 2012).
Renowned scholar Aravind K. Joshi, Henry Salvatori Professor, Computer and Cognitive Science University of Pennsylvania, delivered the conference keynote address,
“Remembrance of ACL’s past,” discussing the research trends in ACL research papers over the last 50 years. During the three-day conference there were very interesting
talks on machine translation, parsing, generation, NLP applications, dialog, discourse and social media. There were four tracks on speech and speech related topics and
several other tracks also played host to speech-related papers,
including the tracks on machine learning, phonemes, and words.
(i) ASR and Related Topics
One of the noteworthy papers in the first speech session was by Lee and Glass [2] on a non-parametric Bayesian approach to acoustic modeling
that learns a set of sub-word units to represent the spoken data. Specifically, given a set of spoken utterances, their latent variable model
jointly learns a segmentation to find the phonetic boundaries within each utterance, clusters the acoustically similar segments together and then models
each sub-word acoustic unit using HMM. They compare the phonetic boundaries captured by their model to the manual labels in their dataset, which is described in Dusan and Rabiner’s paper [3].
Their results show striking correlations between the manual cluster labels and the indication English phones, which shows that without any language-specific knowledge,
their model is able to discover the phonetic composition of a set of speech data. In addition, they compare their results to supervised acoustic models including English
triphone and monophone models as well as Thai monophone models. Their results indicate that even without supervision their model can capture and learn the acoustic
characteristics of a language and produce an acoustic model that outperforms a language-mismatched acoustic model trained with high supervision.
Another conversational speech paper was by Tang et al. [4], in which the authors introduce a
Discriminative Pronunciation Modeling approach to tackle ASR issues while mapping between words and
their possible pronunciations in terms of sub-word units (phones). A general approach to this problem is using a generative approach
(which models the joint distribution between input and output variables), which provides distributions over possible pronunciations given the canonical ones
[5], [6], [7], [8] In some recent work the generative models are discriminatively optimized to obtain better accuracy. In this paper a flexible discriminative
approach is used to build a pronunciation model. They provide detailed information about the features of their linear model. They compare their proposed pronunciation model
to Zweig et.al.’s CRF based speech recognizer [9].
Benchmark analyses indicate that their models are sparser, much faster and perform better when they use a large set of feature functions.
(ii) Language Modeling
Recent language modeling (LM) research work shows that incorporating long-distance dependencies and syntactic structure helps
LM’s better predict words by complementing the predictive power of n-grams. Current state-of-the-art methods that capture the long term dependencies
use generative or discriminative approaches, which can be slow, often cannot work directly with lattices or require rescoring large N-best lists.
Additionally, such approaches use non-local features for rescoring (usually by using auxiliary tools such as POS or parsers) which introduces major inefficiencies.
Thus, Rastrow et.al. [10] introduce Sub-Structure Sharing, which is a general framework that greatly improves the speed of auxiliary syntactic tools that utilize
the commonalities among the set of generated hypotheses (lattices). Specifically, their key idea is to share substructure states in transition-based structure prediction algorithms
where final structures are composed of a sequence of multiple individual decisions. Specifically, in a sub-structure sharing, a transition (or action) ??O is learned
by a classifier trained on labeled data. The classification model summarizes the states as vectors of features, and g imposes the same distribution over actions if the states are equivalent.
This way the states and their distribution over actions are stored to be re-used at test time. They also use an up-training method to improve the accuracy of their decoder’s performance.
With their experiments on real data they show improvements on the speed of the language models without degrading performance
(iii) Lexical and Phonetic Acquisition
There were two notable papers on child language acquisition, each looking at different aspects of speech.
Elsner et.al. [11] investigate infant language acquisition by jointly learning the lexicon and phonetics.
Specifically, their joint lexical-phonetic model infers intended forms from segmented surface forms.
This enables variability in modeling and improves the accuracy of the learned lexicon over a system that assumes
each intended form as a unique surface form. They introduce a hierarchal Bayesian framework that generates intended word tokens
using a language modeling structure and then transforms each token by a probabilistic finite-state transducer to produce the observed surface sequence.
Their transducer is parameterized by probabilities obtained from another log-linear model, which uses features based on articulatory phonetics.
They show that modeling variability improves the accuracy of the learned lexicon.
Shakian and Snyder [12] investigate automatic learning metrics for child language learning.
Measuring language learning at early ages is crucial since these measures can help to diagnose early language disorders. The authors extract several features from CHILDES,
a collection of corpora of child language based on episodic speech data, including histories of longitudinal studies of individual children. Beyond three standard metrics of language development,
namely utterance length, syntactic complexity, and linguistic competence, they introduce additional measures: obligatory morpheme counts (articles and contracted auxiliary “be” verbs);
preposition occurrences; and vocabulary-centric features (counts of function words, prepositions, pronouns, conjunctions, etc). For individual children evaluations,
they use least-squares regression over introduced features to predict the age of a held-out language sample.
They find that, on average, existing single metrics of development are outperformed by a weighted combination of proposed features.
This article briefly summarized selected speech and related articles presented at the ACL’2012 as three sections,
namely speech recognition, language modeling and lexical and phonetic acquisition. For further details on the summarized papers and others please refer to the ACL’s online proceedings [1].
Asli Celikyilmaz is Senior Speech Scientist at Microsoft Silicon Valley. Her interests are in Natural Language Processing,
Conversational Understanding and Machine Learning.
[2] C.-y. Lee and J. Glass, "A Nonparametric Bayesian Approach to Acoustic Model Discovery," In ACL, 2012.
[3] S. Dusan and L. Rabiner, "On the relation between maximum spectral transition positions and phone boundaries," In INTERSPEECH, 2006.
[4] H. Tang, J. Keshet and K. Livescu, "Discriminative Pronunciation Modeling: A Large-Margin, Feature-Rich Approach," In ACl, 2012.
[5] T. Holter and T. Svendsen, "Maximum likelihood modelling of pronunciation variation," In Speech Communication, 1999.
[6] M. Riley, W. Byrne, M. Finke, S. Khudanpur, A. Ljolje, J. McDonough, H. Nock, M. Saraclar, C. Wooters and G. Zavaliagkos, "Stochastic pronunciation modelling from hand-labeled phonetic corpora," In Speech Communication, 1999.
[7] B. Hutchinson and J. Droppo, "Learning nonparametric models of pronunciation," in Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), 2011.
[8] K. Filali and J. Bilmes, "A dynamic Bayesian framework to model context and memory in edit distance learning: An application to pronunciation classification.," In Proc. Association for Computational Longuistics (ACL), 2005.
[9] G. Zweig, P. Nguyen, D. V. Compernolle, K. Demuynck, L. Atlas, P. Clark, G. Sell, M. Wang, F. Sha, H. Hermansky, D. Karakos, A. Jansen, S. Thomas, S.G.S.V.S, S. Bowman and J. Kao, "Speech Recognition with Segmental Conditional Random Fields," In Interspeech, 2011.
[10] A. Rastrow, M. Dredze and S. Khudanpur, "Fast Syntactic Analysis for Statistical Language Modeling via Substructure Sharing and Uptraining," In ACL, 2012.
[11] M. Elsner, S. Goldwater and J. Eisenstein, "Boostrapping a Unified Model of Lexical and Phonetic Acquisition," In ACL, 2012.
[12] S. Shakian and B. Snyder, "Automatically Learning Measures of Child Language Development," In ACL, 2012.
[13] X. Peng, D. Ke and B. Xu, "Automated Essay Scoring Based on Finite State Transducer: towards ASR Transcription of Oral English Speech," In ACL, 2012.
[14] T. Holter and T. Svendsen, "Maximum likelihood modelling of pronunciation variation," In Speech Communication, 1999.
[15] M. Riley, W. Byrne, M. Finke, S. Khudanpur, A. Ljolje, J. McDonough, H. Nock, M. Saraclar, C. Wooters and G. Zavaliagkos, "Stochastic pronunciation modeling from hand-labeled phonetic corpora," In Speech Communication, vol. 29, pp. 2-4, 1999.
If you have comments, corrections, or additions to this article, please contact the author: Asli Celikyilmaz, asli [at] ieee [dot] org.
The Dialog State Tracking Challenge
A new corpus-based research community challenge task to accurately estimate the goal of a user interacting with a spoken dialog system.
Introduction
In dialog systems, "state tracking" – sometimes also called "belief tracking" – refers to accurately estimating the user’s goal as a dialog progresses. Accurate state tracking is desirable because it provides robustness to errors in speech recognition, and helps reduce ambiguity inherent in language within a temporal process like dialog. Dialog state tracking is an important problem for both traditional uni-modal dialog systems, as well as speech-enabled multi-modal dialog systems on mobile devices, on tablet computers, and in automobiles.
Recently, a host of models have been proposed for dialog state tracking, including partitioning [1,2,3,4], Bayesian networks [5,6], probabilistic ontology trees [7], probabilistic rules [8], and discriminative models [9], and Markov logic [10], among others. However, comparisons among models are rare, and different research groups use different data from disparate domains. Moreover, there is currently no common dataset which enables off-line dialog state tracking experiments, so newcomers to the area must first collect dialog data, which is expensive and time-consuming, or resort to simulated dialog data, which can be unreliable. All of these issues hinder advancing the state-of-the-art.
Challenge overview
In this challenge, participants will use a provided set of labeled dialogs to develop a dialog state tracking algorithm. Algorithm will then be evaluated on a common set of held-out dialogs, to enable comparisons [11].
The data for this challenge will be taken from the Spoken Dialog Challenge [12], which consists of human/machine spoken dialogs with real users (not usability subjects). Before the start of the challenge, a draft of the labeling guide and evaluation measures will be published, and comments will be invited from the community. The organizers will then perform the labeling.
At the start of the challenge – the development phase – participants will be provided with a training set of transcribed and labeled dialogs. Participants will also be given code that implements the evaluation measurements. Participants will then have several months to optimize their algorithms.
At the end of the challenge, participants will be given an untranscribed and unlabeled test set, and a short period to run their algorithm against the test set. Participants will submit their algorithms’ output to the organizers, who will then perform the evaluation. After the challenge, the test set transcriptions and labels will be made public.
To participate, email jason.williams@microsoft.com to register. Registered participants will be provided with a link to download the data and evaluation tools, once they are available. We are also currently assembling an advisory committee.
Results of the evaluation will be reported to the community. In this challenge, the identities of participants will not be made public in any written results by the organizers or participants, except that participants may identify themselves (only) in their own written results.
Schedule
1 July 2012: Beginning of comment period on labeling and evaluation metrics
4-6 July 2012: YRRSDS and SigDial in Korea: announcement of comment period
17 August 2012: End of comment period on labeling and evaluation metrics
31 August 2012: Evaluation metrics and labeling guide published; labeling begins
3 December 2012: Labeling ends; data available; challenge begins (3 months)
3-5 December 2012: IEEE SLT 2012 (Miami): Announcement, mini-tutorial?
15 March 2013: Final system due; evaluation begins (3.5 months)
22 March 2013: Evaluation output due (1 week)
29 March 2013: Results sent to teams (1 week)
1 May 2013: Approximate deadline for SigDial papers (1 month)
August 2013: SigDial 2013
Organizers
Jason Williams, Microsoft Research (chair)
Alan Black, Carnegie Mellon University
Deepak Ramachandran, Honda Research Institute
Antoine Raux, Honda Research Institute
References
[1] R. Higashinaka, M. Nakano, and K. Aikawa, "Corpus-based discourse understanding in spoken dialogue systems," in Proceedings of ACL, Sapporo, Japan, 2003, pp. 240–247.
[2] S. Young, M. Gasic, S. Keizer, F. Mairesse, J. Schatzmann, B. Thomson, and K. Yu, "The Hidden Information State Model: a practical framework for POMDP-based spoken dialogue management," Computer Speech and Language, vol. 24, no. 2, pp. 150–174, 2010.
[3] J. Williams, "Incremental Partition Recombination for Efficient Tracking of Multiple Dialogue States." in Proceedings of ICASSP, Dallas, Texas, 2010, pp. 5382–5385.
[4] M. Gasic and S. Young, "Effective Handling of Dialogue State in the Hidden Information State POMDP Dialogue Manager," ACM Transactions on Speech and Language Processing, vol. 7, no. 3, 2011.
[5] B. Thomson and S. Young, "Bayesian update of dialogue state: A POMDP framework for spoken dialogue systems," Computer Speech and Language, vol. 24, no. 4, pp. 562–588, 2010.
[6] J. D. Williams, "Using particle filters to track dialogue state," in Proceedings of ASRU, Kyoto, Japan, 2007, pp. 502 – 507.
[7] Neville Mehta, Rakesh Gupta, Antoine Raux, Deepak Ramachandran, Stefan Krawczyk. "Probabilistic Ontology Trees for Belief Tracking in Dialog Systems". Proc SigDial 2010.
[8] Pierre Lison. "Probabilistic Dialogue Models with Prior Domain Knowledge". Proc SigDial 2012.
[9] D. Bohus and A. Rudnicky, "A ‘K hypotheses + other’ belief updating model," in Proceedings of the AAAI Workshop on Statistical and Empirical Approaches for Spoken Dialogue Systems, Boston, Massachusetts, 2006, p. 1318.
[10] Casey Kennington and David Schlangen. "Markov Logic Networks for Situated Incremental Natural Language Understanding". Proc SigDial 2012.
[11] A. W. Black, S. Burger, A. Conkie, H. Hastie, S. Keizer, O. Lemon, N. Merigaud, G. Parent, G. Schubiner, B. Thomson, J. D. Williams, K. Yu, S. Young and M. Eskenazi. (2011) Spoken Dialog Challenge 2010: Comparison of Live and Control Test Results . SIGDial 2011.
[12] J. D. Williams. (2012) A belief tracking challenge task for spoken dialog systems. NAACL Workshop on Future directions and needs in the Spoken Dialog Community: Tools and Data. NAACL 2012.
Jason Williams is Researcher at Microsoft Research, Redmond, Washington, USA. His interests are dialog systems and planning under uncertainty. Email: jason.williams@microsoft.com.
Dimitri Kanevsky Recognized by White House for Champion for Change Award
Dr. Dimitri Kanevsky, a researcher in the Speech and Language Algorithms group at IBM T.J. Watson Research Center, recently received the "Champion for Change" Award at the White House. This award recognizes individuals "for leading education and employment efforts in science, technology, engineering and math for Americans with disabilities."
Kanevsky holds over 150 U.S. patents and is continually looking for solutions to challenges he faces in every day life. As Dimitri views it, technology is constantly evolving to remove barriers that emerge due to a person's social characteristics, geographic location, physical or sensory abilities. Many of his technologies focus specifically on improving daily lives for people with disabilities, something also personal to Dimitri because he has been deaf since the age of 3.
For example, Kanevsky's patent on "Improving Data Access for Users with Special Needs" [1] allows users with different types of disabilities to easily access data on computers. For example, if a person is blind, the technology transforms visual data into audio so a person can hear on his laptop. In addition, some people with mental disabilities cannot understand complex text, so the invention transforms complex to simple text. Furthermore, if a person cannot view small fonts, the technology will increase the font size automatically on the computer so the person can read.
One of Dimitri's most well known inventions is Artificial Passenger, a telematic device (i.e., a device that integrates the use of telecommunications and informatics) that tries to prevent a driver from falling asleep by engaging in dialog with the driver. In fact, Kanevsky came up with the idea after keeping his wife awake by talking to her on a late night drive. The system keeps the user awake by playing music for the driver, telling jokes, etc. The system can also detect fluctuations in a driver's voice to determine if the driver is sleepy, and try to wake the driver up methods such as opening the window or playing games with the driver. This invention helped create a new direction of using smart electronics in cars, including methodologies which read drivers biometrics, detect drivers conditions, and interact with drivers [2].
In addition, Kanevsky also created an invention to address the problem of authenticating users when calling into secure locations, such as banks [3]. This patent was selected as one of top 5 patents issued in 2003 by MIT Technology Review. Previously, when a user called a bank the user would be asked only one simple question to authenticate himself/herself, such as "what is the name of your spouse's mother". Kanevsky's patent looks at creating a database of random questions to ask the user (to which the user knows all the answers), rather than just one. Furthermore, the system also checks for the voice identity of the speaker, which was one of the first such inventions to look at conversational biometrics.
There is no doubt that some of Kanevsky's most important inventions are still to come. He believes technological innovation in areas such as large-scale learning and nano-technology could have a large impact in society
References
[1] D. Kanevsky and A. Zlatsin, "Universal translator/mediator server for improved access by users with special needs," US Patent US6665642
[2] D. Kanevsky and W. Zadrozny, "Sleep prevention dialog based car system", US patent US6236968
[3] D. Kanevsky and S. Maes, "Apparatus and methods for speaker verification/identification/classification employing non-acoustic and/or acoustic models and databases", US patent US 6529871
If you have comments, corrections, or additions to this article,
please contact the author: Tara Sainath, tsainath [at] us [dot] ibm
[dot] com.
Tara Sainath is a Research Staff Member at IBM T.J. Watson Research Center in New York. Her research interests are mainly in acoustic modeling. Email: tsainath@us.ibm.com
CL for Literature Workshop at NAACL/HLT 2012
Antonio Roque
SLTC Newsletter, August 2012
The Computational Linguistics for Literature Workshop was recently held at NAACL-HLT 2012 in Montreal on June 8.
Researchers presented work such as authorship attribution, stylometry, extracting information from literary sources, focusing on the unique challenges of handling literary texts.
In the workshop's first session, Choonkyu Lee, Smaranda Muresan, and Karin Stromswold discussed how referring expressions in picture books varied based on event intervals, and described attempts to apply state-of-the-art coreference resolution systems to the task.
In the second session, Justine Kao and Dan Jurafsky used statistical methods to identify a subset of poetry that privileges references to concrete objects. Rob Voigt and Dan Jurafsky examined how referential cohesion ("the relation between co-referring entities in a narrative") affected translation of literary texts. Next, Julian Brooke, Adam Hammond, and Graeme Hirst computationally segmented a poem using stylistic variations.
In the third session, Qian Yu, Aurelien Max and Francois Yvon discussed experiments in sentence alignment of literary works for machine translation. The workshop began with an invited talk by Inderjeet Mani on a framework for narrative computing, and ended with poster and discussion sessions.
Overview of the Workshop on Future directions and needs in the Spoken Dialog Community: Tools and Data
Svetlana Stoyanchev
SLTC Newsletter, August 2012
The Workshop on Future directions and needs in Spoken Dialog Community was collocated with NAACL2012. The goal of the workshop was to find common threads for binding the dialog research community together and fostering growth of the field and the community. This article overviews the topics addressed at the workshop and presents discussion outcomes from the break-out sessions of the workshop.
The workshop was organized by Maxine Eskenazi (Carnegie Mellon Univ.), Alan Black (Carnegie Mellon Univ.), and David Traum (USC Institute for Creative Technologies). The workshop was sponsored by the Dialog Research Center (DialRC), a project funded by the NSF Community Research Initiative (CRI) Program. Last year, DialRC organized the first dialog system challenge offering the participants a research platform with access to real users and training data in the domain of bus information.
The workshop brought together a diverse community of researchers working on different aspects of dialog, both in the industry and academia. Dialog systems research field has a notoriously high entry barrier requiring a significant investment for building a functional Spoken Dialog System (SDS). Common tools, data, frameworks, and components empower growth of the field by facilitating entry for new researchers and allowing them to focus on research questions rather than engineering of an SDS. In this workshop researchers from different areas of SDS gathered to discuss directions for advancing research on spoken dialog. The participants also discussed potential tasks and domains for the future spoken dialog challenge.
To address diverse areas of the research community, the workshop presentations were grouped into the following areas:
Knowledge Acquisition and Resource Creation
Assessment
New Technologies for Spoken Dialog Systems
Architectures
Community Building
The workshop features 19 position papers on the areas above. The papers are now available on the workshop website.
Overview of the Addressed Areas
In the morning session, the group leaders discussed challenges and recent advances in each of the workshop areas.
Current trends in dialog architecture research are focused on Situated, Incremental, Pervasive, and long-term Adaptive dialog. Situated dialog system, such as a robot in a physical environment or a multimodal interface in a hotel lobby, in addition to speech context, uses an increased context of the surrounding environment. Situated interaction manages parallel and coordinated actions receiving physical and environmental stimuli in addition to the verbal ones. Incremental paradigm moves away from strict turn-taking where a system processes complete utterances towards the systems capable of processing partial input. Pervasive systems are contrasted with information extracting systems. Previous work in dialog community has focused on extracting information, such as airline and bus schedules, or tourist attractions. In contrast, dialog systems on mobile devices today cover a variety of topics from searching for a movie to adding an event in a calendar. The challenge for the dialog research emphasized in [1, 2] lies in transferring knowledge across domains and reusing system behaviour for the different domains covered by the system.
Presenters on multiple workshop areas emphasized the importance on dialog system's learning capabilities, proposing online learning and long-term adaptation to a user. With today's ubiquitous ownership of smart-phone devices that run pervasive dialog systems, there is a room for exploring long-term adaptive system capabilities where a system learns from its own errors by improving its internal models and builds personal common ground with a user based on the interaction [3]. Cuayáhuitl and Dethlefs [2] argue for online learning where a system learns and updates its models continuously after every dialog act rather than after hundreds of dialogs. Ultes et al. [4] underline the need to use evaluation metrics for improvement of a dialog system by incorporating dialog quality information into the dialog manager (DM) in order to enable DM to be quality-adaptive.
Pietquin [5] questions the current approach to user simulations which is used for training statistical dialog managers with reinforcement learning methods by generating artificial interactions between a user and a system. Current user simulations are generative systems that generate single dialog acts according to context. The author proposes to redefine user simulation as a sequential decision making problem modelling users' long-term goals.
Assessment (or evaluation) of SDS is challenging due to interactive nature of SDS where user input is generally unpredictable making corpus-based evaluation not directly possible. Typical approaches to SDS evaluation include manual evaluation, which is expensive, and prediction of manual judgements, which maps objective performance metrics of an SDS to subjective user ratings [9]. Mõller et al. [6] discuss the importance of standardised metrics for dialog system and mention the two metrics developed by the International Telecommunication Union (ITU-T): for spoken dialog systems (ITU-T Suppl. 24 to P-Series, 2005), and for multimodal systems (ITU-T Suppl. 25 to P-Series Rec., 2011).
Building new SDS or porting SDS to new domains and languages currently requires iterative tuning and expertise in language engineering. Lack of availability of linguistic resources for building and porting SDS is one of the challenges for rapid development of new systems. A European project PortDial: Language Resources for Portable Multilingual Spoken Dialog Systems, proposes development of technologies for creating "such linguistic resources automatically or semi-automatically using data that is either harvested from the web or via community crowdsourcing using the 'collective wisdom of expert crowds'"[7].
Group Discussion Outcomes
In the afternoon session of the workshop, the groups met in a break-out sessions to discuss the concrete tasks for the community that would lower a barrier for entering the field and foster research on SDS.
The Architecture team discussion addressed the high entry cost barriers challenges for SDS research on situated and incremental interaction. The participants teamed together to create an initiative that focuses on lowering this entry barrier. The group agreed to create a Wiki documents on best practices in hardware, software and tools, and evaluation methods. These documents are intended to be guides for the new researchers and facilitate their effort when entering the field. The team also plans to lower the collaboration costs by running a community building effort with a special session in a near-future HRI/IVA/ICMI conferences with Dan Bohus from Microsoft Research leading this effort.
The New Technologies team has come up with a list of possible challenge topics for the next spoken dialog challenge, including belief tracking, anaphora resolution, user simulation, policy learning, and learning from human-human interactions. Belief tracking, advocated for an SDS challenge in [8], keeps a distribution of user goals across possible states given dialog history. This method has a potential to add robustness to ASR errors. Comparison and evaluation of different methods of belief tracking in a Spoken Dialog challenge would help answer an empirical question whether this approach can improve dialog system performance and should be pursued in commercial systems. The belief tracking challenge has now been announced and is described in {cms_selflink page='846' text='the article by Jason Williams'}.
The outcomes of the discussion on assessment included proposal to use crowdsourcing for reducing cost of manual evaluation. In order to compare across different dialog systems, the group proposed to come up with a scalar quality score that incorporates dialog qualities like concept error rate, task completion, missed speech inputs, and perceived interaction quality.
Building community group advocated building systems for real tasks, real users, and real needs. The group proposed to hold SDS tutorial outreach at major conferences
such as ACL; to run summer schools on topics relevant to SDS; to
develop tutorials that target humanities and social science
researchers who may be interested in getting into SDS research; and to
create online recordings of workshops, ISCA and SIGdial talks. 'Talking to the Twins', following ICT's dialog system installed at the Boston Museum of Science, was discussed as another possible SDS challenge domain.
The discussion on knowledge acquisition and resource creation emphasized that companies, such as Microsoft and AT&T own large amounts of dialog and interaction data. This data would be a significant benefit for research community, however legal and commercial barriers for public release of this data are currently an issue. Maintaining privacy of the customers while releasing their data is also a concern for companies. The participants from commercial research laboratories have agreed to initiate discussions within their companies to establish a process for making some of their data public for research purposes.
For more information, see:
[1] A. Stent After Dialog Went Pervasive: Separating Dialog Behavior Modeling and
Task Modeling, Workshop on Future directions and needs in the Spoken Dialog Community: Tools and Data, 2012
[2] H. Cuayáhuitl, N. Dethlefs Dialogue Systems Using Online Learning: Beyond Empirical Methods
Workshop on Future directions and needs in the Spoken Dialog Community: Tools and Data, 2012
[3] D. Schlangen The Future of Spoken Dialogue Systems is in their Past:
Long-Term Adaptive, Conversational Assistants, Workshop on Future directions and needs in the Spoken Dialog Community: Tools and Data
[4] S. Ultes, A. Schmitt, W. Minker Towards Quality-Adaptive Spoken Dialogue Management, Workshop on Future directions and needs in the Spoken Dialog Community: Tools and Data, 2012
[5] O. Pietquin Statistical User Simulation for Spoken Dialogue Systems:
What for, Which Data, Which Future?, Workshop on Future directions and needs in the Spoken Dialog Community: Tools and Data, 2012
[6] S. Möller et al. Position Paper: Towards Standardized Metrics and Tools
for Spoken and Multimodal Dialog System Evaluation
, Workshop on Future directions and needs in the Spoken Dialog Community: Tools and Data, 2012
[7] G. Riccardi Up from Limited Dialog Systems!, Workshop on Future directions and needs in the Spoken Dialog Community: Tools and Data, 2012
[8] J. Williams A belief tracking challenge task for spoken dialog systems, Workshop on Future directions and needs in the Spoken Dialog Community: Tools and Data, 2012
[9] M. Walker, et al. PARADISE: A Framework for Evaluating Spoken Dialogue Agents, In Proceedings of the 35th Annual Meeting of the Association of Computational Linguistics , ACL 97, 1997
If you have comments, corrections, or additions to this article, please contact the author: Svetlana Stoyanchev, sstoyanchev [at] cs [dot] columbia [dot] edu.
Svetlana Stoyanchev is a Postdoctoral Research Fellow at Columbia University. Her interests are in error handling and information presentation in spoken dialogue.
Odyssey 2012: The Speaker and Language Recognition Workshop
Nancy Chen and Haizhou Li
SLTC Newsletter, August 2012
Odyssey is the flagship event of the Speaker and Language Characterization Special Interest Group (SIG-SpLC) of the International Speech Communication Association (ISCA), which is held once every two years. Odyssey 2012 was held on 25-28 June in Singapore with the theme: "Celebrating the Diversity of Speakers and Languages".
Since Odyssey's inception in Martigny, Switzerland in 1994, this is the first time the Odyssey workshop is held in Asia. Singapore's rich linguistic landscape, carved by multi-cultural immigrants and its colonial heritage, makes it a unique place to celebrate the diversity of speakers and languages. The local Singlish dialect is a vivid and colorful example of how languages and speakers interact and mingle: while Singlish is a dialect of English, it is interleaved with slangs from languages such as Hokkien, Malay and Tamil, and heavily influenced by Chinese grammar and prosody. The complexity of Singlish exemplifies the challenges speech researchers face in developing technology to automatically recognize speakers and spoken languages.
Odyssey 2012 was organized by the Institute for Infocomm Research (I2R), the Chinese and Oriental Languages Information Processing Society (COLIPS), and ISCA SIG-SpLC. Other organizations such as the Lee Foundation, Temasek Laboratories at Nanyang Technological University, and the International Speech Communication Association (ISCA) have financially supported the event.
Odyssey 2012 technical sessions are well-received.
The technical program was organized into 11 oral sessions, where researchers presented their latest endeavours and insights from multiple aspects, covering speaker and language characterization, modelling, evaluations, and applications. Odyssey 2012 also featured 3 invited speeches: Dr. Niko Brümmer (Agnitio Corporation) discussed how proper scoring rules adopted from weather prediction can be applied to pattern recognition to make probabilistic decisions; Dr. Li Deng (Microsoft Research) talked about how new generation models such as deep belief networks and dynamic Bayesian networks can revamp the traditional framework of Gaussian mixture model and hidden Markov model in speech technology; and Dr. Alvin Martin (National Institute of Standards and Technology) shared the history of past NIST Speaker Recognition Evaluation Series and its future directions.
Participants touring the Tiger Brewery at the welcome reception.
In addition to the lively and intellectual discussions during the technical sessions, the social activities were also enthusiastically attended. Cheerful conversations sparkled with vivacious laughter continued at every social event, be it the welcome reception at the Tiger Brewery, the coffee breaks with Malay refreshments, the boat cruise along the Singapore River, the ride on the world's largest observation wheel, and the banquet fusing western delicacies (e.g., foie gras) with a touch of Southeast Asian spices. A true and local Singaporean would say the Odyssey 2012 experience was damn shiok (A Singlish term used to express sheer pleasure and great satisfaction. Shiok originates from shauk in Punjabi.); we believe all the participants felt the same way.
Odyssey 2014 will be held in Joensuu, Finland.
Nancy Chen is a research staff member at the Human Language Technology Department at the Institute for Infocomm Research, Singapore. Her research interests are in dialect/language recognition and spoken language understanding. For more information: http://alum.mit.edu/www/nancychen.
Haizhou Li is the Head of Human Language Technology Department at Institute for Infocomm Research. His research interests are speech processing and computational linguistics.
 We just experienced an outstanding IEEE ICASSP-2012 conference in Kyoto, Japan (March 25-30), with approximately 300 papers relating to speech and language processing presented (the next IEEE ICASSP will be held in Vancouver, Canada, May 26-31, 2013,
We just experienced an outstanding IEEE ICASSP-2012 conference in Kyoto, Japan (March 25-30), with approximately 300 papers relating to speech and language processing presented (the next IEEE ICASSP will be held in Vancouver, Canada, May 26-31, 2013, http://www.icassp2013.com/; Tutorial and Special Session Proposals due by Sept. 10, 2012). However, our SLTC community continues to reach out to support other conferences and workshops related to speech, spoken language, audio, multi-media processing, and other areas.
http://www.icassp2013.com/; Tutorial and Special Session Proposals due by Sept. 10, 2012). However, our SLTC community continues to reach out to support other conferences and workshops related to speech, spoken language, audio, multi-media processing, and other areas.
 Interspeech draws from its roots in two conferences - the ICSLP (Inter. Conf. of Spoken Language Processing) conference series, which began in 1990 with emphasis on acoustic-phonetics, linguistics, speech science, perception, etc., along with the Eurospeech conference series, which emphasized both speech technology and speech processing research. The Interspeech conference, at least from my perspective, has never been in competition with IEEE ICASSP, but in fact complements the signal processing emphasis we enjoy in the papers presented at ICASSP. In fact, over the years there has been a significant increase in the amount of "speech/language/hearing" science in papers at ICASSP, and one might argue that the presence of ICASSP has served to increase the level of engineering and speech/language technology seen at Interspeech. In any event, I would like to encourage our membership and participants of IEEE ICASSP to venture out (if you have not done so already!) and consider attending Interspeech. Increasing the science content and knowledge of our field can only serve to strengthen the impact of the technical advancements from our work!
Interspeech draws from its roots in two conferences - the ICSLP (Inter. Conf. of Spoken Language Processing) conference series, which began in 1990 with emphasis on acoustic-phonetics, linguistics, speech science, perception, etc., along with the Eurospeech conference series, which emphasized both speech technology and speech processing research. The Interspeech conference, at least from my perspective, has never been in competition with IEEE ICASSP, but in fact complements the signal processing emphasis we enjoy in the papers presented at ICASSP. In fact, over the years there has been a significant increase in the amount of "speech/language/hearing" science in papers at ICASSP, and one might argue that the presence of ICASSP has served to increase the level of engineering and speech/language technology seen at Interspeech. In any event, I would like to encourage our membership and participants of IEEE ICASSP to venture out (if you have not done so already!) and consider attending Interspeech. Increasing the science content and knowledge of our field can only serve to strengthen the impact of the technical advancements from our work!
 It is with sadness that the Dept. of Electrical Engineering, Univ. of Texas at Dallas (USA) reports that Prof. Philipos Loizou, a Professor of Electrical Engineering and pioneer in the fields of hearing aids and speech enhancement, and whose work has helped restore partial hearing to countless people, passed away on Sunday, July 22, 2012 due to cancer. He was 46, and is survived by his wife and 11 year old son.
It is with sadness that the Dept. of Electrical Engineering, Univ. of Texas at Dallas (USA) reports that Prof. Philipos Loizou, a Professor of Electrical Engineering and pioneer in the fields of hearing aids and speech enhancement, and whose work has helped restore partial hearing to countless people, passed away on Sunday, July 22, 2012 due to cancer. He was 46, and is survived by his wife and 11 year old son.