Welcome to the Summer 2013 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter! This issue of the newsletter includes 5 articles from 16 contributors, and our own staff reporters and editors. Thank you all for your contributions!
In this issue, we'd also like to welcome our new staff reporter Nancy Chen!
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions. You can submit job postings here, and reach us at speechnewseds [at] listserv (dot) ieee [dot] org.
To subscribe to the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Dilek
Hakkani-Tür, Editor-in-chief
William Campbell, Editor
Haizhou Li, Editor
Patrick Nguyen, Editor
In spoken dialog systems, the goal of dialog state tracking is to correctly identify the user's goal from the dialog history, including error-prone speech recognition results. This recent challenge task released 15K real human-computer dialogs and evaluation tools to the research community. Nine teams participated, and results will be published at SigDial.
ALIZE is a collaborative Open Source toolkit developed for speaker recognition since 2004. The latest release (3.0) includes state-of-the-art methods such as Joint Factor Analysis, i-vector modelling and Probabilistic Linear Discriminant Analysis. The C++ multi-platform implementation of ALIZE is designed to handle the increasing data quantity required for speaker and language detection and facilitate the development of state-of-the-art systems. This article reveals the motivation of the ALIZE open source platform, its architecture, the collaborative community activities, and the functionalities that are available in the 3.0 release.
Crowdsourcing has become one of the hottest topics in the artificial intelligence community in recent years. Its application to speech and language processing tasks like speech transcription has been very appealing - but what about creating corpora? Can we harness the power of crowdsourcing to improve training data sets for spoken language processing applications like dialogue systems?
This article describes the "Search and Hyperlinking" task at the MediaEval multimedia evaluation benchmark. The Search and Hyperlinking task ran for the first time in 2012 and is running again in 2013. Search and Hyperlinking consists of two sub-tasks: one which focuses on searching content relevant to a user search query from a video archive, and the other on automatic linking to related content from within the same video archive. The 2012 task used a collection of semi-professional user generated video content while the 2013 task is working with a set of TV broadcasts provided by the BBC.
Over the last decade biometric person authentication has revolutionised our approach to personal identification and has come to play an essential role in safeguarding personal, national and global security. It is well-known, however, that biometric systems can be "spoofed", i.e. intentionally fooled by impostors. Efforts to develop spoofing countermeasures are under way across the various biometrics communities (http://www.tabularasa-euproject.org/).
SLTC Newsletter, May 2013
Welcome to the second SLTC Newsletter of 2013. We will soon meet at our major event of the year: ICASSP (the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing) in Vancouver, Canada, May 26-31. Speech and language has 392 accepted papers in 38 sessions (plus a few in special sessions); so there will be lots to see and discuss, in addition to the beautiful British Columbia scenery. For the first time (as far as I can recall -- and I have attended ICASSP since its inception in 1976), we will have five plenary speakers (including the Keynote speaker Geoffrey Hinton, talking, in part, about speech recognition) and the talks will occur after lunch to encourage a large attendance. These are some of the biggest modifications to ICASSP since the move from a 3-day meeting to the current 4-day format in 1985 or the elimination of printed proceedings in 2006.
Another change this year is allowing a full fifth page for references for each paper, in addition to the usual four pages of text and figures in each article. This should permit a much wider range of literature for one to access as supplemental reading than in the past, when too often authors, running out of space, included far too few citations. Lastly, we have included, as regular ICASSP presentations, papers that have been already accepted as Letters in the IEEE Trans. Audio, Speech and Language Processing.
Our other meeting of the year will be in December 2013 for the ASRU (IEEE Automatic Speech Recognition and Understanding) workshop in Olomouc, Czech Republic (www.asru2013.org). Deadline for paper submissions is July 1st.
Let me also remind all that preparations for next year's ICASSP (May 2014) are well under way, with Special Session and Tutorial Proposals due August 30th and Regular Papers due by October 27th.
While planning is still a bit distant, we are now looking for people to help organize the next IEEE Spoken Language Technology Workshop, to be held in late 2014. Anyone who has interest in this direction, please let us know. ICASSP's are planned several years in advance (2014: Florence, 2015: Brisbane, 2016: Shanghai, 2017: New Orleans), but workshops are much smaller and with thus shorter time frames.
As our Technical Committee (SLTC) is committed to supporting the diversity of speech and language topics, as well as reaching out to new communities, I encourage all working in these fields to consider attending the upcoming Interspeech-2013 conference (http://interspeech2013.org/), which will be held in Lyon, France, Aug. 25-29. As you may know, Interspeech had its roots in two conferences - the ICSLP (Inter. Conf. of Spoken Language Processing) conference series and the Eurospeech conference series.
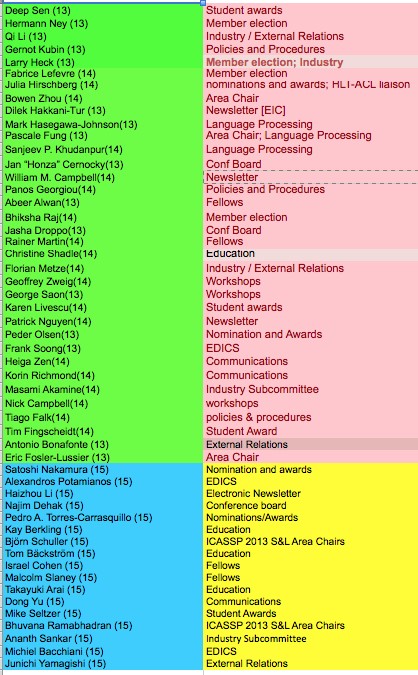
As you also likely know, our speech and language community is served, not only by the excellent conferences and workshops already mentioned, but also by the SLTC, an elected group of S+L researchers from around the world. As speech and language constitute the biggest sub-area of SPS (the IEEE Signal Processing Society), we have a large body of 54 researchers as committee members:
http://www.signalprocessingsociety.org/technical-committees/list/sl-tc/committee-members-3/
The SLTC does many activities, most notably helping greatly with the reviews of ICASSP paper submissions. The committee is renewed each summer by the election of 17-18 new members, each for a 3-year term. As this election process will begin in a few months, if you know of someone you feel would want to run for a position, or if you yourself would like to, please contact the SLTC Election subcommittee. See this site for a list of our activities, and to see the current subcommittee members: http://www.signalprocessingsociety.org/technical-committees/list/sl-tc/sub-committees/
Below is a summary (not including the Chair and Past-Chair), with the number in parenthesis being the end year.
In closing, I hope you will consider joining the SLTC this year as well as participating at both IEEE ICASSP-2013 and ASRU-2013. We look forward to meeting friends and colleagues and seeing the great scenery in beautiful Vancouver and Olomouc.
Best wishes,
Douglas O'Shaughnessy
Douglas O'Shaughnessy is the Chair of the Speech and Language Processing Technical Committee.
SLTC Newsletter, May 2013
In spoken dialog systems, the goal of dialog state tracking is to correctly identify the user's goal from the dialog history, including error-prone speech recognition results. This recent challenge task released 15K real human-computer dialogs and evaluation tools to the research community. Nine teams participated, and results will be published at SigDial.
Spoken dialog systems interact with users via natural language to help them achieve a goal. As the interaction progresses, the dialog manager maintains a representation of the state of the dialog in a process called dialog state tracking. For example, in a bus schedule information system, the dialog state might indicate the user's desired bus route, origin, and destination. Dialog state tracking is difficult because automatic speech recognition (ASR) and spoken language understanding (SLU) errors are common, and can cause the system to misunderstand the user's needs. At the same time, state tracking is crucial because the system relies on the estimated dialog state to choose actions -- for example, which bus schedule information to present to the user.
Historically, commercial systems have used hand-crafted heuristics for state tracking, selecting the SLU result with the highest confidence score, and discarding alternatives. In contrast, more recently-proposed statistical approaches continually maintain scores for many hypotheses of the dialog state (see Figure 1). By exploiting correlations between turns and information from external data sources -- such as maps, bus timetables, or models of past dialogs -- statistical approaches can overcome some SLU errors.
Numerous techniques for dialog state tracking have been proposed, including heuristic scores [1], Bayesian networks [2,3], kernel density estimators [4] , and discriminative models [5,6]. Despite this progress, direct comparisons between methods have not been possible because past studies use different domains and system components for speech recognition, spoken language understanding, dialog control, etc. Moreover, there is little agreement on how to evaluate dialog state tracking. The dialog state tracking challenge seeks to overcome these limitations by providing a common testbed and set of evaluation metrics.
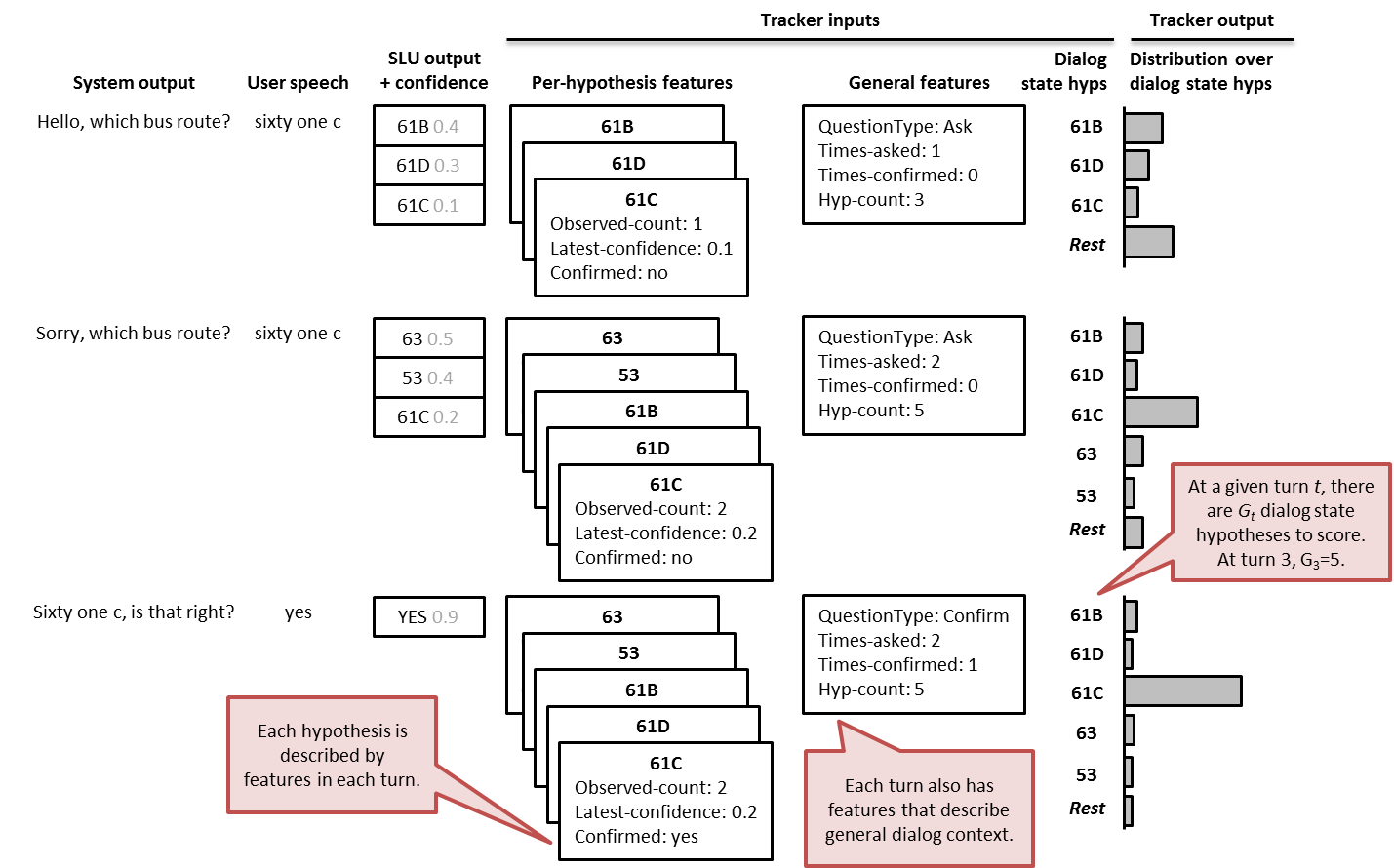
Figure 1: Overview of dialog state tracking. In this example, the dialog state contains the user's desired bus route. At each turn t, the system produces a spoken output. The user's spoken response is processed to extract a set of spoken language understanding (SLU) results, each with a local confidence score. A set of dialog state hypotheses is formed by considering all SLU results observed so far, including the current turn and all previous turns. The dialog state tracker uses features of the dialog context to produce a distribution over all hypotheses and the meta-hypothesis that none of them are correct.
The dialog state tracking challenge is a corpus-based task -- i.e., dialog state trackers are trained and tested on a static corpus of dialogs. The challenge task is to re-run state tracking on these dialogs: to take as input the runtime system logs including the SLU results and system output, and to output scores for dialog states formed from the runtime SLU results. This corpus-based design was chosen because it allows different trackers to be evaluated on the same data, and because a corpus-based task has a much lower barrier to entry for research groups than building an end-to-end dialog system.
In practice of course, a state tracker will be used in an end-to-end dialog system, and will drive action selection, thereby affecting the distribution of the dialog data the tracker experiences. In other words, it is known in advance that the distribution in the training data and the live data will be mismatched, although the nature and extent of the mis-match are not known. Hence, unlike much of supervised learning research, drawing train and test data from the same distribution in offline experiments may overstate performance. So in the DSTC, train/test mis-match was explicitly created by choosing test data to be from different dialog systems.
The DSTC uses data from the public deployment of several systems in the Spoken Dialog Challenge [7], organized by the Dialog Research Center at Carnegie Mellon University. In the Spoken Dialog Challenge, telephone calls from real bus riders were forwarded to dialog systems built by different research groups, and systems attempted to provide bus timetable information. For example, a caller might want to find out the time of the next bus leaving from Downtown to the airport.
Several research groups submitted several systems each to the SDC over a period of 3 years, resulting in a corpus of 15K dialogs. Each group used its own ASR, SLU, and dialog manager, so the characteristics of the dialogs were quite varied. This variability was exploited to test different types of mis-match between training and live conditions in the dialog state tracking challenge. For example, one of the 4 test sets examines the case where there is a large amount of well-matched data in the training set. At the other end of the spectrum, another test set examines the case where there is no well-matched data at all.
All of the dialogs were transcribed to indicate the words spoken by the caller at each turn, and labeled to indicate whether each dialog state hypothesis was correct. A dialog state hypothesis in this case is a combination of slot value assignments present in the SLU results for the current or previous turns. Some of the training data was released without labels to allow participants to explore semi-supervised methods.
For the challenge, the system logs from each group were translated into a common format. For example, the system speech "East Pittsburgh Bus Schedules. Say a bus route, like 28X, or say I'm not sure." was represented as "hello(), request(route), example(route=28x), example(route=dontknow)". The user ASR hypothesis "the next 61c from oakland to mckeesport transportation center" was represented as "inform(time.rel=next), inform(route=61c), inform(from.neighborhood=oakland), inform(to.desc="mckeesport transportation center")". In this domain there were a total of 9 slots: the bus route, date, time, and three components each for the origin and destination, corresponding to streets, neighborhoods, and points-of-interest like universities.
After each user input in each dialog, a state tracker is given the set of possible dialog states, and outputs a score for each (Figure 1). Scores were constrained to be in the range [0,1] and to sum to 1. In the evaluation, this vector of scores was compared to the correct vector, which contained 1 in the position of the correct dialog state, and 0 elsewhere.
Dialog state tracking is a relatively new task and as such the community has not agreed on standard evaluation metrics. Thus one important aspect of the challenge is an exploration of different metrics. In all, 11 performance metrics were computed. For example, 1-best accuracy measures the correctness of the top-ranked dialog state. L2 distance measures the quality of the whole probability distribution. Mean reciprocal rank measures the quality of the ranking. A number of metrics based on receiver operating characteristic (ROC) measure the discrimination of the scores.
The training data, scoring scripts, and other materials were publicly released in late December 2012. The test data (without labels) was released on 22 March 2013, and teams were given a week to run their trackers and send results back to the organizers for evaluation. To encourage participation, the organizers agreed not to identify participants in publications, and there was no requirement for participants to disclose how trackers were implemented.
9 teams entered the challenge, submitting a total of 27 trackers. Results of the challenge will be reported at SigDial 2013 (the 14th Annual Meeting of the Special Interest Group on Discourse and Dialogue), to be held in Metz, France.
In the meantime, complete information about the challenge can be found at the Dialog State Tracking Challenge Homepage, including the challenge handbook, all challenge data, and output from all trackers.
[1] H Higashinaka, M Nakano, and K Aikawa. 2003. Corpus-based discourse understanding in spoken dialogue systems. In Proc ACL, Sapporo.
[2] T Paek and E Horvitz. 2000. Conversation as action under uncertainty. In Proc UAI, Stanford, pages 455-464.
[3] JD Williams and SJ Young. 2007. Partially observable Markov decision processes for spoken dialog systems. Computer Speech and Language, 21(2):393-422.
[4] Y Ma, A Raux, D Ramachandran, and R Gupta. 2012. Landmark-based location belief tracking in a spoken dialog system. In Proc SigDial, Seoul.
[5] D Bohus and AI Rudnicky. 2006. A 'K hypotheses + other' belief updating model. In Proc AAAI Workshop on Statistical and Empirical Approaches for Spoken Dialogue Systems, Boston.
[6] A Metallinou, D Bohus, and JD Williams. 2013. Discriminative state tracking for spoken dialog systems. In Proc ACL, Sofia, Bulgaria.
[7] AW Black, S Burger, B Langner, G Parent, and M Eskenazi. 2010. Spoken dialog challenge 2010. In Proc SLT, Berkeley.
Jason D. Williams is with Microsoft Research. His interests are dialog systems and planning under uncertainty. Email: jason.williams@microsoft.com
Antoine Raux is with Honda Research Institute USA. His interests are in probabilistic approaches to state tracking for dialog systems and multimodal situated interaction. Email: araux@honda-ri.com
Deepak Ramachandran is with Nuance Communications. His interests are in machine learning methods for conversational systems. Email: deepak.ranachandran@nuance.com
Alan Black is with Carnegie Mellon University. Email: awb@cs.cmu.edu
SLTC Newsletter, May 2013
ALIZE is a collaborative Open Source toolkit developed for speaker recognition since 2004. The latest release (3.0) includes state-of-the-art methods such as Joint Factor Analysis, i-vector modelling and Probabilistic Linear Discriminant Analysis. The C++ multi-platform implementation of ALIZE is designed to handle the increasing data quantity required for speaker and language detection and facilitate the development of state-of-the-art systems. This article reveals the motivation of the ALIZE open source platform, its architecture, the collaborative community activities, and the functionalities that are available in the 3.0 release.
Speaker and language detection systems have greatly improved in the last few decades. The performance observed in the NIST Speaker Recognition and Language Recognition Evaluations demonstrates the achievements of the scientific community to make systems more accurate and robust to noise and channel nuisances. These advancements lead to two major results in terms of system development. First, automatic systems are more complex and the probabilistic model training requires a huge amount of data that can only be handled through parallel computation. Second, evaluating system performance calls for enormous numbers of trials to maintain confidence in the results and provide statistical significance when dealing with low error rates. ALIZE offers a simple solution to tackle these issues by providing a set of free efficient multi-platform tools that can be used to build a state-of-the-art speaker or language recognition system.
ALIZE has been initiated by the University of Avignon - LIA in 2004. Since then, many research institutes and companies have contributed to the project. This collaboration is facilitated by a number of tools available from the ALIZE website: (http://alize.univ-avignon.fr/)
A LinkedIn group is also available to provide a means to learn about the facilities and people involved in the field of speaker recognition.
The ALIZE project consists of a low level API (ALIZE) and a set of high level executables that form the LIA_RAL toolkit. The ensemble makes it possible to easily set up a speaker recognition system for research purposes as well as develop industry based applications.
LIA_RAL is a high level toolkit based on the low level ALIZE API. It consists of three sets of executables: LIA_SpkSeg, LIA_Utils and LIA_SpkDET. LIA_SpkSeg and LIA_Utils respectively include executables dedicated to speaker segmentation and utility programs to handle ALIZE objects while LIA_SpkDet is developed to fulfil the main functions of a state-of-the-art speaker recognition system as described in the following figure.

Figure 1: General architecture of a speaker recognition system.
LIA_RAL also includes a number of tools to manage objects in ALIZE format.
ALIZE source code is available under the LGPL license which imposes minimum restriction on the redistribution of covered softwares.
ALIZE software architecture is based on UML modelling and strict code conventions in order to facilitate collaborative development and code maintenance. The platform includes a Visual Studio � solution as well as autotools for easy compilation on UNIX-like platforms. Parallization of the code has been implemented based on the Posix standard library and some executables can be linked to Lapack for accurate and fast matrix operations. The whole toolkit has been tested under Windows, MacOs and different Linux distributions in both 32 and 64 bits architectures.
An open-source and cross-platform test suite enables ALIZE's contributors to quickly run regression tests in order to increase the reliability of future releases and to make the code easier to maintain. Test cases include a low level unit test level on the core ALIZE and the most important algorithmic classes as well as an integration test level on the high-level executable tools. Doxygen documentation is available online and can be compiled from the sources.
ALIZE 3.0 release has been partly supported by the BioSpeak project, part of the EU-funded Eurostar/Eureka program.
Subscribe to the mailing list by sending an email to: dev-alize-subscribe[AT]listes.univ-avignon.fr
The best way to contact ALIZE responsibles is to send a email to: alize[AT]univ-avignon.fr
[1] W. Campbell, D. Sturim and D. Reynolds, "Support Vector Machines Using GMM Supervectors for Speaker Verification," in IEEE Signal Processing Letters, Institute of Electrical and Numerics Engineers, 2006, 13, 308
[2] D. Matrouf, N. Scheffer, B. Fauve and J.-F. Bonastre, "A straightforward and efficient implementation of the factor analysis model for speaker verification," in Annual Conference of the International Speech Communication Association (Interspeech), pp. 1242-1245, 2007
[3] P. Kenny, G. Boulianne, P. Ouellet and P. Dumouchel, "Joint factor analysis versus eigenchannels in speaker recognition," in IEEE Transactions on Audio, Speech, and Language Processing, 15(4), pp. 1435-1447, 2007
[4] R. Auckenthaler, M. Carey, and H. Lloyd-Thomas, "Score Normalization for Text-Independent Speaker Verification System," in Digital Signal Processing, pp. 42-54, 2000
[5] N. Dehak, P. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet, "Front-End Factor Analysis for Speaker Verification," in IEEE Transactions on Audio, Speech, and Language Processing, 19, pp. 788-798, 2011
[6] N. Brummer, "The EM algorithm and minimum divergence," in Agnitio Labs Technical Report, Online: http://niko.brummer.googlepages
[7] P.-M. Bousquet, D. Matrouf, and J.-F. Bonastre, "Intersession compensation and scoring methods in the i-vectors space for speaker recognition," in Annual Conference of the International Speech Communication Association (Interspeech), pp. 485-488, 2011
[8] D. Garcia-Romero and C.Y. Espy-Wilson, "Analysis of i-vector length normalization in speaker recognition systems," in Annual Conference of the International Speech Communication Association (Interspeech), pp. 249-252, 2011
[9] P.-M. Bousquet, A. Larcher, D. Matrouf, J.-F. Bonastre and O. Plchot, "Variance-Spectra based Normalization for I-vector Standard and Probabilistic Linear Discriminant Analysis," in Odyssey Speaker and Language Recognition Workshop, 2012
[10] N. Brummer, and E. de Villiers, "The speaker partitioning problem," in Odyssey Speaker and Language Recognition Workshop, 2010
[11] S.J. Prince and J.H. Elder, "Probabilistic linear discriminant analysis for inferences about identity," in International Conference on Computer Vision, pp. 1-8, 2007
[12] Y. Jiang, K. A. Lee, Z. Tang, B. Ma, A. Larcher and H. Li, "PLDA Modeling in I-vector and Supervector Space for Speaker Verification," in Annual Conference of the International Speech Communication Association (Interspeech), pp. 1680-1683, 2012
[13] K.-P. Li and J. E. Porter, "Normalizations and selection of speech segments for speaker recognition scoring," in IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP, pp. 595-598, 1998
[14] J.-L. Gauvain and C.-H. Lee, "Maximum a posteriori estimation for multivariate gaussian mixture observations of Markov chains," in IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP, pp. 291-298, 1994
[15] C. J. Leggetter and P.C. Woodland, "Maximum likelihood linear regression for speaker adaptation of continuous density hidden markov models," in Computer Speech and Language, pp. 171-185, 1995
[16] C.-C. Chang and C.-J. Lin, "LIBSVM : a library for support vector machines," in ACM Transactions on Intelligent Systems and Technology, pp. 1-27, 2011
[17] A. Larcher, K. A. Lee, B. Ma and H. Li, "Phonetically-Constrained PLDA Modelling for Text-Dependent Speaker Verification with Multiple Short-Utterances," in IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP, 2013
Anthony Larcher is Research Staff in the Department of Human Language Technology at Institute for Infocomm Research, Singapore. His interests are mainly in speaker and language recognition.
Jean-Francois Bonastre is IEEE Senior Member. He is Professor in Computer Sciences at the University of Avignon and Vice President of the university. He is also member of the Institut Universitaire de France (Junior 2006). He has been President of International Speech Communication Association (ISCA) since September 2011.
Haizhou Li is the Head of the Department of Human Language Technology at Institute for Infocomm Research, Singapore. He is a Board Member of International Speech Communication Association.
SLTC Newsletter, May 2013
Crowdsourcing has become one of the hottest topics in the artificial intelligence community in recent years. Its application to speech and language processing tasks like speech transcription has been very appealing - but what about creating corpora? Can we harness the power of crowdsourcing to improve training data sets for spoken language processing applications like dialogue systems?
William Yang Wang, PhD student at the Language Technologies Institute at CMU, and his colleagues Dan Bohus, Ece Kamar, and Eric Horvitz at Microsoft Research believe we can. Published in the 2012 IEEE Workshop on Spoken Language Technology, they undertook a project to evaluate corpus collection using crowdsourcing techniques. More specifically, they collected sentences from crowdsourced workers with the purpose of building corpora for natural processing applications.
The benefits to collecting corpora using crowdsourcing techniques are numerous -- gathering data is cheap, quick to acquire, varied in nature. But this does not go without carrying risks such as quality control and workers that try to "game" the system. Wang's work explores whether this technique for data collection is a technique others building spoken language processing communities should consider. Wang discussed the project and where he sees this work heading with us.
SLTC: What was the motivation behind collecting corpora using crowdsourcing?
William: Well, one of the most fundamental and challenging problems in the spoken dialog research is data collection. A true story was that when I initially started my first internship at MSR, we wanted to dig directly into the problem of building a component for open-world dialog systems, but it turned out that getting an appropriate natural language data set that captures the variation in language usage associated with specific users' intentions is actually a non-trivial problem, and we also realized that many people might have encountered the same problem. Therefore, we decided to take a stab at this important problem first.
So, in the early stages, system developers typically use a deployed spoken dialog system to collect natural interaction data from users. However, even before this, data are needed for building the initial system. So this is really a chicken and egg problem. Typically what system developers do is that they create initial grammars and prompts, either manually or based on small-scale wizard-of-Oz studies. Once this is done and a system is deployed, new data is collected and models and grammars are updated. However, there are several drawbacks with this method. First of all, the initial grammars might not generalize well to real users, and poor system performance in the initial stages can subsequently bias the users' input and the collected data. Secondly, the development lifecycle can have high costs, and refining the system's performance can take a long time. Thirdly, the systems face adoption difficulties in the early stages. Well, I mean it is simply difficult to find initial users, even graduate students, to try out these systems, because of the limited functionality and lack of robustness. Moreover, every time new functionality is added to an existing system, developers have to deal with the challenge of building or acquiring new language resources and expanding grammars. We consider using crowdsourcing to acquire natural language corpora, because of its efficiencies of collecting data and solving tasks via programmatic access to human talent.
SLTC: Your crowdsourcing task is quite interesting in that it elicits a variety of responses from workers. You give workers some context and ask them to formulate natural language responses (you call this "structural natural language elicitation"). Why did you take this approach?
William: In this work, we are particularly interested in the problem of crowdsourcing language that corresponds to a given structured semantic form. This is very useful, because interactive technologies with natural language input and output must capture the variation in language usage associated with specific users' intentions. For example, data-driven spoken language understanding systems rely on corpora of natural language utterances and their mapping to the corresponding semantic forms. Similarly, data-driven approaches to natural language generation use corpora that map semantic templates to multiple lexical realizations of that template. Multilingual processing tasks such as machine translation rely on the availability of target language sentences in a parallel corpus that capture multiple valid translations of a given sentence in the source language. While our work shares similarities to previous work in paraphrase generation, they only seek mappings between surface-level realizations of language without knowledge of the underlying structure of the semantics. In contrast, we focus on capturing the mapping from the structured semantic forms to lexical forms. As far as we know, this is probably the first attempt to study the use of crowdsourcing to address this structured natural language elicitation problem.
SLTC: What were the primary methods you chose to build natural language corpora? Which method did you expect to perform best?
William: We investigated three methods. In the sentence-based method, we present a corresponding natural language sentence of a given semantic, e.g. "Find a Seattle restaurant that serves Chinese food." for the frame of FindRestaurant(City=Seattle; Cuisine=Chinese). In the scenario-based method we adopt a story-telling scheme that presents multiple sentences that form a scenario with a specific goal, e.g. "The goal is to find a restaurant. The city is Seattle. You want to have Chinese food." For the list-based method, we present a specific goal, and a set of items corresponding to the slots and values in the form of a list. For instance: Goal: Find restaurant, City: Seattle, Cuisine type: Chinese. Then for each method, we ask the crowd: "What would you say this in your own words?" While in general it is very challenging to evaluate each method with a limited number of empirical experiments, we observed that all these methods provided us accurate, natural, and relatively diverse language from the crowd. I would recommend the list-based method, simply because the seed creation process for list method requires minimum effort. In addition, the crowd workers spent less time understanding the task, because a list is typically shorter than a sentence or a paragraph.
SLTC: How did you measure performance of the crowdsourced workers? Any good tips for quality control for those working on crowdsourcing projects?
William: This is an excellent question. Actually, our task is quite different from traditional consensus-based crowdsourcing tasks, so accuracy is not the sole measure. For example, in speech transcription, as long as the crowd workers provide you with the correct transcript, you do not care about how many people have worked on your task. However, in our problem, it is rather different, because in addition to the semantic correctness, we also require the naturalness and the variety of the crowdsourced language. This essentially makes our task a multiobjective optimization problem in crowdsourcing. What made this evaluation more difficult is that there is no reference on the "true" distribution of natural language, so it is not easy to perform automatic real-time validation to filter out the low quality responses from sloppy workers. However, we are lucky because we used Microsoft's Universal Human Relevance System (UHRS), which is a novel vendor-based crowdsourcing platform. UHRS provides relatively high-quality results from full-time workers, and the cost is similar to that of Amazon's Mechanical Turk. In general, we find that it is essential to use repetition to encourage language variations from the crowd, and it is important to distribute the tasks in batches and launch them in different days. This is useful, because we want to avoid the scenarios where the majority of the tasks are performed by a small number of workers, which could bias the language collection. It might also be useful to remind the crowd workers right before the submission button that they are being paid, and they need to provide reasonable responses to avoid being blocked as spammers.
SLTC: What were the greatest challenges?
William: Crowdsourcing natural language dataset is still a relatively new research topic. While language technologies researchers have studied crowdsourcing methods for speech transcription, system evaluation, read speech acquisition, search relevance, and translation, most of them belong to consensus tasks. However, a major challenge in our work is that our task requires a certain degree of creativity, in the sense that we need the crowd to create their own response that can be mapped to the given semantic form. This further brings up two questions: (1) how do we optimize crowdsourcing to encourage variations in the responses, while maintaining the naturalness and semantic correctness at the same time? (2) Since there is no ground truth, how do we evaluate the quality of collected natural language corpora? Our analysis suggests that the crowd can perform the task efficiently and with high accuracy, and that the proposed methods are capable of eliciting some of the natural patterns in language.
SLTC: What were the lessons you learned from this study?
William: As I mentioned before, crowdsourcing methods have focused largely on building consensus and accuracy (e.g. transcription). In language elicitation, the objective function is more complex; beyond accuracy (in this case semantic accuracy), we seek to elicit the natural distribution of language usage across a population of users. As such, task design and crowdsourcing controls on the worker population are important. We learned an important lesson in our first experiment: allowing the same worker to address multiple instances of the same task can lead to a lack of diversity. In the second experiment, using crowdsourcing with more controls enabled us to engage a wider population. In principle, engaging a wide population should lead to the construction of a corpus that better captures the natural distribution of language patterns, than when the corpus is authored by a single person, whether that is a crowd worker or a system designer. We seek in future study, a deeper understanding of the tradeoffs between providing enough tasks to attract workers and maintaining engagement, balancing workloads, and developing and refining these controls in a crowdsourcing platform.
Another lesson is the challenge of performing method comparisons based on data collected via crowdsourcing. As important variables (e.g. maximum number of tasks per worker, at which time of the day different tasks will be performed, etc.) cannot be controlled, it is generally challenging to ensure a balanced design for controlled experiments. We believe that repeated experiments and, ultimately, end-to-end evaluations are required to draw robust conclusions. Future work is needed to investigate the performance of deployed spoken dialog systems with language corpora elicited with different methods.
SLTC: What kind of impact do you foresee this work having on crowdsourcing?
William: Successful implementations of our methods may enable a number of natural language processing tasks. For instance, for data-driven natural language generation, the methods are sufficient to collect the required data, as the set of semantic forms of interest are known to the system developer. For other tasks, such as developing a spoken dialog system, the distribution of instantiated semantic forms, which is required as an input for our methods, is an important aspect of the corpus that must be collected. This distribution over semantic forms may still be authored, or may be collected by transcribing and annotating interactions of a dialog system with real users. We also foresee the benefits of applying our methods to other areas such as semantic machine translation, semantic image annotation, and semantic parsing.
SLTC: What do you feel are the logical next steps for this line of work?
William: A key direction for fielding more robust automated interactive systems is endowing them with the ability to detect when they do not know or understand some aspects of the world--versus misidentifying things unknown as known and then performing poorly. So following this line of work, we are interested in using the crowdsourced data to build open-world dialogue systems that can detect unknown classes of input, especially in the dynamic, complex, and unconstrained environments. We also plan to study the life-long simulations of the open-world dialogue systems.
SLTC: Finally, I know that you did this work while on an internship at Microsoft Research. How would you describe that experience?
William: There is no doubt that MSR is one of the best places for internships. Mentors and collaborators here at MSR are very easy to talk to, and they are very helpful on any questions that you might have. They respect you as a co-worker, listen to your ideas, and actively discuss research topics with you. Also, I had so much fun with other interns in outdoor activities during the Summer -- you will just love this experience.
We look forward to hearing more about crowdsourcing data collection in future work!
If you have comments, corrections, or additions to this article, please contact the author: Matthew Marge, mrma...@cs.cmu.edu.
Matthew Marge is a doctoral student in the Language Technologies Institute at Carnegie Mellon University. His interests are spoken dialogue systems, human-robot interaction, and crowdsourcing for natural language research.
SLTC Newsletter, May 2013
This article describes the "Search and Hyperlinking" task at the MediaEval multimedia evaluation benchmark [1]. The Search and Hyperlinking task ran for the first time in 2012 and is running again in 2013. Search and Hyperlinking consists of two sub-tasks: one which focuses on searching content relevant to a user search query from a video archive, and the other on automatic linking to related content from within the same video archive. The 2012 task used a collection of semi-professional user generated video content while the 2013 task is working with a set of TV broadcasts provided by the BBC.
The increasing amount of digital multimedia content available is inspiring potential new types of user experience with the data. The Search and Hyperlinking task at MediaEval envisions a scenario of a user searching for a known segment from within a video collection. On occasion the user may find that the information in the segment may not be sufficient to address their information need or they may wish to watch other related video segments. The Search and Hyperlinking task consists of two sub-tasks designed to investigate both elements of this activity: search for a known relevant segment and hyperlinking to related video segments from the target video segment.
The Search and Hyperlinking task was introduced at MediaEval 2012 [2], and built on the earlier Rich Speech Retrieval task at MediaEval 2011 [3] and the Linking Task at VideoCLEF 2009 [4] . The MediaEval 2012 Search and Hyperlinking task used the blip10000 collection of semi-professional user generated videos crawled from the Internet video sharing platform Blip.tv [5]. This collection contains video and the user generated textual metadata available for each video. Participants were also provided with: two automatic speech recognition (ASR) transcripts (containing 1-best output, lattices, and confusion networks), automatically identified video shot boundary points with extracted key frames for each shot, and automatic face and visual concept detection results. The dataset contained ca. 14,700 videos, or episodes, comprising a total of ca. 3,200 hours of data. These episodes were separated into development and test sets, containing ca. 5,200 videos (having a runtime of 1,100 hours) and ca. 9,500 videos (having a runtime of 2,100 hours), respectively. The episodes were taken from 2,349 different shows.
Audio was extracted from all videos using a combination of the ffmpeg and sox software (sample rate = 16,000Hz, number of channels = 1). Two sets of ASR transcripts were provided by LIMSI/Vocapia Research and LIUM Research.
The LIMSI/Vocapia system [6] used a language identification detector (LID) to automatically identify the language spoken in the whole video along with a language confidence score (lconf), however the LID results were not manually checked. Each file with a language identification score equal or greater than 0.8 was transcribed in the detected language. The remaining files were transcribed twice, with the detected language as well as with the English system. The average word confidence scores (tconf) were compared. The transcription with the higher score was chosen. For files in languages that do not have a transcription system, no transcripts were provided. This resulted in 5,238 and 7,216 files for development and test sets respectively.
The LIUM system [7] was based on the CMU Sphinx project, and was developed to participate in the evaluation campaign of the International Workshop on Spoken Language Translation 2011. LIUM provided an English transcription for each audio file successfully processed, 5,084 from the development set and 6,879 from the test set. These results consist of: (i) one-best hypotheses in NIST CTM format, (ii) word lattices in SLF (HTK) format, following a 4-gram topology, and (iii) confusion networks, in an ATT FSM-like format.
For each episode, the shot boundaries were created by TU Berlin [5]. For each shot segment a keyframe was extracted from the middle of each shot. In total, the dataset included approximately 420,000 shots/keyframes with an average shot length of about 30 seconds. Visual concept-based descriptors were based on a list of 589 concepts selected by extracting keywords from the metadata of videos. The presence of concepts in the video was determined automatically using the Visor on-the-fly video detector developed at the University of Oxford [8]. The presence of faces in videos can also be helpful information in video search. To encourage participants to use this information we provided face detection results generated by INRIA [9].
Participants were provided with a set of queries for a known-item search task with 30 text queries each for the development and test sets. The queries were collected via crowdsourcing using the Amazon MTurk platform [10]. Participants were required to make one submission for the 1-best output of each ASR transcript version. Additionally, participants could deliver up to two other runs for each ASR transcript version.
Three metrics were used to evaluate task results: mean reciprocal rank (MRR), mean generalized average precision (mGAP) and mean average segment precision (MASP). MRR assesses the ranking of the relevant units. mGAP [11] awards runs that not only find the relevant items earlier in the ranked output list, but also are closer to the starting point of the relevant content. MASP [12] takes into account the ranking of the results and the length of both relevant and irrelevant segments that need to be listened to before reaching the relevant item.
The Linking sub-task used the known-items search targets as the anchor videos from which links to other videos should be formed. Participants were required to return a ranked list of video segments which were potentially relevant to the information in this video segment (independent of the initial textual query). Additionally they were allowed to use their own output of the Search subtask as the video anchors for the Linking subtask. The top 10 ranked videos for each submission were evaluated for relevance to the anchor video again using the MTurk platform. The collection relevance data was used to calculate the mean average precision (MAP) of each ranked set of results.
Participants in the Search task explored a range of content segmentation techniques to form documents for search and compared the behaviour of the alternative transcripts. Contributions to the Linking task examined alternative combinations of textual and visual features which identified generally different sets of potentially relevant links to related video. The task participants carried out a detailed comparative evaluation of their approaches to these tasks which is reported in [13].
The MediaEval 2013 Search and Hyperlinking task is continuing to explore these topics, but this year is using a collection of videos of TV broadcasts provided by the BBC. Further information is available from [1] or contact Maria Eskevich, registration is open until May 31st 2013.
[1] http://www.multimediaeval.org
[2] M.Eskevich, G.J.F.Jones, S.Chen, R.Aly, R.Ordelman and M.Larson, Search and Hyperlinking Task at MediaEval 2012, Proceedings of the MediaEval 2012 Workshop, Pisa, Italy, 2012.
[3] M.Larson, M.Eskevich, R.Ordelman, C.Kofler, S.Schmiedeke and G.J.F.Jones, Overview of MediaEval 2011 Rich Speech Retrieval Task and Genre Tagging Task, Proceedings of the MediaEval 2011 Workshop, Pisa, Italy, 2011.
[4] M.Larson, E.Newman and G.J.F.Jones, Overview of VideoCLEF 2009: New perspectives on speech-based multimedia content enrichment, Proceedings of. CLEF 2009: Workshop on Cross-Language Information Retrieval and Evaluation, Corfu, Greece, 2009.
[5] S.Schmiedeke, P. Xu, I. Ferran�, M. Eskevich, C. Kofler, M. Larson, Y. Est�ve, L. Lamel, G.J.F. Jones and T. Sikora, Blip10000: A social Video Dataset containing SPUG Content for Tagging and Retrieval, In Proceedings of ACM MMSys 2013, Oslo, Norway, 2013.
[6] L.Lamel and J.-L.Gauvain. Speech processing for audio indexing. In Advances in Natural Language Processing (LNCS 5221). Springer, 2008.
[7] A.Rousseau, F.Bougares, P.Del�glise, H.Schwenk, and Y.Estev. LIUM's systems for the IWSLT 2011 Speech Translation Tasks. In Proceedings of IWSLT 2011, San Francisco, USA, 2011.
[8] K.Chatfield, V.Lempitsky, A.Vedaldi, and A.Zisserman. The devil is in the details: an evaluation of recent feature encoding method. In Proceedings of BMVC 2011, 2011.
[9] R.G. Cinbis, J.Verbeek, and C.Schmid. Unsupervised Metric Learning for Face Identification in TV Video. In Proceedings of ICCV 2011, Barcelona, Spain, 2011.
[10] http://www.mturk.com/.
[11] P.Pecina, P.Hoffmannova, G.J.F. Jones, Y.Zhang, and D.W.Oard. Overview of the CLEF 2007 Cross-language speech retrieval track. In Proceedings of CLEF 2007, pages 674-686. Springer, 2007.
[12] M.Eskevich, W.Magdy, and G.J.F. Jones. New metrics for meaningful evaluation of informally structured speech retrieval. In Proceedings of ECIR 2012, pages 170-181, 2012.
[13] M.Eskevich, G.J.F.Jones., R.Aly, R.J.F. Ordelman, S.Chen, D.Nadeem, C.Guinaudeau, G.Gravier, P.Sebillot, T.De Nies, P.Debevere, R.van de Walle, P.Galuscakova, P.Pecina and M.Larson, Information Seeking through Search and Hyperlinking, In Proceedings of ACM ICMR 2013, Dallas, Texas, USA, 2013.
Gareth J. F. Jones, Maria Eskevich, Robin Aly, Roeland Ordelman are the organizers of the MediaEval Search & Hyperlinking task. Contact email: meskevich@computing.dcu.ie.
SLTC Newsletter, May 2013
Over the last decade biometric person authentication has revolutionised our approach to personal identification and has come to play an essential role in safeguarding personal, national and global security. It is well-known, however, that biometric systems can be "spoofed", i.e. intentionally fooled by impostors [1].
Efforts to develop spoofing countermeasures are under way across the various biometrics communities (http://www.tabularasa-euproject.org/). However, research in automatic speaker verification (ASV) is far less advanced in this aspect in comparison to physical biometrics such as fingerprint, face and iris recognition. Given that ASV is often applied as a low-cost, remote authentication technique over uncontrolled communications channels without human supervision or face-to-face contact, speech is arguably more prone to malicious interference or manipulation in comparison to other biometric traits. Indeed, it has become clear that ASV systems can be spoofed through impersonation [2], replay attacks [3], voice conversion [4, 5] and speaker-adapted speech synthesis [6], though the bulk of the wider literature involves only text-independent ASV. While the research community has focused most of their efforts on tackling session, channel and environment variation, even the most sophisticated of today's recognizers can be circumvented. When subjected to spoofing it is not uncommon that ASV performance falls below that expected by chance.
Previous efforts to develop countermeasures for ASV generally utilize prior knowledge of specific spoofing attacks. This approach stems from the lack of standard datasets which necessitates the collection or generation of purpose-made, non-standard datasets using specific spoofing algorithms. Familiarity with particular attacks and the availability of large quantities of example data then influence countermeasure development since telltale indicators of spoofing can be identified with relative ease. For instance, synthetic speech generated according to the specific algorithm reported in [7] provokes lower variation in frame-level log-likelihood values than natural speech. Observations of such characteristics are thus readily utilised to distinguish between genuine accesses and spoofing attacks generated from the same or similar approach to speech synthesis; other approaches may overcome this countermeasure. Based on the difficulty in reliable prosody modelling in both unit selection and statistical parametric speech synthesis, other researchers have explored the use of F0 statistics to detect spoofing attacks [8, 9], however, even these countermeasures may be overcome by alternative spoofing attacks. Vulnerabilities to voice conversion have also attracted considerable interest over recent years. One approach to detect voice conversion proposed in [10] exploits the absence of natural speech phase in voices converted according to a specific approach based on joint-density Gaussian mixture models. This countermeasure will likely be overcome by the approach to voice conversion proposed in [4] which retains real speech phase, but which has been shown to reduce the short-term variability of generated speech [11]. Once again this countermeasure will not be universally reliable in detecting different forms of voice conversion, nor different forms of spoofing.
The above work demonstrates the vulnerability of ASV to what are undeniably high-cost, high-technology attacks but also the strong potential for spoofing countermeasures. However, the use of prior knowledge is clearly unrepresentative of the practical scenario and detrimental to the pursuit of general countermeasures with potential to detect unforeseen spoofing attacks whose nature can never be known. There is thus a need to develop new countermeasures which generalise to previously unseen spoofing techniques. Unfortunately, the lack of standard corpora, protocols and metrics present a fundamental barrier to the study of spoofing and generalised anti-spoofing countermeasures. While most state-of-the-art ASV systems have been developed using standard NIST speaker recognition evaluation (SRE) corpora and associated tools, there is no equivalent, publicly available corpus of spoofed speech signals and no standard evaluation or assessment procedures to encourage the development of countermeasures and their integration with ASV systems. Further work is also needed to analyse spoofing through risk assessment and to consider more practical use cases including text-dependent ASV.
The authors of this newsletter have organised a special session for the Interspeech 2013 conference on Spoofing and Countermeasures for Automatic Speaker Verification. It is intended to stimulate the discussion and collaboration needed to organize the collection of standard datasets of both licit and spoofed speaker verification transactions and the definition of standard metrics and evaluation protocols for future research in spoofing and generalised countermeasures. Ultimately, this initiative will require the expertise of different speech and language processing communities, e.g. those in voice conversion and speech synthesis, in addition to ASV.
[1] N. K. Ratha, J. H. Connell, and R. M. Bolle, "Enhancing security and privacy in biometrics-based authentication systems," IBM Systems Journal, vol. 40, no. 3, pp. 614-634, 2001.
[2] Y. Lau, D. Tran, and M. Wagner, "Testing voice mimicry with the yoho speaker verification corpus," in Knowledge-Based Intelligent Information and Engineering Systems. Springer, 2005, pp. 907-907.
[3] J. Villalba and E. Lleida, "Preventing replay attacks on speaker verification systems," in Security Technology (ICCST), 2011 IEEE International Carnahan Conference on. IEEE, 2011, pp. 1-8.
[4] D. Matrouf, J.-F. Bonastre, and C. Fredouille, "Effect of speech transformation on impostor acceptance," in Acoustics, Speech and Signal Processing, 2006. ICASSP 2006 Proceedings. 2006 IEEE International Conference on, vol. 1. IEEE, 2006, pp. I-I.
[5] T. Kinnunen, Z.-Z. Wu, K. A. Lee, F. Sedlak, E. S. Chng, and H. Li, "Vulnerability of speaker verification systems against voice conversion spoofing attacks: The case of telephone speech," in Acoustics, Speech and Signal Processing (ICASSP), 2012 IEEE International Conference on. IEEE, 2012, pp. 4401-4404.
[6] P. L. De Leon, M. Pucher, and J. Yamagishi, "Evaluation of the vulnerability of speaker verification to synthetic speech," in Proc. IEEE Speaker and Language Recognition Workshop (Odyssey), 2010, pp. 151-158.
[7] T. Satoh, T. Masuko, T. Kobayashi, and K. Tokuda, "A robust speaker verification system against imposture using an HMM-based speech synthesis system," in Proc. Eurospeech, 2001.
[8] A. Ogihara, H. Unno, and A. Shiozakai, "Discrimination method of synthetic speech using pitch frequency against synthetic speech falsification," IEICE transactions on fundamentals of electronics, communications and computer sciences, vol. 88, no. 1, pp. 280-286, jan 2005.
[9] P. L. De Leon, B. Stewart, and J. Yamagishi, "Synthetic speech discrimination using pitch pattern statistics derived from image analysis," in Proc. Interspeech, Portland, Oregon, USA, Sep. 2012.
[10] Z. Wu, T. Kinnunen, E. S. Chng, H. Li, and E. Ambikairajah, "A study on spoofing attack in state-of-the-art speaker verification: the telephone speech case," in Signal & Information Processing Association Annual Summit and Conference (APSIPA ASC), 2012 Asia-Pacific. IEEE, 2012, pp. 1-5.
[11] F. Alegre, A. Amehraye, and N. Evans, "Spoofing countermeasures to protect automatic speker verification from voice conversion," in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2013.
Nicholas Evans is with EURECOM, Sophia Antipolis, France. His interests include speaker diarization, speaker recognition and multimodal biometrics. Email: evans@eurecom.fr.
Junichi Yamagishi is with National Institute of Informatics, Japan and with University of Edinburgh, UK. His interests include speaker synthesis and speaker adaptation. Email: jyamagis@inf.ed.ac.uk
Tomi H. Kinnunen is with University of Eastern Finland (UEF). His current research interest include speaker verification, robust feature extraction and voice conversion. Email: tkinnu@cs.uef.fi.