Welcome to the Winter 2010 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter.
In this issue we are pleased to provide another installment of brief articles representing a diversity of views and backgrounds. This issue includes articles from 15 guest contributors, and our own 6 staff reporters. Also, in this issue, we welcome Tara N. Sainath, at IBM T.J. Watson Research Center, who joins us as a staff reporter.
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions. You can reach us at speechnewseds [at] listserv (dot) ieee [dot] org.
Finally, to subscribe the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Jason Williams, Editor-in-chief
Pino Di Fabbrizio, Editor
Chuck Wooters, Editor
News from our TC: election of new members and a vice-chair, and ICASSP review results.
Two researchers from the SLTC community have won IEEE awards: Shrikanth (Shri) Narayanan for Distinguished Lecturer (2010-2011), and Isabel M. Trancoso for Meritorious Service Award.
The IEEE Signal Processing Society, our parent organization, also produces a monthly newsletter, "Inside Signal Processing".
This article provides a quick introduction about speech processing into the cloud to support the scalability challenges of speech-enabled applications running on mobile devices.
This article gives an overview of the main tasks of meeting understanding: Meeting summarization, Action item detection, and Decision detection.
As part of a restructuring program, King's College London may eliminate several positions held by well-known researchers..
Setting up a new research group presents special challenges and opportunities. This article describes the work of the Interaction Lab, and some of the main issues we considered when setting up this new research facility.
The 2009 Text Analysis Conference (TAC) was held at NIST in Gaithersburg, Maryland as a two day event from 16-17 November, 2009. TAC covers a variety of shared tasks organized every year. The participant systems are evaluated at NIST and the workshop brings together researchers and participants to share their experiences and ideas. This article provides an overview of this year's tasks.
Advances in brain-machine interfaces are now allowing a paraplegic patient to control a real-time speech synthesizer using a BMI that reads the neural signals that relate to the production of speech.
The ISCA Student Advisory Committee (ISCA-SAC) was established in 2005 by the International Speech Communication Association (ISCA) to organize and coordinate student-driven projects. We were especially active in 2007 and 2008, we were pleased to continue our efforts in 2009, and we look forward to 2010.
The IEEE Workshop on Automatic Speech Recognition and Understanding, held in December 2009 in Merano Italy, published 96 papers and attracted 180 international attendees.
Island-driven search is an alternative method to better deal with noisy and unintelligible speech. In this article, we discuss past research in island-driven search and propose some future research directions.
The eNTERFACE workshops are the largest activity of the SIMILAR European Network of Excellence on multimodal interfaces. Their aim is to gather a team of leading professionals in multimodal man-machine interfaces together with students in one place, to work on a pre-specified list of challenges, for 4 complete weeks.
Second Life (SL) is a virtual social environment with over 11 million registered users. This article describes some of the projects that use Second Life environment for research.
SLTC Newsletter, February 2010
Since this is the first newsletter of 2010, I would like to start by wishing everyone in our speech and language community a happy and a prosperous New Year.
As always at this time of year, it is my pleasure to welcome new members to our Technical Committee and to thank those at the end of their term. The new members coming in are: Tom Quatieri, Bastiaan Kleijn, Bhuvana Ramabhadran, Carol Espy-Wilson, Dirk Van Compernolle, Douglas Reynolds, Hong-Kwang Jeff Kuo, Les Atlas, Olivier Pietquin, Simon King, David Suendermann, Kate Knill, Olov Engwall, Martin Russell, Junlan Feng, Seiichi Nakagawa, and Takayuki Arai. And those leaving are: Alistair D. Conkie, Yuqing Gao, Jasha Droppo, Murat Saraclar, Philipos Loizou, Stephen Cox, Tomoki Toda, Douglas O'Shaughnessy, Andrej Ljolje, Kay Berkling, Kuldip K. Paliwal, Roberto Pieraccini, and Thomas Hain. I would like to thank all of the outgoing TC members for the support that they have provided the Speech and Language community over the last 3 years.
The end of 2009 also marked the end of Alex Acero's very successful tenure as VP Technical Directions. One of the last tasks that Alex set himself was to reform the SPS bylaws such that all Technical Committees follow a uniform set of policies and procedures. Thankfully, our TC's existing bylaws are very similar to the new rules so we will not need to make any significant changes. One exception, however, is that the new rules require TC's to have a vice-Chair who is elected for a 2 year term and then automatically takes over as Chair for a second 2 year term. Anticipating this change, the Speech and Language TC has elected John Hansen as its vice-Chair. As a transitional arrangement, John will serve just 1 year as vice-Chair before taking over from me in January 2011. We will therefore need to elect another vice-Chair at the end of this year to work alongside John.
As well as being vice-Chair of our TC, John is also Technical Program Chair of ICASSP 2010 to be held in Dallas in March. In my last newsletter article, I described the imminent ICASSP 2010 review process. In the event, we had a total of 620 papers submitted. 510 were in speech and of these we accepted 249; the remaining 110 submissions were in the language area and we accepted 59 of these. Hence, the overall acceptance rate in the Speech and Language area was 50%. Of the 620 papers submitted, 600 received four reviews and the remainder had 3 reviews. All papers received a meta-review from a TC member to minimise the effects of reviewer inconsistency or disagreement. This puts quite a load on TC members who have to respond very quickly and I would like to take this opportunity to thank them for their help, especially those who were able to conduct last-minute reviews on very short notice! Whilst no reviewing system can be perfect, I believe that our TC has done as much as could reasonably be done to ensure that every paper submitted was assessed fairly. The overall process was managed by the four area chairs: Pascale Fung, TJ Hazen, Thomas Hain and Brian Kingsbury. They did a tremendous job and we owe them a great vote of thanks.
So best wishes again for the New Year and see you all at ICASSP 2010!
Steve Young
Steve Young is Chair, Speech and Language Technical Committee.
SLTC Newsletter, February 2010
Each year the Speech and Language Processing Technical Committee (SLTC) submits nominations to the IEEE Awards Board for Distinguished Lecture (DL) positions, numerous society awards (e.g., technical achievement, meritorious service, etc) and best-paper awards. Nominations for the DL were solicited by the Awards SLTC Subcommittee in June 2009 and nominations for the IEEE awards were solicited in August 2009. After receiving all nominations, a poll was administered from the Survey Monkey web site. The SLTC members were asked to rank each candidate for every award. Voters with apparent conflict of interest were asked to abstain and select the “abstain” button on the web site. Over 95% of SLTC members had cast their votes. The names of the top candidates for each award were submitted to the IEEE Awards Board, who in turn selected the following:
Shrikanth (Shri) Narayanan for Distinguished Lecturer (2010-2011) – Dr. Narayanan’ is currently the Andrew J. Viterbi Professor of Engineering at the University of Southern California. Prof. Narayanan’s contributions are in the broad area of human-centric multimodal signal processing and applications spanning speech, audio, image and bio signal processing. His work uniquely bridges science and engineering through innovative interdisciplinary approaches and his contributions are at the forefront of the field integrating fundamental and applied problems in human communication. The DLs are expected to deliver “a message of importance to the technical community”, and the suggested lecture topics put forward in the nomination included: (1) Human-like speech and audio Processing, (2) Expressive Human Communication: Automatic Multimodal Recognition and Synthesis of Emotions, (3) Speech-to-Speech Translation: Advances, Open Challenges and Opportunities, and (4) Speaking and Singing Production: Data, Models and Applications.
Isabel M. Trancoso for Meritorious Service Award (shared with Arye Nehorai) – Dr. Trancoso is currently a Professor at Instituto Superior Técnico (IST) in Lisbon, Portugal. This award honors contributions to the Signal Processing Society. Some of Dr. Trancoso’s contributions include her long and extensive service in several European associations affiliated with speech and language processing (e.g., ESCA) as well as her heavy involvement in numerous IEEE-sponsored conferences/workshops and editorships. Among others, she served as Associate Editor of Speech Communication (1993-2002) and she launched the electronic journal European Student Journal of Language and Speech, with the support of ELSNET and the associations ESCA and EACL. She served as Editor-in-Chief of that journal during the first 3 years. She served as Editor-in-Chief of the IEEE Transactions on Audio and Speech Processing (2003-2005) and Editor of the IEEE Signal Processing Magazine (2006-2008). She was elected to the ESCA (European Speech Communication Association) Board in 1993, and was re-elected in 1997 for her second 4-year term. She was elected member-at-large of the Board of Governors of the Signal Processing Society (2006-2008) and lastly served as a member of the SLTC. In summary, her contributions to the Signal Processing Society and the field of spoken language recognition are immense spanning two continents.
Let us extend our congratulations to Prof. Narayanan and Dr. Trancoso for their accomplishments and contributions to the Signal Processing Society.
Philip Loizou was the Chair of the SLTC Awards Subcommittee which also included Frank Soong and Hideki Kawahara.
SLTC Newsletter, February 2010
The following message has been reproduced from an IEEE Signal Processing Society announcement from José M.F. Moura, SPS Nominations and Appointments Committee.
In accordance with the Bylaws of the IEEE Signal Processing Society, the membership will elect, by direct ballot, THREE Members-at-Large to the Board of Governors (BoG) for three-year terms commencing 1 January 2011 and ending 31 December 2013, as well as ONE Regional Director-at-Large for each of the corresponding regions: Regions 1-6 (US), Regions 7 and 9 (Canada and Latin America), Region 8 (Europe/Middle East/Africa) and Region 10 (Asia/Pacific Rim) for two-year terms commencing 1 January 2011 and ending 31 December 2012. Nominations are requested no later than 19 MARCH 2010.
Regional Directors-at-Large are elected locally by members of the corresponding region. They serve as non-voting members of the Board of Governors and voting members of the Membership Board. They promote and foster local activities (such as conferences, meetings, social networking) and encourage new chapter development; represent their regions to the core of SPS; offer advices to improve membership relations, recruiting and service to their regions; guide and work with their corresponding chapters to serve their members; and assist the Vice President-Awards in conducting chapter reviews.
Board of Governors Members-at-Large are directly elected by the Society's membership to represent the member viewpoint in Board decision-making. They typically review, discuss, and act upon a wide range of items affecting the actions, activities and health of the Society.
Please do not hesitate to nominate yourself, particularly if you have not yet served on the Board of Governors.
The formal procedures established for this year’s election are:
I look forward to receiving your nominations for Regional Directors-at-Large and Members-at-Large via e-mail no later than 19 MARCH 2010. Please send them to Theresa Argiropoulos (t.argiropoulos@ieee.org). However, if you first wish to communicate with me privately before making a nomination, you can reach me at moura@ece.cmu.edu.
In making your nomination, please provide the following information:
Name of Candidate:
Candidate Contact Information: (address, phone, fax, e-mail)
Brief Background of the Individual: (no more than 100 words, please)
Information about Current SP, IEEE, or Other Society
Volunteer Activities.
Thank you for participating in the Society’s nominations process. Your nominations are requested no later than 19 MARCH 2010.
Jason Williams is Principal Member of Technical Staff at AT&T Labs Research. His interests are dialog systems and planning under uncertainty. Email: jdw@research.att.com
SLTC Newsletter, February 2010
The following message has been reproduced from an IEEE Signal Processing Society announcement from Michael D. Zoltowski, SPS Vice President-Awards and Memberships.
Michael D. Zoltowski, SPS Vice President-Awards and Memberships, invites nominations for the positions of Director-Industrial Relations and Director-Membership Services. The term for each Director position will be three years (1 January 2011-31 December 2013).
The Director-Membership Services is responsible for identifying value/benefit/services to members, as well as recommending policy/mechanism for recruiting members. The Director is a non-voting, ex-officio member of both the Conference and Publications Boards. The Director-Membership Services also chairs the Membership Services Committee.
The Director-Industrial Relations is responsible for identifying value/benefit/services to attract/retain industrial members. The Director is a non-voting, ex-officio member of both the Conference and Publications Boards. The Director-Industrial also chairs the Industrial Relations Committee.
Nominations should be submitted to Michael D. Zoltowski, SPS Vice President-Awards and Memberships, via mikedz@ecn.purdue.edu. When making your nomination, please provide the following information:
Name of candidate
Contact information
Brief background
Information about current SP, IEEE, or Other Society,
Other volunteer activities.
Nominations must be received no later than 15 February 2010.
Jason Williams is Principal Member of Technical Staff at AT&T Labs Research. His interests are dialog systems and planning under uncertainty. Email: jdw@research.att.com
SLTC Newsletter, February 2010
This article provides a quick introduction about speech processing into the cloud to support the scalability challenges of speech-enabled applications running on mobile devices.
Last October 2009 in New York City, Amazon Web Services (AWS), a division of Amazon.com, hosted an event about "AWS Cloud for the Enterprise". The venue was opened to technology and business 'stakeholders' interested in learning the latest bleeding-edge technologies in cloud computing. The auditorium was crowded with more than 200 attendees representing a broad range of enterprises from finance, entertainment, telecommunication, insurances, pharmaceutical, and more. An unusual mix of industries congregated in one place to listen to the latest news about outsourcing computational and networking resources into the cloud. At the opening remarks, Dr. Werner Vogels, chief technology officer and vice president of Amazon.com, defined cloud computing as "a style of computing where massively scalable IT-related capabilities are provided 'as-a-service' across the Internet to multiple external customers." Right after the introduction, happy customers such as Netflix, Wired Magazine, Nasdaq QMX, Sony Music, and New York Life insurance, shared their experience with the attentive audience. Then, the stage passed to a series of technical presentations pointing out security tricks, architectural configurations, and step-by-step procedures to get you started in putting enterprise applications into the AWS cloud.
What was motivating the devoted participants is a concrete and affordable new way to dispose immediately of highly available and powerful hardware on-demand, without the burden of hosting and managing the entire infrastructure needed to run your own data center. Instead of physical servers, computing resources are 'dispersed' in the internet cloud where IT-managers don't need to know where the machines are physically located, and don't have to worry about hardware maintenance. However computation resource virtualization is not new to IT companies. Before cloud computing other similar approaches such as distributed computing, software as a service (SaaS), and service-oriented architectures (SOA) exploited the concept. But only recently have companies like Amazon created the infrastructure to improve the way hardware procurement was handled and streamlined the process to bring new a service online.
The successes of cloud computing are also due to the introduction of sophisticated management and monitoring capabilities (e.g., Amazon EC2 auto-scaling), where the platform is capable of monitoring system resources, and automatically scaling those resources based on parameters such as CPU and memory utilization, or network traffic. The cloud infrastructure as a service (IaaS) enforces also a complete user separation by providing both CPU and network virtualization, i.e., not only are the processes from a given user separated from other users' processes, but also network traffic is kept separated and each running virtual image only receives and processes traffic destined for it.
Besides the Amazon EC2 product there are other examples of
commercial cloud computing infrastructures including GoGrid, SunCloud, 3tera, Eucalyptus,
and open source solutions, such as Nimbus
and Xen Hypervisor. There are also cloud platforms available, delivering a
computing platform with a complete solution stack (e.g., running native cloud
applications) to customers. Cloud platforms include for example Heroku (Ruby on Rail), Google App Engine (Java), Microsoft Azure (.Net), Rackspace Cloud (PHP),
Salesforce
(Java/C# like), and, on the open source side, GridGain (Java).
One of the biggest advantages of cloud computing is that users can convert capital
expenditures into operating expenses since there is no
hardware or software to buy, and they only pay for whatever resources are being
used. The cloud computing model in fact promotes acquiring resources on demand,
releasing them when no longer needed, and paying for them based on usage. From
the user perspective though, it's like the cloud has infinite capacity.
Scalability is then achieved by providing APIs that allow starting and stopping a new
server instance in a matter of minutes instead of weeks, as typically required
when using a traditional in-house procurement process. Beside scalability,
other important properties addressed by cloud computing are cost-effectiveness,
reliability, high availability, and security.
Cloud computing seems ideal for today's speech processing computational needs. To date, there are two major areas where this approach has been tested: in traditional speech processing applications such as IVR (Interactive Voice Response) systems and in more recently exploited web-based speech processing services or speech mashups [1][2].
IVR services typically require dedicated hardware and closed software in order to support speech in real-time, and are usually very CPU intensive. With CPU virtualization, adding and removing new processing resources can be driven by channel utilization rather than pre-allocated (and often not utilized) servers based on traffic analysis. An example of cloud-based communication approach that includes also IVR-like functionalities is Tropo.com where typical telecommunication functionalities are exposed on demand though common APIs.
The second class of services relies on network-enabled
devices such as Blackberry, iPhone and Adroid-based mobiles, capable of
accessing the Internet at broadband (e.g., 3G, WiFi) speeds and by
capturing/playing the user's speech directly over the data channel. In this
case, speech processing resources can be seen as network endpoints with a
web-based interface that can be easily replicated in the cloud model by
creating new cloud instances. Mobile services with this model are usually
created by aggregating different web services with the speech processing
component (e.g., speech mashups).
In general this class of services also applies to any device supporting HTTP,
such as desktops, laptops, netbooks, and PDAs.
Considering that Apple recently announced 3 billion worldwide Apple Store downloads and that the number of applications available for the iPhone alone passed the 140,000 mark, it is fair to expect that more and more of these applications will eventually be voice enabled. The uncertainty of the success of such applications and the unpredictability of calculating the traffic hitting the speech processing engine, makes this scenario an ideal candidate for putting the speech engine into the cloud, thus enabling the service provider to easily scale the processing power up or down according to traffic demand, and without the need to buy and manage dedicated hardware in advance.
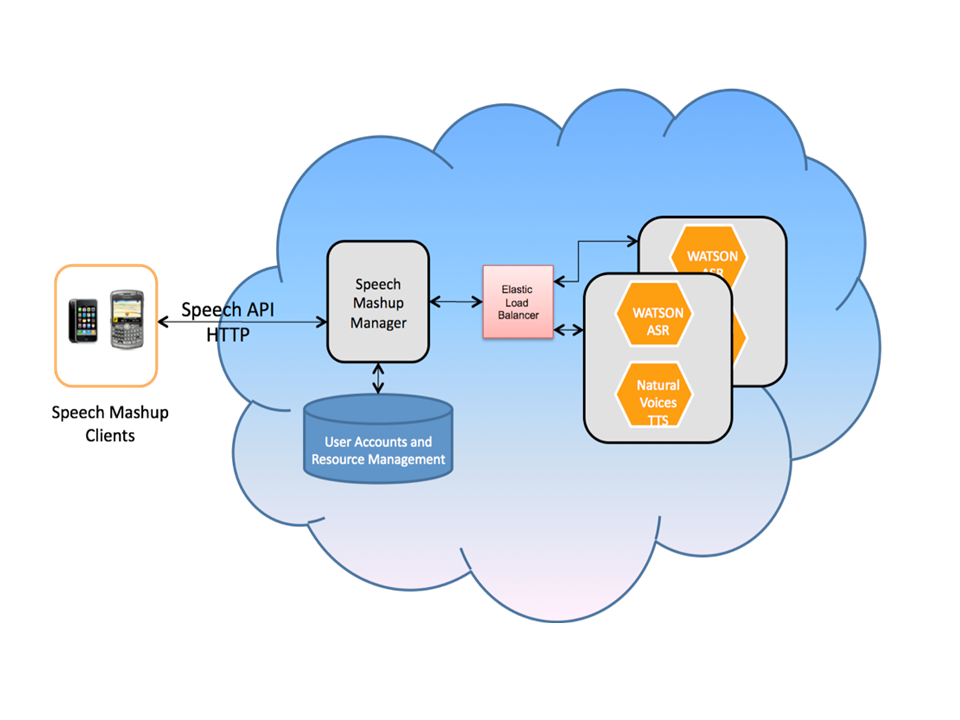
Figure 1: AT&T Speech Mashup Cloud Architecture
To validate and measure the performance of this model, the
AT&T speech mashup prototyping platform has been ported to the Amazon cloud (Figure 1).
In this illustrative architecture, the Speech Mashup Manager runs on its own
virtual instance and takes care of the user accounts and resource management
databases. It also forwards all the speech mashup client requests to the
appropriate speech service (either WATSON ASR
or Natural
Voices TTS). The ASR and TTS engines are bundled together on the same
machine image, and at runtime the instance can be automatically configured to
run either one or both services. To support auto-scaling, an elastic load
balancer sits in front of the ASR/TTS instances, and it takes care of balancing
the load by sending requests to the instances in a round-robin fashion.
In a minimal configuration the system requires one instance for the SMM
manager, one load balancer, and one instance for the ASR/TTS engines. The
system is currently configured so that if the CPU utilization on the ASR/TTS
engine instance reaches 80 percent, the Amazon auto-scaler will start another
ASR instance and automatically add it to the load balancer pool.
The database containing the user accounts and application grammars is stored instead on an Elastic Block Storage volume mounted on the SMM instance. In order to make the users and built-in grammars available to the instances running the WATSON ASR engine, a virtual tunnel over TCP/IP is setup between the SMM and the ASR/TTS instances. Then the file system containing the grammars is NFS mounted over the tunnel to allow the WATSON ASR engines to view and receive updated grammars in real-time.
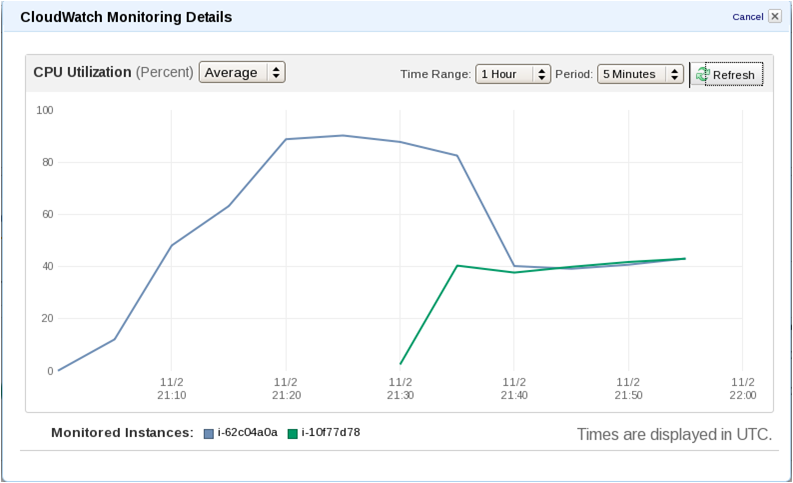
Figure 2: ASR CPU utilization during traffic load simulation
Testing the Speech Mashups in the Cloud involved using a traffic simulator generating a random traffic pattern based on a Poisson process [3]. The ASR engine was stressed at different traffic loads and grammar sizes. In all test condition, the auto-scale trigger was activated when the CPU load reached the 80% of the CPU usage for more than ten minutes, and a new instance was created in few minutes to absorb the extra load (Figure 2). Conversely, the extra instance was removed from the ASR pool when the load normalized below the 40% threshold.
Compared to traditional carrier-grade telephony services where the uptime is typically a solid 99.999% (or 30 sec downtime per year), cloud computing is accountable for less 'nines' with an uptime in the order of 99.95% (see, for example, Amazon EC2 SLA). In fact, service instances running in a cloud infrastructure can sometimes crash or slow down in case the neighboring instances (e.g., processes running on the same physical server) are heavy CPU or network users. In heavy load conditions, load balancers can stop routing traffic, and network latencies can suddenly increase. A solution to this problem is architecting services for redundancy and handling failures gracefully. For example, running multiple instances in different geographical locations (i.e., deploying services in physically distinct data centers), and taking frequent snapshots of the service data might help to mitigate downtime in case of failures. However, it terms of user experience, failures usually translates in a sluggish response time that can be alleviated with visual feedback in the mobile screen.
Another frequently asked question surrounding cloud computing is about security. How secure is the cloud environment? The answer is as secure as the service designer is willing to make it, which translates into spending more time architecting application security. This typically may involve several techniques: 1) enforcing strict firewall policies; 2) opening only the minimum set of communication ports necessary to provide services; 3) use secure shell to connect to instances; 4) disable privileged logins; 5) encrypt data for extra protection, etc. This process is also known as system hardening and can be consolidated by using tools such as Bastille for Linux.
Speech processing in the cloud is a viable solution for applications running on mobile devices, desktops, laptops and IVR systems. The infrastructure is highly available, economical, scalable, and reliable. Moreover the cloud model ultimately translates capital expenses into operational costs, allowing service providers to focus on delivering new technologies and applications, thus reducing time to market. As an example, the AT&T Speech Mashup prototyping framework [1] was successfully ported to the Amazon cloud and the current speech mashup applications were migrated to the cloud framework.
Finally, it's easy to predict how the benefits of cloud computing will soon obsolete traditional IT solutions and will captivate in the near future more and more speech-enabled application providers.
[1] Giuseppe Di Fabbrizio, Jay G. Wilpon, Thomas Okken, A Speech Mashup Framework for Multimodal Mobile Services, The Eleventh International Conference on Multimodal Interfaces and Workshop on Machine Learning for Multi-modal Interaction (ICMI-MLMI 2009), Cambridge, MA, USA, November 2-6, 2009.
[2] A. Gruenstein, I. McGraw, I. Badr, The WAMI toolkit for developing, deploying, and evaluating web-accessible multimodal interfaces, ICMI '08: Proceedings of the 10th international conference on Multimodal interfaces, ACM, 2008, 141-148
[3] James F. Brady, Load Testing Virtualized Servers Issues and Guidelines
[4] George Reese, Cloud Application Architectures - Building Applications and Infrastructure in the Cloud, O'Reilly, 2009.
If you have comments, corrections, or additions to this article, please contact the authors: Giuseppe (Pino) Di Fabbrizio, pino [at] research [dot] att [dot] com, Danilo Giulianelli, danilo [at] research [dot] att [dot] com.
Danilo Giulianelli is Principal Member of Technical Staff at AT&T Labs Research.
Giuseppe (Pino) Di Fabbrizio is Lead Member of Technical Staff at AT&T Labs Research.
SLTC Newsletter, January 2010
Meetings provide an efficient way of interaction, and create unique knowledge sharing opportunities between people with different areas of expertise. Every day, especially within organizations, people meet for various reasons, such as discussing issues, task assignments, and planning. Although meetings are so common, there is still no globally adopted automated or semi-automated mechanism for tracking meeting discussions, following up with task assignments, saving the meeting content for later use by participants or non-participants, or checking the efficiency of meetings.
Recently, the availability of meetings corpora such as the ICSI [1] and AMI [2] corpora, and shared task evaluations such as the ones performed by NIST, have facilitated research on automatic processing of meeting speech. The ICSI corpus [1] consists of 75 natural meetings with a variable number of participants, that took place at the ICSI. The AMI corpus [2] is a multi-modal, scenario-driven data collection from meetings of 4 participants each. In general, such human-human communication in stored audio form has rapidly grown in providing ample source material for later use. In particular, the prominence of the voice search as a basic user activity has increased significantly along with the advances in speech recognition and retrieval.
However, there are still open questions: What information from these meetings would be useful for later use? Does this information depend on user/purpose? How could the transcripts of these conversations be used? Our goal in this article is not to answer these questions, but provide a brief (and far from complete) overview of some of the research done in the last decade to process meetings for providing access to their contents:
All of these tasks, along with lesser studied tasks such as argument diagramming [10] and detection of sentiments [13], agreement and disagreements [11,12] would greatly assist the ability to automatically browse, summarize, and graphically visualize various aspects of the spoken content of the meetings.
Dilek Hakkani-Tür is a Senior Research Scientist at the International Computer Science Institute (ICSI), with research interests in natural language and speech processing, spoken dialog processing, active and unsupervised learning for language processing. Email: dilek@icsi.berkeley.edu
SLTC Newsletter, February 2010
The management of King's College London has embarked on a program of radical restructuring in both its Science and Humanities Faculties. This program involves redefining research missions of Departments in these schools under thematic areas that, in Humanities at least, downplay many major areas of research and teaching, and explicitly exclude linguistics in any department.
As part of this process, Jonathan Ginzburg has been targeted for redundancy on the grounds that he no longer fits the redefined group for applied logic and the theory of computing in the Computer Science: with testimony from leading international researchers that his work on the logical analysis of interaction falls directly within the new group description, this matter is now under appeal.
Professor Shalom Lappin and Dr. Wilfried Meyer-Viol of the Philosophy Department have been summarily told that the College is "disinvesting" from computational linguistics, and that the plan for restructuring the School for Arts and Humanities will mean the elimination of their positions in Philosophy by August 31. The move is an attempt to use computational linguistics, a non-existent entity in Philosophy, to target these two researchers. Lappin's research is fundamentally interdisciplinary, integrating core areas of philosophy, specifically intensional logic, formal semantics, and philosophy of language into cognitive science, machine learning, and computational learning theory. Meyer-Viol is first and foremost a philosophical logician who does 75% of the logic teaching in the University, who publishes both in this area, in formal grammar, and in issues at the interface of syntax/semantics. They are fully integrated into the Department's research, teaching, and administrative activities. The School is also targeting other linguists, and other departments. It is worth pointing out that the King's Philosophy Dept. was ranked third in the UK in the 2008 Research Assessment Exercise, and the Principal, Rick Trainor, has referred to the Philosophy Department as "the jewel in the crown" of the College, so that this is an extraordinary way to encourage one of its strongest departments, ironically at a time when interdisciplinary research is very generally recognized by national and international funding bodies as the way forward.
The issue is however wider than this, since these moves are made as an instance of a broad procedure affecting the entire academic community of two primary Schools of the College. Initiating movements to give people notice is going on in parallel with supposed consultation, with no attempt at finding alternative ways of reducing the salary budget: indeed all academics in Humanities have been told that they are in effect “at risk of redundancy”, even though the consultation process is only now beginning to take place. This is part of a pattern of widespread cuts and “restructuring” that is currently going on in British universities, but for such a distinguished institution of research, scholarship, and teaching to allow these management-led procedures in determining both academic content and individuals/areas to be targeted sets a very dangerous precedent for the suppression of academic freedom and the destruction of the autonomy of research across the UK and beyond.
We urge you to write to the management at King's to protest these actions. The people to send email to are:
If you have comments or responses to this article, please leave a comment below, or contact the author: Ruth Kempson (ruth.kempson@kcl.ac.uk).
Ruth Kempson is Professor of Linguistics FBA, emeritus, King's College London
SLTC Newsletter, February 2010
Setting up a new research group presents special challenges and opportunities. This article describes the work of the Interaction Lab, and some of the main issues we considered when setting up this new research facility.
![]() It's just over 3 months since our unique group of 5 postdoctoral
researchers moved to the School of Mathematics and Computer Science
(MACS) at Heriot Watt
University, Edinburgh, to set up a new research lab. The Interaction Lab was
created to focus on the data-driven development and evaluation of novel multimodal interfaces, using machine learning techniques to achieve increasing levels of adaptivity and robustness.
It's just over 3 months since our unique group of 5 postdoctoral
researchers moved to the School of Mathematics and Computer Science
(MACS) at Heriot Watt
University, Edinburgh, to set up a new research lab. The Interaction Lab was
created to focus on the data-driven development and evaluation of novel multimodal interfaces, using machine learning techniques to achieve increasing levels of adaptivity and robustness.
 Setting up a new research lab is an exciting opportunity, which
presents a variety of challenges. Reflecting on our progress in the
past months, the most important stages in our development have been:
Setting up a new research lab is an exciting opportunity, which
presents a variety of challenges. Reflecting on our progress in the
past months, the most important stages in our development have been:
Regarding our vision and mission statement, it is important to develop shared goals about the long-term aspirations for our research, and especially to allow room for future growth and exploration of new research areas. A focus on computational models of "Interaction" is allowing us to develop from our core expertise in machine learning for data-driven multimodal interaction, into new explorations of statistical modelling in interactive systems more widely, for example in environmental and ecological modelling, robotics, and affective computing.
In terms of our hardware setup, we are developing the capacity to deploy speech interfaces to the general public. One of the current challenges in Spoken Dialogue System development is testing and gathering data in realistic environments with self-motivated users, rather than staged experiments in a lab with scripted scenarios. Addressing this is a key part of our strategy. We are setting up a facility to collect research data from real users, rather than in lab-based experiments, and to test our systems "in the wild". We will soon have the capability to handle multiple parallel calls from both standard phone and via VOIP. This is possible through a plug-in to our lab-based dialogue system that automatically generates VoiceXML on the fly. The pilot system will enable visitors during the popular Edinburgh Festival to use our dialogue systems to get information about places of interest in Edinburgh, such as restaurants.
A sustainable funding stream is obviously vital to provide continuity of our research and to develop our research environment. We currently have funded projects in the region of £1 million. These projects cover an exciting range of techniques and applications, for example combining vision and multitouch interaction for Technology Enhanced Learning, and applying statistical planning methods in spoken dialogue systems. This funding is a combination of European Commission FP7 (see the CLASSiC project), EPSRC, and ESRC projects (see the ECHOES project). We are also actively involved in new funding proposals, in particular targeting the European Commission's Cognitive Systems and Language Technologies calls. We collaborate with many other institutions and with industry -- for example Cambridge University, the Institute of Education (London), and France Telecom/Orange Labs.
 The Interaction Lab would not exist without its researchers. We have
brought together an excellent team of individuals, each with an
international research profile, with a
unique blend of complementary skills and experience:
The Interaction Lab would not exist without its researchers. We have
brought together an excellent team of individuals, each with an
international research profile, with a
unique blend of complementary skills and experience:
Thanks to the Scottish Informatics and Computer Science Alliance (SICSA) for the funding which created the Interaction Lab. We also thank the School of Mathematics and Computer Science at Heriot-Watt University for providing a nourishing, supportive, and stimulating modern research environment.
For more information, see:
If you have comments, corrections, or additions to this article, please contact the author: Oliver Lemon, o.lemon [at] hw [dot] ac [dot] uk.
Oliver Lemon is leader of the Interaction Lab at Heriot Watt University, Edinburgh. His interests are in statistical learning approaches to multimodal interaction. Email: o.lemon@hw.ac.uk
Recent publications include:
SLTC Newsletter, February 2009
The annual Text Analysis Conference (TAC) provides a setting where participant systems are evaluated on common test sets to create direct comparisons, develop and test evaluation methods and to assess system progress. There were three main tracks at this year’s evaluation--Knowledge Base Population, Update Summarization and Recognizing Textual Entailment. More than 50 teams from countries around the world including Australia, China, Japan, Israel, India and several parts of Europe took part in these tracks. The results of this year’s evaluation were presented at the workshop conducted in November 2009. It featured technical sessions with presentations and posters from the participants as well as overviews of system performances analyzed by NIST.
The Knowledge Base Population (KBP) track was conducted for the first time at TAC this year. The focus was on systems that can mine specific pieces of information from a large text collection with the view to add them to an existing knowledge base. Over a million newswire documents were assembled by the Linguistic Data Consortium (LDC) to serve as a corpus for the various search tasks. The knowledge base was compiled from Wikipedia “info boxes”, the section in each Wikipedia article listing the most important snippets of information about the entity discussed. An example snapshot from the page for ‘Max Planck’ is below.

One of the tasks for the KBP systems was “entity linking”. Given the name of an entity and a document which mentions the name, systems had to determine if the entity being referred to existed in the database. Systems need to disambiguate the mention using the provided document to distinguish it from others with the same name. For example, the name ‘Colorado’ could refer to a state, a river or a desert. Then a link to the entry in the knowledge base must be provided if the entity already exists in it. Systems performed well overall on the entity linking task. There were however several clearly ambiguous mentions that most systems had problems disambiguating. In the KBP “slot filling” task, systems must use the collection of newswire documents to obtain missing pieces of information for an entity in the database. The entities could be people, organization or locations and a list of desirable attributes were defined for each of them.
Continuing along the lines of previous few years, this year’s summarization track focused on creation of Update Summaries. Two sets of 10 newswire documents each were given to the participants with the second set containing articles published later than the first. Systems should assume that the user has read the first set of documents. They must create a single summary of the second collection, but compiling only the new information as an update summary for the user. It was observed from the evaluations this year that selecting good content for the update summaries still remains difficult for systems with most of them obtaining scores significantly below human performance on this task.
This year NIST also introduced an evaluation track where participants could submit their own automatic metrics for summary evaluation. The currently used automatic metric, ROUGE, is a suite of n-gram statistics to compare a system summary with gold-standard human summaries, both written for the same source article. The degree of overlap gives a measure of content quality which has been shown to correlate highly with human judgments. Track participants were given the output of systems from the update task for scoring. The scores submitted by the participants were then checked for correlations with those assigned manually by NIST assessors. Interestingly, some of the participant systems outperformed or did comparably to some of the ROUGE metrics obtaining very good agreement with human judgements.
The third track was Recognizing Textual Entailment (RTE). Given two pieces of text, the task of an RTE engine is to predict if one entails the other. Recognizing entailment relationships between texts is useful for a variety of tasks. For example, in summarization, the system could be used to help remove redundant facts. While systems are often given two self-contained pieces of text for predicting entailment, this year, an additional new setup was also introduced where the candidates for entailment judgments included the full collection of sentences in a set of documents. This setup poses two challenges. Systems will need to work with a real distribution of entailment examples, where positive ones would be considerably fewer than the non-entailing examples. Secondly, individual sentences of the collection may not contain all the information needed for prediction. Indeed, runs of this pilot task brought out several issues that systems must address to do better on the task. For example, within as well as cross-document references to people, dates and places need to be successfully resolved for entailment prediction.
In addition, this year, all RTE participants were mandatorily required to present ablation results for the knowledge resources they used. Participants were asked to submit their results leaving out each resource at a time and running their system with the remaining modules. This way one could analyze which resources when removed had the greatest impact on performance. The results showed that the impact of resources varied greatly depending on how systems used them. For example, WordNet, one of the commonly used resources had a negative impact when removed for some systems, at the same time, improving performance for some others. But such analyses are helpful to understand which resources are overall beneficial so that they could be shared to assist faster system development.
In sum, the new tasks that were introduced and the evaluations brought out several relevant issues in task design and evaluation for text analysis systems. Participants shared their experiences with one another at the talk and poster sessions. More information at: http://www.nist.gov/tac/
If you have comments, corrections, or additions to this article, please contact the author: Annie Louis, lannie [at] seas [dot] upenn [dot] edu.
SLTC Newsletter, February 2010
One of the great challenges to near-total paraplegics is the inability to communicate effectively with others. This problem is often due to the lack of control to the articulators that control speech production. Within the past decade, researchers in neurology have developed "brain-machine interfaces" - or BMIs - that allow people to communicate with only their thoughts. Advances in this field are now allowing a paraplegic patient to control a real-time speech synthesizer using a BMI that reads the neural signals that relate to the production of speech.
Until recently, the most advanced communication technology for paraplegics was mental control of typing keys - at the rate of about one word per minute. Keys can be selected when a brain-machine interface reads a patient's neural signals from the motor cortex of the brain. Unfortunately, this method of communication, although beneficial, makes it challenging for patients suffering from paralysis to hold live conversations with others, like family members or caretakers. Dr. Frank Guenther, Professor of Cognitive and Neural Systems at Boston University, and his collaborators are leading an innovative next step forward for BMIs - reading a paraplegic patient's thoughts and converting them to speech using a speech synthesizer [1].
The patient in this study (male, 26) suffers from "locked-in syndrome," which is almost complete paralysis, but with full control of cognitive abilities. The only voluntary control that the patient has is his ability to blink. For Guenther and his group, the focus was to locate the areas in the brain that control speech and its associated articulatory motor controls. They determined the precise areas that relate to the production of formant frequencies, the spectral representation of speech. Their primary goal for this study was to determine when the patient was attempting to produce vowels with his thoughts - a goal that could potentially be achieved just by learning about the brain signals that control formant frequencies in speech.
Once electrodes are implanted in the brain, a synthesis BMI can read the neural signals that pass through - wirelessly. In their system setup, when the patient's brain produces signals that correlate to the production of formant frequencies, an FM receiver picks up the neural signals transmitted (after amplification) by the implanted electrodes. Guenther and his colleagues used an existing model, the DIVA model, to determine where to place electrodes in the brain [2]. These signals are then digitized by a recording system, which converts them into "spikes". The "spikes" are then processed into the first and second formant frequencies, F1 and F2. This information is passed as input to a speech synthesizer, which provides almost immediate speech-based feedback to the patient.
The system's accuracy at determining the patient's intended vowels increased with practice. In practice sessions, the patient was instructed to listen to an example of the vowel he should speak (e.g., the "e" sound in "heat"), then think about speaking that vowel. Response time from the speech synthesizer after reading the patient's neural signals was almost instantaneous - 50ms. Over a period of 25 sessions, the patient's accuracy with BMI-based control of the synthesizer improved dramatically - from 45% to 70%.
Their key finding was that neural electrodes, when implanted in the brain, can potentially be a reliable method for allowing patients to communicate using a real-time speech synthesizer. This rapidly increases the pace of conversation that paraplegics can have with others. Also, this research can help us understand how the areas of the brain associated with speech-based motor control transmit information. This BMI is the first of its kind that uses an implanted electrode to control a BMI wirelessly - no other major hardware beyond an FM receiver and a computer is needed. Guenther and his colleagues believe that their results could be improved by installing more electrodes in the speech areas of the brain.
While vowel production by the patient has become fairly accurate with practice (70%), open questions remain when it comes to producing consonants. Guenther and his colleagues suggest one novel approach that holds promise when combined with their current work - to read the neural signals that control the motor pathways to articulatory speech muscles. Although this strategy has potential, it needs to be tested with people that have motor control of the speech articulators. They believe that this approach will be similar to what has been conducted with mouse cursor control-based BMIs. Despite the serious challenges that lie ahead for these researchers, the end goal is worth their efforts - those without the ability to speak may one day be able to hold real-time conversations with only their thoughts.
For more information, please see:
The ISCA Student Advisory Committee (ISCA-SAC) was established in 2005 by the International Speech Communication Association (ISCA) to organize and coordinate student-driven projects. We were especially active in 2007 and 2008, we were pleased to continue our efforts in 2009, and we look forward to 2010.
The ISCA-SAC organized a student panel discussion session during Interspeech 2009. The aim was to offer students a fruitful discussion with senior researchers regarding different methods of research. This year, we addressed the question of 'Research in Academia vs Research in Industry' and the invited speakers were: Geoffrey Zweig (Microsoft Research), Philippe Bretier (Orange Labs) and Mike McTear (University of Ulster).
This year, ISCA is celebrating its 10th anniversary. In order to promote this event, a poster design contest on the topic of the 10th anniversary was announced in early 2009 by ISCA-SAC. It turned out to be a really difficult task to select a winner out of the 72 candidates. The ISCA Board selected five posters for the final round, these consisting of contributions by Karem Laguna, Robert Lawley, Jamal Issawi, Alberto Forcada and Johanna Vinterhav. Out of these finalists, one poster came out on top according to the jury's judgement. The winning poster was presented by the president of ISCA, Prof. Isabel Trancoso, at the opening ceremony of the Interspeech 2009 conference. The winner of the 'ISCA 10th Anniversary Poster Design Contest' is Jamal Issawi (Lebanon).
ISCA-SAC managed the Online Grant Application System (OGAS) during Interspeech 2009. OGAS was developed in 2008 by student volunteers to facilitate the grant application process for both the applicant and the ISCA grants coordinator.
One of ISCA-SAC's main goals is in the transition of the website to Web 2.0 while simplifying access to the large range of information available on the website. A first version of the newly developed website, including a blog was launched in late 2009.
In order to develop a more interactive exchange with students and senior researchers working in the field of speech communication science and technology, ISCA-SAC has embraced new methods of social networking. A facebook group and a twitter page were created in early July 2009. Each group has already 60 and 16 members respectively.
In conjunction with the IEEE-SLTC e-newsletter and the History of Speech and Language Technology Project, student volunteers have worked hard to provide transcriptions of interviews from various researchers who have made seminal contributions to the development of speech and language technology. The students transcribed interviews with the Joseph Perkell, Lauri Karttunen, William Labov, who described how they came to be involved in the field of speech technology. These are available in 1 2 3 articles in the e-newsletter.
During 2010, ISCA-SAC will keep on maintaining the services it used to offer during the previous years; this includes managing the online grant application system for the 2010 ISCA sponsored conferences and workshops, and mainly for the Annual Interspeech 2010 conference taking place in Makuhari, Japan.
During the conference, ISCA-SAC is planning to organize one or two scientific events including a Panel Discussion or a Round Table Lunch discussion. All the students are gladly welcome to attend and participate. In addition to Interspeech, ISCA-SAC is co-organizing the Young Researchers' Roundtable on Spoken Dialog Systems YYRSDS-10.
ISCA-SAC is also planning to widen its coverage by increasing efforts to contact Masters and PhD students around the world, and advertising its activities and work.
One of the goals ISCA-SAC is also working to achieve in the future is to reach young researchers in developing countries, by for example, creating special interest groups. This project aims at boosting the possible regional efforts and collaborations among students in these countries.
We welcome student participation at any level, and are always open to new ideas from anyone; please feel free to contact us on our web page or by email at volunteer[at]isca-students[dot]org.
SLTC Newsletter, February 2010
We hosted ASRU 2009 in Merano (Italy), a lovely Italian town at the heart of Europe, close to the border with Austria and Switzerland. This town and the surrounding region are reminiscent of past history when the multilingual European elite would gather here for important social events.
We have had 180 attendees from all over the world, mostly from North America, Europe and Japan. Central and Southern America as well as Asia were not well represented, similarly to past ASRUs, and we believe as a scientific community we should make efforts to extend our reach to those countries. A total of 223 papers were submitted for the poster sessions and 96 high-quality papers were accepted. We also assigned the best paper and best student awards, selected by the technical chairs.
The technical program was a high-paced schedule with interleaved paper presentations and thematic invited lectures. The invited lectures were outstanding and gave the opportunity to junior and senior researchers to review and appreciate the fundamentals and challenges of topics ranging from human speech recognition to acoustic modelling, to machine learning. The keynote speakers addressed important research issue in ASR , generalization, and new trends in speech and language processing, social computing. We would like to thank our invited speakers for their technical contributions that made ASRU 2009 greatly appreciated by attendees.
The social events are an important part of the workshop and is important create the network between community newcomers, colleagues and friends. The central event was the banquet at the Katzenzungen castle, one the hundreds of privately and publicly owned castles in this region. This castle is famous for hosting one of the oldest winery in Europe. We had the opportunity for once to have dinner in a magic medieval setting and closed the dinner with a special guest appearance from our talent gifted colleagues ( Video ).
One of the objective we had for ASRU 2009 was to make it long-lasting event and preserve the scientific contributions as well as discussions and impressions from our community at this point in time. For this reason we have launched an initiative to record such memories in terms of knowledge that was shared ( invited talks ), discussions, pictures and interviews to members of the community. As of now we are in the process of populating such archive and turn it into a searchable multimedia event. We believe such digital content could be used, tagged and augmented for research by our (extended) community. Researchers will be able to access, contribute and peruse the ASRU2009 digital event starting from the website , as we make progress in the sponsoring research project at University of Trento, Livememories . Stay tuned! Not to leave this effort isolated we hope future ASRU organizers share the same vision and will be glad to help.
Last but not least we would like to thank the members of the workshop technical and organizing committee, public and private sponsors for making ASRU 2009 a memorable event, so they say. See you at ASRU 2011.
For more information, see:
If you have comments, corrections, or additions to this article, please contact : Giuseppe Riccardi, riccardi [at] disi [dot] unitn [dot] it.
Giuseppe Riccardi is Professor at University of Trento (Italy). Renato De Mori is Professor Emeritus at McGill University (Canada) and University of Avignon (France)
SLTC Newsletter, February 2010
Many speech scientists believe that human speech processing is done first by identifying regions of reliability in the speech signal and then filling in unreliable regions using a combination of contextual and stored phonological information [1]. However, most current decoding paradigms in speech recognition consist of a left-to-right (and optional right-to-left) scoring and search component without utilizing knowledge of reliable speech regions. This is particularly a problem when the search space is pruned, as pruning algorithms generally do not make use of the reliable portions of the speech signal, and hence may prune away too many hypotheses in unreliable regions of the speech signal and keep too many hypotheses in reliable regions. Island-driven search is an alternative method to better deal with noisy and unintelligible speech. This strategy works by first hypothesizing islands from regions in the signal which are reliable. Further recognition works outwards from these anchor points to hypothesize unreliable regions. In this article, we discuss past research in island-driven search and propose some future research directions.
The BBN Hear What I Mean (HWIM) speech understanding system [2] was one of the first systems to utilize island-driven search for sentence parsing. In this system, parsing does not start at the beginning of the word network, but rather can start at confident regions within the network, at places known as islands. Parsing works outwards left and right from these island regions to parse a set of gap regions. While this type of approach showed promise for small grammars, it has not been explored in large vocabulary speech recognition systems due to the computational complexities of the island parser.
In addition, [3] explores using island-information for sentence parsing. This paper looks at computing language model probabilities when the sentence is generated by a stochastic context-free grammar (SCFG). Specifically, the language model is computed by first having the parser focus on islands, defined as works with high semantic relevance. The parser then proceeds outwards towards gaps to compute the total language model score. While this paper presented solid theory behind an island-driven search parser, subsequent use of this theory in modern day ASR systems has not been heavily explored.
Furthermore, [4] explores island-driven search for isolated-word handwriting recognition. The authors identify reliable islands in isolated words to obtain a small filtered vocabulary, after which a second-pass more detailed recognition is performed. This technique is similar to that explored by Tang et al. in [5] for improving lexical access using broad classes. However, these solutions cannot be directly applied to continuous speech recognition.
More recent work in island-driven search has focused on extending theories from the above papers into modern day continuous ASR. For example, Kumaran et al. have explored an island-driven search strategy for continuous ASR [6]. In [6], the authors perform a first-pass recognition to generate an N-best list of hypotheses. A word-confidence score is assigned to each word from the 1-best hypothesis, and islands are identified as words in the 1-best hypothesis which have high confidence. Next, the words in the island regions are held constant, while words in the gap regions are re-sorted using the N-best list of hypotheses. This technique was shown to offer a 0.4% absolute improvement in word error rate on a large vocabulary conversational telephone speech task. However, if a motivation behind island-driven search is to identify reliable regions to influence effective pruning, identifying these regions from an N-best list generated from a pruned search space may not be an appropriate choice.
In [7], broad phonetic class (BPC) knowledge was utilized for island-driving search. First, islands were detected from knowledge of hypothesized broad phonetic classes (BPCs). Using this island/gap knowledge, a method was explored to prune the search space to limit computational effort in unreliable areas. In addition, the authors investigate scoring less detailed BPC models in gap regions and more detailed phonetic models in islands. Experiments on both small scale vocabulary tasks indicate that the proposed island-driven search strategy results in an improvement in recognition accuracy and computation time. However, the performance of the island-driven search methods for large scale vocabulary tasks is worse than baseline methods. One possible reason for this performance degradation is that the island-driven search remains left-to-right in the proposed technique, opening up the idea of doing a bi-directional search.
While some of the current work in island-driven search has shown promise, there are plenty of interesting research directions and unanswered questions. As the work in [6] indicated, one major question is how to define an island. For example, as [1] discusses, when humans process speech, they first identify distinct acoustic landmarks to segment the speech signal into articulatory-free broad classes. Acoustic cues are extracted at each segment to come up with a set of features for each segment, which make use of both articulator-bound and articulator-free features. Finally, knowledge of syllable structure is incorporated to impose constraints on the context and articulation of the underlying phonemes. Perhaps one idea is to look at defining islands though combination of articulator-free and articulator-bound cues, in conjunction with syllable knowledge.
A second topic of interest is how to perform the island-driven search. Second, the nature of speech recognition poses some constraints on the type of island-driven search strategy preferred. While island searches have been explored both unidirectionally and bi-directionally, the computational and on-line benefits of unidirectional search in speech recognition make this approach more attractive. Furthermore, if reliable regions are identified as sub-word units and not words, a bidirectional search requires a very complex vocabulary and language model. However, unidirectional island-driven search might not always address the problem of good hypotheses being pruned away. Therefore, in the future, an interesting research direction might be exploring bi-directional search strategies might which first start in the reliable island regions and works outwards to the gaps.
For more information, please see:
[1] K. N. Stevens. Toward A Model for Lexical Access Based on Acoustic Landmarks and Distinctive Features. Journal of the Acoustic Society of America, 111(4):1872–1891, 2002.
[2]W. A. Lea, Trends in Speech Recognition. Englewood Cliffs, NJ:
Prentice Hall, 1980.
[3] A. Corazza, R. De Mori, R. Gretter, and G. Satta. Computation Probabilities for an Island-Driven Parser. IEEE Transactions on Pattern Analysis and
Machine Intelligence, 13(9):936–950, 1991.
[4] J. F. Pitrelli, J. Subrahmonia, and B. Maison. Toward Island-of-Reliability-Driven Very-Large-Vocabulary On-Line Handwriting Recognition Using Character
Confidence Scoring. In Proc. ICASSP, pages 1525–1528, 1991.
[5] M. Tang, S. Seneff, and V. W. Zue. Modeling Linguistic Features in Speech Recognition. In Proc. Eurospeech, pages 2585–2588, 2003.
[6] R. Kumaran, J. Bilmes, and K. Kirchhoff, “Attention Shift Decoding for Conversational Speech Recognition,” in Proc. Interspeech, 2007
[7] T. N. Sainath, "Island-Driven Search Using Broad Phonetic Classes," Proc. ASRU, Merano, Italy, December 2009.
If you have comments, corrections, or additions to this article, please leave a comment below or contact the author: Tara Sainath, tsainath [at] us [dot] ibm [dot] com.
Tara Sainath is a Research Staff Member at IBM T.J. Watson Research Center in New York. Her research interests are in acoustic modeling. Email: tnsainat@us.ibm.com