Speech and Language Processing Technical Committee Newsletter
February 2012
Welcome to the Winter 2012 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter.
It is my great pleasure and honor to be the successor of Jason Williams as the Editor-in-Chief of the IEEE SLTC Newsletter. Both Jason and the previous Editor-in-Chief Mike Seltzer kept the bar very high, establishing a top class newsletter, which is now much more than just a list of conference or jobs announcements. Thus, we'd like to thank the previous editorial team, volunteer reporters, invited and guest contributors, IEEE administrative team, and whole speech and language processing community for supporting this newsletter to be a phenomenal success within the IEEE Signal Processing Society. We'd like to especially thank Jason Williams and Chuck Wooters who have spent many hours trying to get the new team up to the speed.
We believe this Newsletter has contributed significantly in establishing a culture within the IEEE Speech and Language Processing community. Our goal is move this one step further in line with the current vision, towards a more interactive and dynamic Newsletter content. We will greatly appreciate your ideas, opinions, and thoughts to this end.
In this issue we are pleased to provide another installment of brief articles representing a diversity of views and backgrounds. This issue includes 12 articles from 14 guest contributors, and our own staff reporters and editors.
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions. You can submit job postings here, and reach us at speechnewseds [at] listserv (dot) ieee [dot] org.
Finally, to subscribe the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Dilek Hakkani-Tür, Editor-in-Chief
William Campbell, Editor
Patrick Nguyen, Editor
Martin Russell, Editor
From the SLTC and IEEE
From the IEEE SLTC chair
John Hansen
Updates on ICASSP 2012, and signal processing competitions/challenges based on recent interests from the IEEE Signal Processing Society.
The SLTC Newsletter : 2009-2011
Jason Williams
A retrospective on the SLTC Newsletter over the past 3 years.
IEEE Transactions on Audio, Speech, and Language Processing, Inaugural Editorial
Li Deng
Riding the Tidal Wave of Human-Centric Information Processing—Innovate, Outreach, Collaborate, Connect, Expand, and Win.
2012 IEEE Spoken Language Technology (SLT) Workshop
Yang Liu and Ruhi Sarikaya
2012 IEEE Spoken Language Technology Workshop (SLT 2012) will be held
at Miami Beach Resort & Spa in Miami, Florida, on Dec 2-5, 2012.
Pitch Tracking Corpus with Multipitch Tracking Evaluation
Franz Pernkopf, Michael Wohlmayr, and Gernot Kubin
Recently, our lab developed a fully probabilistic model for multipitch tracking which integrates a speaker interaction model in a factorial hidden Markov model (FHMM).
An Overview of Acoustic Modeling Techniques from ASRU 2011
Tara N. Sainath
The Automatic Speech Recognition and Understanding Workshop (ASRU) was recently hosted in Hawaii from December 11-15, 2011.
Interview: AAAI Fall Symposium on Building Representations of Common Ground with Intelligent Agents
Matthew Marge
Perhaps you’ve heard the term common ground used in many different facets of life - from international relations to friendly conversations. But have you heard the term used as a way to explain how people communicate?
WordsEye - from Text to Image
Svetlana Stoyanchev
Wordseye is a software that generates 3-dimensional graphical scenes.
Unlike 3d Max or Maya, Wordseye's input is plain text. The idea behind this project is to create scenes in a very quick manner by simply describing what you want to see in a scene.
The Kaldi Speech Recognition Toolkit
Arnab Ghoshal and Daniel Povey
Kaldi is a free open-source toolkit for speech recognition research. It is written in C++ and provides a speech recognition system based on finite-state transducers, using the freely available OpenFst, together with detailed documentation and scripts for building complete recognition systems.
The INTERSPEECH 2011 Speaker State Challenge - a review
Björn Schuller, Stefan Steidl, Anton Batliner, Florian Schiel, and Jarek Krajewski
Book Review: Stephen Ramsay’s “Reading Machines”: Toward an Algorithmic Criticism
Antonio Roque
Stephen Ramsay's book "Reading Machines: Toward an Algorithmic Criticism" provides a humanist's perspectives on computational text analysis as disruptive and performative.
Audio and Acoustic Signal Processing Challenges Launch 2012
Patrick A. Naylor
The IEEE Technical Committee for Audio and Acoustic Signal Processing (AASP) will be launching a `Challenges' activity in order to encourage research and development with comparable and repeatable results, and to stimulate new ground-breaking approaches to specific problems in the AASP technical scope.
From the SLTC Chair
John H.L. Hansen
SLTC Newsletter, February 2012
Welcome to the next installment of the SLTC Newsletter of 2012. In this update from the SLTC Chair, I will cover two aspects (i) ICASSP-2011 and (ii) signal processing competitions/challenges based on recent interests from the IEEE Signal Processing Society.
IEEE ICASSP-2012: First, many thanks to the speech and language processing community for your submissions to IEEE ICASSP-2012! The program is now finalized, so please visit the website IEEE ICASSP-2012 http://www.icassp2012.com. I would like to highlight some items relating to topics/activities in speech and language processing. The program includes a number of Plenary Talks from internationally recognized leaders in signal processing, with speech, language, and man-machine interaction well represented!
Please see the speech and language related Plenary Talks including:
Tuesday, March 27, 11:30-12:30, Main Hall: "Audio and Acoustics Signal Processing: the Quest for High Fidelity continues", by Karlheinz Brandenburg
Wednesday, March 28, 9:00-10:00: Room A: "From Signal Processing to Information Extraction of Speech: A New Perspective on Automatic Speech Recognition", by Chin-Hui Lee
Tutorials are also an excellent chance to see overviews and learn of the latest advancements in speech and language processing in a focused block of time. With mobile technology advancing, improved speech and language or man-machine interaction is seeing significant growth (as highlighted in the recent IEEE ESPA-2012 conference (Emerging Signal Processing Applications: http://www.ieee-espa.org/) in Las Vegas, NV as a companion meeting to the 2012 Consumer Electronics Show (CES). For ICASSP-2012, there are four tutorials which are speech/language related:
We very much wish to acknowledge and thank Industry for your continued support of ICASSP!
Speech and language processing continues to be largest technical concentration area within ICASSP, and hope all will visit Kyoto and participate in this year's conference.
IEEE SPS Challenges/Competitions: As a second item here for this newsletter, I would like to bring to your attention interest from the IEEE Signal Processing Society to establish more IEEE SPS Competitions. The SLTC received request from SPS to suggest potential topics/areas for new competitions for future SPS activities. Such friendly challenges serve as an excellent opportunity for researchers to circle their efforts onto a focused issue to bring about collective advancements on problems which in general continue to be a challenge for the community.
Since the speech and language community has been very active in competitions (or challenges), the SLTC embarked on process to collect feedback and summarize events over the past decade or so relating to speech and language processing. We sought out help and input from colleagues within ISCA (International Speech Communications Association [http://www.isca-speech.org/]) who have been active in this domain for some time. With the help of some key contributors, including the SLTC External Relations Sub-committee, we collected the following list of challenges (thanks to: Isabel Trancoso, Peter Li, Antonio Bonafonte, Doug O'Shaughnessy, Honza Cernocky):
Machine Translation Evaluation: for GALE (Global Autonomous Language Exploitation)
NIST (2006, 2007, 2008) - follow-on is BOLT & BABEL http://www.nist.gov/itl/iad/mig/gale.cfm
BABEL (rapid speech recognition advancements for low resource languages): [IARPA (2011/12)] http://www.iarpa.gov/Babel_PD_post.pdf
(public page on the evaluation not available at this time)
BEST (IARPA Phase I): BEST Evaluation Speaker Track: NIST and IARPA 2011 http://www.iarpa.gov
(public page on the evaluation not available)
CLEAR (Classification of Events, Activities and Relationships) Evaluation: Acoustic Event Detection and Classification:
NIST and CHIL project (2007) http://www.clear-evaluation.org/
Albayzin: Iberian languages (speech synthesis, audio segmentation, speaker diarization, language recognition)
Red Temática en Tecnologías del Habla, SIG-IL (2006, 2008, 2010) http://fala2010.uvigo.es/
ESTER (Évaluation des Systèmes de Transcription Enrichie d'Émissions Radiophoniques)
ETAPE (Évaluations en Traitement Automatique de la Parole)
AFCP http://www.afcp-parole.org/
MOBIO ICPR 2010: Face and Speaker Verification Evaluation: MOBIO project - IDIAP, University of Oulu, Brno University of Technology, 2010 http://www.mobioproject.org/icpr-2010
Given this extensive list of activities, the SLTC recommended to the IEEE SPS that the speech and language processing field is well represented and we did not recommend any new topics. However, if someone feels an interest, please contact the SLTC and our group would be happy to discuss an option to help coordinate!
In closing, I hope you will join the SLTC in participating in IEEE ICASSP-2012 in Kyoto, Japan in March 25-30, 2012. We look forward to seeing friends and colleagues and seeing the cherry blossoms in beautiful Kyoto, Japan.
Best wishes…
John H.L. Hansen
February 2012
John H.L. Hansen is Chair, Speech and Language Processing Technical Committee.
The SLTC Newsletter : 2009-2011
Jason Williams
SLTC Newsletter, February 2012
My 3-year term on the SLTC has come to an end, and with it my appointment as Editor-in-chief (EIC) of the SLTC Newsletter. This is a good time to reflect on the past 3 years, and to thank the great team I've worked with.
I started as EIC in January of 2009, when I joined the SLTC. My aim for the newsletter was to provide a forum for information and opinions not served by the main communication vehicles in the field, such as conferences and journals. I believe that there is a value in providing a news service to our community, sharing updates about new laboratories, tools, conferences, workshops, competitions, corpora, and appointments. I also believe there is value in sharing brief but considered opinions and views about developments in the field and future directions. In addition, I have encouraged accessible technical summaries of research areas, which I believe helps draw connections among those already in the field, and helps newcomers understand what we do. Finally, I have been supportive of pieces that draw new connections between our field and others.
Newsletter articles have come from several sources. Most articles have come from our excellent volunteer reporters, Svetlana Stoyanchev, Antonio Roque, Matthew Marge, Tara N. Sainath, Satanjeev "Bano" Banerjee (retired), Filip Jurcicek (retired), and Annie Louis (retired). Our reporters are self-directed, proposing their own topics for each issue. This is a substantial responsibility and I'm grateful for their tireless and creative work!
Our editors -- Pino di Fabbrizio, Martin Russell, and Stephen Cox -- have also contributed a stream of super articles. I'm also thankful for contributions from other SLTC members and from invited, guest authors.
Two important features of the newsletter are the listing of calls for papers, and job announcements. Initially the CFPs and Jobs were updated on the newsletter's quarterly publication schedule. But after the first year, we found that this update cycle was too infrequent, so we changed to a monthly update. I am very grateful to Editor Chuck Wooters for steadfastly editting CFPs and jobs for every update sent over the past 3 years.
Behind the scenes, the website is maintained by a very capable and responsive administrator, Rupal Bhatt. I thank Rupal for gracefully fielding our many requests, making numerous improvements as we progressed.
I am also grateful to the two past SLTC chairs, Steve Young and John Hansen, for giving us all the opportunity to take on this role, and for continuous support of the newsletter. Thanks also to Mike Seltzer, the previous editor-in-chief, for helping to get us off to a solid start.
In sum, I would like to thank the team -- and our readers! -- for a superb 3 years! My best wishes to the next board, led by Dilek Hakkani-Tur. I am delighted that they are taking over the reins, and I'm sure they will be successful.
Jason Williams is Principal Member of Technical Staff at AT&T Labs Research. His interests are dialog systems and planning under uncertainty. Email: jdw@research.att.com
Audio and Acoustic Signal Processing Challenges Launch 2012
Patrick A. Naylor
SLTC Newsletter, February 2012
The IEEE Technical Committee for Audio and Acoustic Signal Processing (AASP) will be launching a `Challenges' activity in order to encourage research and development with comparable and repeatable results, and to stimulate new ground-breaking approaches to specific problems in the AASP technical scope.
It's interesting to ask why audio and acoustic signal processing researchers have not so far engaged in common evaluations and competitions. Such evaluation activities have been embraced in other communities including, with notable success, speech processing. With some slight hesitancy, I offer the explanation that perhaps the evaluation of AASP algorithms is often not at all straightforward and almost always multidimensional. This is in part at least due to the need to measure things related to human perception and experience. Those objective metrics that are actually defined may be context specific and inappropriate for universal application. The next consideration is the data. Accessible and comprehensively available datasets have undoubtedly had a hugely beneficial impact on speech processing development and benchmarking. At the present time, the situation in AASP is much more fragmented and few, if any, standard datasets exist for many important AASP tasks.
This new initiative, promoted by the AASP Technical Committee, aims to address these issues. Known as `AASP Challenges', tasks will be defined with appropriate datasets and evaluation methodologies. Researchers will then be able to participate in Challenges and comparative evaluations will follow. The AASP challenges will inherit features from other competitions and challenges including NIST evaluations, the MIREX framework and the Chime Challenge.
In the current plan for Challenges, the scheme's success will depend on pro bono efforts of corporations and universities. We are all hopeful that, with some good will and guidance from the IEEE, the idea will gain traction and, eventually, catch the interest of the broader community.
The first Call for Challenges is published on the IEEE AASP TC Website. The Challenges will be overseen by a subcommittee of the AASP TC involving representatives from industry and academia and spanning the disciplines of audio, music and acoustic signal processing.
For further details: http://www.signalprocessingsociety.org/technical-committees/list/audio-tc/aasp-challenges/.
Patrick A. Naylor is Reader in Speech and Audio Signal Processing at Imperial College London. Email: p.naylor@imperial.ac.uk
2012 IEEE Spoken Language Technology (SLT) Workshop
Yang Liu and Ruhi Sarikaya
SLTC Newsletter, February 2012
2012 IEEE Spoken Language Technology Workshop (SLT 2012) will be held
at Miami Beach Resort & Spa in Miami, Florida, on Dec 2-5, 2012.
We hope the selected location and time will attract participants in
academia and industry from different countries. We plan to provide
attendees with a pleasant and informal setting that naturally
generates interactions among researchers. We invite the community
to send us their thoughts on what they would like to see in SLT 2012,
and will do our best to take into account each suggestion.
Organizing committee
Co-chairs:
Ruhi Sarikaya, Microsoft, USA
Yang Liu, University of Texas at Dallas, USA
Advisory board:
Dilek Hakkani-Tür, John Hansen, Gokhan Tur, Bhuvana Ramabhandran
Technical Chairs:
Geoffrey Zweig, Microsoft Research, USA
Katrin Kirchhoff, University of Washington, USA
Frederic Bechet, Aix Marseille University, France
Satoshi Nakamura, NCIT, Japan
Finance Chair:
Brian Kingsbury, IBM Research, USA
Jason Williams, AT&T Research, USA
Publicity Chairs:
Hakan Erdogan, Sabanci University, Turkey
Ruben San-Segundo Hernandez, Technical University of Madrid, Spain
Publication Chairs:
Kate Knill, Toshiba, UK
Andrew Rosenberg, CUNY, USA
Local Organizers:
Michael Scordilis, University of Miami, USA
Tao Li, Florida International University, USA
Demo Chairs:
Junlan Feng, AT&T Research, USA
Ciprian Chelba, Google Research, USA
Panel Chairs:
Timothy Hazen, MIT Lincoln Labs, USA
Helen Meng, CUHK, Hong Kong
Europe Liaisons:
Steve Renals, University of Edinburg, UK
Elmar Nöth, University Erlangen-Nuremberg, Germany
Asia Liaisons:
Berlin Chen, National Taiwan Normal University, Taiwan
Frank Soong, Microsoft, China
Pitch Tracking Corpus with Multipitch Tracking Evaluation
Franz Pernkopf, Michael Wohlmayr, and Gernot Kubin
SLTC Newsletter, February 2012
Motivation
Recently, our lab developed a fully probabilistic model for multipitch tracking which integrates a speaker interaction model in a factorial hidden Markov model (FHMM) [1]. Learning this FHMM model in a statistically robust manner requires both sufficiently large training data sets and recordings from many individuals. Furthermore, laryngograph signals should be acquired in parallel to provide ground truth reference data. Existing databases, which include laryngograph recordings, are lacking in the other aspects, for example, the Mocha-TIMIT [2] data is restricted to two speakers only while the Keele corpus [3] is limited in the amount of the recorded data per speaker. Therefore, our lab recorded a new pitch tracking database called PTDB-TUG in the sound studios of Graz University of Technology.
PTDB-TUG Corpus
The PTDB-TUG contains the audio recordings and laryngograph signals of 20 English native speakers (10 female and 10 male speakers) as well as the extracted pitch tracks as a reference. The text material consists of 2,342 phonetically rich sentences, which are taken from the TIMIT corpus [4]. Each sentence was read at least once by both a female and a male speaker. In total this database consists of 4,720 recorded utterances. Details about the speakers (age, mother tongue, home country) are also labeled for each sentence [5]. For research purposes, the PDTB-TUG corpus and documentation can be downloaded free of charge from http://www.spsc.tugraz.at/tools
Evaluation
Additionally, we provide a comparison of two state-of-the-art multipitch tracking algorithms using a subset of four speakers of PTDB-TUG. The algorithms are our probabilistic approach based on FHMMs using speaker interaction models [1] and the method of Wu et al. [6] which is based on the auditory model of pitch perception using correlograms. Our probabilistic approach can be learned on speaker dependent (SD) and speaker independent (SI) data whereas the correlogram-based approach does not require any model training apart from tuning parameters. The SI-FHMM approach is better than the correlogram-based method in terms of the total error Etotal [1,5]. However, the SD-FHMM model significantly outperforms SI-FHMMs. Similar observations for another dataset are reported in [1,5]. The main benefit of the SD-FHMM model is that it improves the speaker assignment of the pitch trajectories. The tracking result for a speech mixture example of two speakers including the achieved error is shown in Figure 1.
Figure 1: Tracking example for a speech mixture; (i) Log-spectrogram of speech mixture with reference pitch trajectories; (ii) Estimated pitch trajectories with reference using SD-FHMMs (Etotal=12.30) (iii) Estimated pitch trajectories with reference using SI-FHMMs (Etotal=21.20); (iv) Estimated pitch trajectories with method in [6] (Etotal=37.42); The total error Etotal measures the performance of the algorithms including the correct assignment of the speakers (cf. [5,1]).
References
[1] M. Wohlmayr, M. Stark, and F. Pernkopf, "A probabilistic interaction model for multipitch tracking with factorial hidden Markov models," IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 799-810, 2011.
[2] A. Wrench, "A multichannel/multispeaker articulatory database for continuous speech recognition research," Phonus, vol. 5, pp. 3-17, 2000.
[3] F. Plante, G. Meyer, and A. Ainsworth, "A pitch extraction reference database," in Eurospeech, 1995, pp. 837-840.
[4] L. Lamel, R. Kassel, and S. Seneff, "Speech database development: Design and analysis of the acoustic-phonetic corpus," in Proceedings of the DARPA Speech Recognition Workshop, Report No. SAIC-86/1546, 1986.
[5] G. Pirker, M. Wohlmayr, S. Petrik, and F. Pernkopf, "A Pitch Tracking Corpus with Evaluation on Multipitch Tracking Scenario", Interspeech, pp. 1509-1512, 2011.
[6] M. Wu, D. Wang, and G. Brown, "A multipitch tracking algorithm for noisy speech," IEEE Transactions on Audio, Speech, and Language Processing, vol. 11, no. 3, pp. 229-241, 2003.
Audio and Acoustic Signal Processing Challenges Launch 2012
Patrick A. Naylor
SLTC Newsletter, February 2012
The IEEE Technical Committee for Audio and Acoustic Signal Processing (AASP) will be launching a `Challenges' activity in order to encourage research and development with comparable and repeatable results, and to stimulate new ground-breaking approaches to specific problems in the AASP technical scope.
It's interesting to ask why audio and acoustic signal processing researchers have not so far engaged in common evaluations and competitions. Such evaluation activities have been embraced in other communities including, with notable success, speech processing. With some slight hesitancy, I offer the explanation that perhaps the evaluation of AASP algorithms is often not at all straightforward and almost always multidimensional. This is in part at least due to the need to measure things related to human perception and experience. Those objective metrics that are actually defined may be context specific and inappropriate for universal application. The next consideration is the data. Accessible and comprehensively available datasets have undoubtedly had a hugely beneficial impact on speech processing development and benchmarking. At the present time, the situation in AASP is much more fragmented and few, if any, standard datasets exist for many important AASP tasks.
This new initiative, promoted by the AASP Technical Committee, aims to address these issues. Known as `AASP Challenges', tasks will be defined with appropriate datasets and evaluation methodologies. Researchers will then be able to participate in Challenges and comparative evaluations will follow. The AASP challenges will inherit features from other competitions and challenges including NIST evaluations, the MIREX framework and the Chime Challenge.
In the current plan for Challenges, the scheme's success will depend on pro bono efforts of corporations and universities. We are all hopeful that, with some good will and guidance from the IEEE, the idea will gain traction and, eventually, catch the interest of the broader community.
The first Call for Challenges is published on the IEEE AASP TC Website. The Challenges will be overseen by a subcommittee of the AASP TC involving representatives from industry and academia and spanning the disciplines of audio, music and acoustic signal processing.
For further details: http://www.signalprocessingsociety.org/technical-committees/list/audio-tc/aasp-challenges/.
Patrick A. Naylor is Reader in Speech and Audio Signal Processing at Imperial College London. Email: p.naylor@imperial.ac.uk
Pitch Tracking Corpus with Multipitch Tracking Evaluation
Franz Pernkopf, Michael Wohlmayr, and Gernot Kubin
SLTC Newsletter, February 2012
Motivation
Recently, our lab developed a fully probabilistic model for multipitch tracking which integrates a speaker interaction model in a factorial hidden Markov model (FHMM) [1]. Learning this FHMM model in a statistically robust manner requires both sufficiently large training data sets and recordings from many individuals. Furthermore, laryngograph signals should be acquired in parallel to provide ground truth reference data. Existing databases, which include laryngograph recordings, are lacking in the other aspects, for example, the Mocha-TIMIT [2] data is restricted to two speakers only while the Keele corpus [3] is limited in the amount of the recorded data per speaker. Therefore, our lab recorded a new pitch tracking database called PTDB-TUG in the sound studios of Graz University of Technology.
PTDB-TUG Corpus
The PTDB-TUG contains the audio recordings and laryngograph signals of 20 English native speakers (10 female and 10 male speakers) as well as the extracted pitch tracks as a reference. The text material consists of 2,342 phonetically rich sentences, which are taken from the TIMIT corpus [4]. Each sentence was read at least once by both a female and a male speaker. In total this database consists of 4,720 recorded utterances. Details about the speakers (age, mother tongue, home country) are also labeled for each sentence [5]. For research purposes, the PDTB-TUG corpus and documentation can be downloaded free of charge from http://www.spsc.tugraz.at/tools
Evaluation
Additionally, we provide a comparison of two state-of-the-art multipitch tracking algorithms using a subset of four speakers of PTDB-TUG. The algorithms are our probabilistic approach based on FHMMs using speaker interaction models [1] and the method of Wu et al. [6] which is based on the auditory model of pitch perception using correlograms. Our probabilistic approach can be learned on speaker dependent (SD) and speaker independent (SI) data whereas the correlogram-based approach does not require any model training apart from tuning parameters. The SI-FHMM approach is better than the correlogram-based method in terms of the total error Etotal [1,5]. However, the SD-FHMM model significantly outperforms SI-FHMMs. Similar observations for another dataset are reported in [1,5]. The main benefit of the SD-FHMM model is that it improves the speaker assignment of the pitch trajectories. The tracking result for a speech mixture example of two speakers including the achieved error is shown in Figure 1.
Figure 1: Tracking example for a speech mixture; (i) Log-spectrogram of speech mixture with reference pitch trajectories; (ii) Estimated pitch trajectories with reference using SD-FHMMs (Etotal=12.30) (iii) Estimated pitch trajectories with reference using SI-FHMMs (Etotal=21.20); (iv) Estimated pitch trajectories with method in [6] (Etotal=37.42); The total error Etotal measures the performance of the algorithms including the correct assignment of the speakers (cf. [5,1]).
References
[1] M. Wohlmayr, M. Stark, and F. Pernkopf, "A probabilistic interaction model for multipitch tracking with factorial hidden Markov models," IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 799-810, 2011.
[2] A. Wrench, "A multichannel/multispeaker articulatory database for continuous speech recognition research," Phonus, vol. 5, pp. 3-17, 2000.
[3] F. Plante, G. Meyer, and A. Ainsworth, "A pitch extraction reference database," in Eurospeech, 1995, pp. 837-840.
[4] L. Lamel, R. Kassel, and S. Seneff, "Speech database development: Design and analysis of the acoustic-phonetic corpus," in Proceedings of the DARPA Speech Recognition Workshop, Report No. SAIC-86/1546, 1986.
[5] G. Pirker, M. Wohlmayr, S. Petrik, and F. Pernkopf, "A Pitch Tracking Corpus with Evaluation on Multipitch Tracking Scenario", Interspeech, pp. 1509-1512, 2011.
[6] M. Wu, D. Wang, and G. Brown, "A multipitch tracking algorithm for noisy speech," IEEE Transactions on Audio, Speech, and Language Processing, vol. 11, no. 3, pp. 229-241, 2003.
An Overview of Acoustic Modeling Techniques from ASRU 2011
Tara N. Sainath
SLTC Newsletter, January 2012
The Automatic Speech Recognition and Understanding Workshop (ASRU) was recently hosted in Hawaii from December 11-15, 2011. The conference included lectures and poster sessions in a variety of speech and signal processing areas. The Best Paper award was given to George Saon of IBM Research and Jen-Tzung Chien from National Taiwan University for their paper "Some Properties of Bayesian Sensing Hidden Markov Models", while the Student Best Paper award was given to Anton Ragni of Cambridge University for his paper "Derivative Kernels for Noise Robust ASR". In this article, some of the main acoustic modeling sessions at the conference are discussed in more detail.
Acoustic Modeling
The acoustic modeling session featured papers across a variety of topics, including Deep Belief Networks (DBNs), boosting, log-linear models, sparsity for acoustic models and conditional random fields (CRFs).
DBNs are explored on a large vocabulary 300 hour Switchboard task in Seide et al.. The paper specifically explores the effectiveness of different feature transforms, namely LDA, VTLN and fMLLR, when these transformed features are used as inputes into DBNs. The authors find that while applying HLDA and VTLN does not provide any improvements for deep networks, roughly a 4% relative improvement is seen with fMLLR-like transforms. In addition, the authors introduce a discriminative pre-training strategy. Overall, on different test sets, the best performing DNN offers between a 28% to 32% relative improvement over a baseline discriminatively-trained GMM system.
Tachibana et al. explores a boosting algorithm for a large vocabulary voice search task. The algorithm, known as Anyboost, trains an ensemble of weak learners using a discriminative objective function. The data used for training is weighted proportional to the sum of posterior functions from the previous round of weak learners. Results on a voice search task trained with different amounts of data between 150 to 5,000 hours show that the boosting method provides gains between 5.1% - 7.5% relative.
The problem of automatically generating articulatory transcripts of spoken utterances is explored in Prabhavalkar et al.. While research has become popular over the past few years, it has been limited by the lack of labeled articulatory data. Given the cost of manual transcriptions, the preferred methodology is to automatically generate transcripts. The authors explore a factored model of the articulatory state space and an explicit model of asynchrony of articulators. They show that CRFs, which are able to take advantage of task-specific constraints, offer between 2.2% and 10.0% relative improvements compared to a dynamic Bayesian network.
ASR Robustness
The session on ASR Robustness presented various noise robustness techniques for improving ASR performance.
Ragni et al. extends a recent research idea of combining generative and discriminative classifiers, where generative kernels are used in deriving features for discriminative models. The paper presents three main contributions, namely (1) using context-dependent generative models to derive derivative kernels; (2) incorporating derivative kernels into discriminative models; and (3) addresses the problem of feature dimensionality and large number of parameters for derivative kernels. On a small vocabulary Aurora 2 task, and a large vocabulary Aurora 4 task, the authors demonstrate that the proposed derivative kernel method offers improvements over other commonly used noise robustness techniques, including VTS.
Rennie et al. explores using a model-based noise robustness method, known as Dynamic Noise Adaptation (DNA), can be made more robust to matched data without having to do system retraining. Specifically, the authors explore performing online model selection and averaging between two a DNA noise model which tracks the background noise and a DNA noise model that models the null mismatch hypothesis. The proposed approach improves a strong speaker-adapted, discriminatively trained recognizer by 15% relative at signal-to-noise ratios (SNRs) below 10 dB, and over 8% relative overall.
Finally the use of addressing both speaker and environmental adaptation jointly is explored in Seltzer et al.. This joint adaptation is performed using a cascade of constrained maximum likelihood linear regression (CMLLR) transforms which separately compensate for both environmental and speaker variability. The authors also explore the use of unsupervised environmental clustering so that the proposed method did not require knowledge of the training and test environments ahead of time. The proposed algorithm achieves relative improvements between 10-18% over standard CMLLR methods.
References
F. Seide, G. Li, X. Chen, D. Yu, "Feature Engineering In Context-Dependent Deep Neural Networks For Conversational Speech Transcription," in Proc. ASRU, December 2011.
R. Tachibana, T. Fukuda, U. Chaudhari, B. Ramabhadran, and P. Zhan, "Frame-level AnyBoost for LVCSR with the MMI Criterion," in Proc. ASRU, December 2011.
R. Prabhavalkar, E. Fosler-Lussier and K. Livescu, "A Factored Conditional Random Field Model for Articulatory Feature Forced Transcription," in Proc. ASRU, December 2011.
A. Ragni and M.J.F. Gales, "Derivative Kernels for Noise Robust ASR," in Proc. ASRU, December 2011.
S.J. Rennie, P. Dognin and P. Fousek, "Matched-Condition Robust Dynamic Noise Adaptation," in Proc. ASRU, December 2011.
M.L. Seltzer and A. Acero, "Factored Adaptation for Separable Compensation of Speaker and Environmental Variability," in Proc. ASRU, December 2011.
If you have comments, corrections, or additions to this article,
please contact the author: Tara Sainath, tsainath [at] us [dot] ibm
[dot] com.
Tara Sainath is a Research Staff Member at IBM T.J. Watson Research Center in New York. Her research interests are mainly in acoustic modeling. Email: tsainath@us.ibm.com
Interview: AAAI Fall Symposium on Building Representations of Common Ground with Intelligent Agents
Matthew Marge
SLTC Newsletter, February 2012
In November, the AAAI Fall
Symposium on Building Representations
of Common Ground with Intelligent Agents gave researchers a chance to share their perspectives and recent work in building representations of common ground (i.e., the mutual information agents
have with the people they communicate with).
We interviewed the organizers about the workshop and their thoughts on common ground for intelligent
agents.
Overview
Perhaps you've heard the term common ground used in many different
facets of life - from international relations to friendly conversations. But have
you heard the term used as a way to explain how people communicate? Well, researchers
in artificial intelligence, robotics, computational linguistics, and psychology
theorize that for artificial agents to communicate effectively, they must build
common ground with their human counterparts.
The term "common ground" as used to explain human-human communication
was made popular by Herbert
H. Clark, Professor of Psychology at
Stanford University. Clark and his colleagues believe that a combination
of people's shared experiences, appearances, and behaviors can all be
part of the common ground two conversational partners share. For
artificial agents, the ability to learn word choices,
past interactions, and the environment (particularly the surroundings
the agent shares with a human partner) are all ways agents can build "common ground"
with people. The general idea is that an agent that can build common
ground with a person effectively will yield a better overall interaction
than one that does not. In speech and language technologies, applications
such as spoken dialogue systems and human-robot interaction (HRI) can
benefit from good representations of common ground.
In November, the AAAI Fall
Symposium on Building Representations
of Common Ground with Intelligent Agents gave researchers in fields
ranging from artificial intelligence, robotics, computational linguistics,
and psychology a chance to share their perspectives and recent work in common ground.
Organizing this meeting were Sam Blisard (Naval Research Laboratory),
Will Bridewell (Stanford Center for Biomedical Informatics Research),
Wende Frost (Naval Research Laboratory), Arthi Murugesan (Naval Research Laboratory),
Candace Sidner (Worcester Polytechnic Institute), and Alan Wagner (Georgia Tech Research Institute).
We asked three of the organizers about their perspectives on common ground and their
impressions from the workshop.
SLTC:What were the goals of the symposium?
Wende Frost:
My goal for the symposium was to get researchers from
different AI-related fields together to realize that they were
all using aspects of common ground, and to find useful methods
and ways of looking at the problem of common ground from the work of the other participants.
Arthi Murugesan:
To engage scientists from different fields (linguistics,
speech, robotics, human-computer interaction [HCI], AI and cognitive science)
in discussions of common ground with the aim of understanding its scope and
identifying common problems the researchers face.
SLTC:What is the definition of common ground as applied to intelligent agents?
Sam Blisard:
The concept of common ground is one of those all-encompassing ideas that can easily be described, yet putting it into practice is quite hard. To me, a succinct definition would be that common ground encompasses both the general knowledge needed to operate effectively in a given domain coupled with methods to learn new ideas and concepts in terms of the already known framework.
Wende:
Common ground is all of the information that both
participants in a dialogue share and use to adjust or calibrate their interactions accordingly.
SLTC:How does common ground apply to artificial intelligence?
Sam:
While concepts in the AI community could certainly be framed as
common ground or using it in some form, I think that it's more
applicable to intelligent agents and the HCI/HRI community due
to the sense of a collection of general knowledge and negotiating
to arrive at a shared knowledge base that enables interaction.
Wende:
To me, there is little difference in how humans use common ground now and how we would hope that intelligent agents will someday use common ground. It depends upon the function of the agent, of course, but any agent that interacts with a human should eventually take into account their previous interactions with the person, what background knowledge of the world both the agent and the human have, and what mutual beliefs the person and the agent share.
SLTC:How did the idea for a symposium on common ground representations for intelligent agents come about?
Arthi:
The symposium was mostly inspired by Herbert Clark's ideas and our recent work on creating cognitive models of context-based interactions. Also, through different conversations with the symposium's organizing committee members, Sam, working on spatial language interactions, and Alan, working on mendacity, we came to realize that common ground was a broad topic of interest.
Wende:
I've been interested in breaking down and implementing the component aspects of Herbert Clark's common ground for some time, so a symposium where the ongoing work of other researchers in common ground could be highlighted seemed like it had potential to be very interesting.
Sam:
Mainly from discussions of common ground motivated by Herbert Clark's book at NRL (Naval Research Laboratory). It seemed like it'd be a fun track to have for the AAAI fall symposium.
Impressions and Lessons Learned
SLTC:Would you consider the symposium a success? What do you think attendees learned most?
Sam:
I would. We were exposed to several researchers and cutting edge work on common ground and the grounding problem. I think the biggest thing is that common ground cannot be accomplished with one approach at this stage of the game (with the exception of some toy problems). I know it's cliche, but consider the classic T-800 Terminator. It must operate in an open world, be able to conduct detective work, be deceptive, and adapt/improvise/overcome crippling malfunctions of its own systems to complete its mission. Any one of these problems is exceptionally difficult and has an aspect of common ground in it (some more so than others) - perhaps it's best to consider common ground a way to frame problems rather than a solution in and of itself (as an aside, that's some pretty meta-stuff right there ;-) ).
Wende:
I would consider the symposium a success, and I would guess the overall theme that most participants came away with was that common ground is a huge, unimplemented problem, and much of the existing work may have been done in a field other than the one they might expect.
SLTC:What were your impressions from the discussion session we had? What are promising avenues for building intelligent agents that use common ground? (particularly those that speech and language researchers should consider)
Sam:
I think the biggest thing one should consider from a speech/linguistics standpoint is how to ask the right question to increase an agent's knowledge in a meaningful way. This could involve detecting benign ignorance or outright deception, where a better place to do "science" is in a hostile environment based on previous observations, or something similar. Just collecting data is fine, but it'd be a lot more impressive if it's done in a manner that maximizes the agent's performance.
Arthi:
One of my impressions from the discussions is that the need to build intelligent agents that use common ground will grow, as the interactions they are expected to participate in become more complex. I think this will also be the case for speech and language systems that interact with users.
Wende:
I think that some of the most obvious places to use common ground today are tutoring, training, and aid systems. I think the main challenges in this domain at this point are identifying and defining the components of common ground, followed by making sure that any implementation of these components works in the overall framework of the theory, rather than as a cluster of disparate, non-interactive applications. Personally, a component I find fascinating is the concept of joint salience, and how humans recognize different items and concepts as being salient in different situations.
SLTC:One last question -- What do you foresee as the future application areas for common ground with intelligent agents over the next 5 or 10 years?
Sam:
I'm not about to make some grandiose claim about passing the Turing test. What I will say is that common ground is an important framework/concept that researchers in the intelligent agent and allied fields need to consider, especially if their research is going to be interacting with other agents (human or otherwise). I think it's a very useful way of grouping a large collection of problems that need to be dealt with; however, in some ways it's kind of like trying to find the infamous ghost in the machine. Finally, I think the most important thing is that 5 or 10 years from now...our agents are acting more intelligently and that common ground is a helpful idea to aid in reaching that goal.
Thanks to Sam, Wende, and Arthi for their thoughtful answers! We look forward to hearing how common ground will impact intelligent agents in the near future.
If you have comments, corrections, or additions to this article, please contact the author: Matthew Marge, mrma...@cs.cmu.edu.
WordsEye - from Text to Image
Svetlana Stoyanchev
SLTC Newsletter, February 2012
Wordseye is a software that generates 3-dimensional graphical scenes.
Unlike 3d Max or Maya, Wordseye's input is plain text. The idea behind this project is to create scenes in a very quick manner by simply describing what you want to see in a scene.
Overview
When reading fiction (or non-fiction), we often use our imagination to visualize described scenes in our minds, creating vivid images from textual narration.
WordsEye aims to do something similar to that.
The goal of WordsEye "is to provide a blank slate
where the user can literally paint a picture with words, where the
description may consist not only of spatial relations, but also actions performed by objects in the scene"[1].
Richness and expressiveness of natural language allows for description of complex and dynamic scenes. However, textual scene descriptions are often vague and underspecified, leaving many details, such as background of a scenes, relative positioning, sizes, and colours of objects, up to the reader's imagination. For example, a description "a person is sitting at a table and reading a book" evokes a visual scene which is based on our knowledge of positioning of a chair with respect to a table, a sitting pose of a person, a person's gaze towards a book.
Although these specifics are absent from the textual description, they will be common in imagination of different people. When imagining a scene, we complete these details based on our background and common knowledge of the world.
When creating images automatically, the under-specified details have to be reconstructed by the system. WordsEye uses existing semantic resources including WordNet and FrameNet. In addition, the authors are also creating a new theory and lexical resource called VigNet[2]. VigNet records world knowledge depicting distinction between variants of relations based on their attributes. This world knowledge is then used when generating visual presentation of these relations.
How it works
In order to generate an image, the software has to understand natural language text.
Input text is parsed and converted to semantics. Nouns are mapped to objects that correspond to 3D objects available in the objects library. Verbs, adjectives, and prepositions get mapped to semantic relations that represent, for example, object's location, colour, or material.
Semantic presentation is then generated in the form of graphical objects in a 3D scene.
WordsEye uses a library of 3D models with approximately 2000 different objects, including household items such as tables, chairs, animals, as well as other less usual objects such as dragons or statues.
The software interprets spatial language and other low-level graphical relations in the input text. For example, "the cat is on the table" creates an image a cat on top of a table.
Different versions of cat and table object may be selected by a user.
A user may add colours, textures, and lighting to the scene.
Using the software
Creating images from text is a fun experience, images appear following your thoughts as they would in your imagination. It does require some learning in figuring out natural language expressions that would give you desirable result. This learning can often be done by example, by looking at other images with desired effects and adopting their syntax or vocabulary.
WordsEye website has been running for 6 years. It is being used by 7000 users who have created over 10,000 images. Some generated images are surreal and fairy-tale-like and make you think of Alice in Wonderland or Dali's paintings.
WordsEye has also been piloted in an educational setting where it helped 6-graders enhance their essay writing skills through the use of the software[3].
Questions to one of the WordsEye's Creator Bob Coyne
We have asked Bob Coyne, the creator of WordsEye (in collaboration with Richard Sproat) about current research directions of the project.
Q: Theatre set descriptions seem to be very suitable for automatic scene generation. For example from Chehov's Uncle Vanya:
"A country house on a terrace. In front of it a garden. In an avenue of trees, under an old poplar, stands a table set for tea, with a samovar, etc. Some benches and chairs stand near the table. On one of them is lying a guitar. A hammock is swung near the table. It is three o'clock in the afternoon of a cloudy day."
How far are you from generating images using such flexible language and what in your view are the main challenges?
Bob: Something like that is certainly in the realm of possibility and represents the type of language the system is designed to handle as well as some of the key issues we're currently working on. For example, the current system is unable to depict words (e.g., for locations like garden) that denote arrangements of multiple objects. Other compound object relations, such as table set for tea, also pose a problem and would involve interpreting and translating a multiword description into a situation-specific configuration (what we call vignettes). Another challenge (e.g., in hammock is swung) is that except for poses and facial expressions, WordsEye only deals with rigid 3D objects. This is especially important when processing descriptions of how people are dressed, where clothing must conform to the person wearing it. And this is also an issue when describing the shape of a particular object or its parts (e.g., chair with a high curved back). In fact, even for single word or simple multiword nominals (eg samovar, country house, old poplar), we won't always have a 3D object corresponding to the specified type of entity or be able to modify an existing object by changing its shape or style. So all these cases would be covered by a fallback strategy where we instead use a closely related object (e.g. samovar - urn or kettle), or just drop the modifier and use a more generic form (country house - house; old poplar - poplar). Other aspects of the Uncle Vanya example, such as Time of day and cloudiness are both depictable in the current system, though the variation of language specification for that hasn't been extensively fleshed out. And some aspects (e.g. near the table) are handled as-is. And of course there are many other issues, such as PP-attachment disambiguation, word sense disambiguation, etc. But, overall, I think the Checkov description represents type type of low-level descriptions the system should eventually be able to handle given the work we are doing to flesh out the system (such as adding support for words that denote arrangements of multiple objects) and a robust set of fallback strategies.
Q: A user can currently specify "low-level" graphical relations of the scene. Can you describe the direction that you are currently working on?
Bob:
Any given scene can usually be described in a couple very different ways. What we call low-level language can be used to describe what the scene looks like. This will include spatial relations between objects, surface properties like color and texture, poses and facial expressions of humans, etc. Low-level language can conceptually be mapped into graphical objects and a limited set of graphical constraints -- as exemplified by the Chekov example. In contrast, high-level language describes not what a scene looks like but what event or state-of-affairs is represented by the scene. For example, if you say "wash an apple" you might expect to see a person holding an apple and standing in front of a sink. However, "wash the floor" might imply a person kneeling on the floor and holding a sponge. And "washing a car": might involve being outside on a driveway and holding a hose and pointing it at the car. The high level semantics is basically the same -- an object is being washed, but the low-level semantics are very different. The mappings between high-level semantics and low-level semantics (i.e. standard ways of doing things or common configurations of objects) are what we call vignettes. It might seem that there are an unbounded number of vignette types, but if you examine the actual structure of visual scenes, you'll notice that a limited set of structures are repeat again and again -- it's mostly the mapping between vignettes and high-level semantics that varies. For example, cutting carrots and writing on a piece of paper are structurally very similar -- both involve the same vignette type of applying a hand-held instrument (knife or pencil) to a patient (carrot or piece of paper) that is resting on a horizontal work surface (kitchen counter or desk).
Q: How do you see WordsEye system used in the future?
Bob:
I think WordsEye (and text-to-scene generation more generally) has tremendous potential in several application areas. We recently performed a controlled experiment using WordsEye as a tool to enhance literacy skills in a middle school summer enrichment program at Harlem Educational Activities Fund. Students using it showed significantly greater growth in a pre- and post- test test in writing and literary response compared to students in a control group. We're planning to apply it next to English Language Learners. Another potential area is social media, where the speed and ease of creating pictures can empower people to express themselves not just by what they write but by the pictures they create. We're also experimenting with using WordsEye to automatically visualize existing text -- in particular with Twitter to see if some percentage of Tweets can be automatically turned into pictures. A third, very interesting potential application area is in 3D games where language could be used in the gameplay itself to change and interact with the environment. Games are increasingly allowing more in-game variation of the graphical content, and using natural language would provide an exciting new way to do that.
Acknowledgements
Participants in the WordsEye project at Columbia University include
Richard Sproat, Owen Rambow, Julia Hirschberg, Daniel Bauer, Masoud
Rouhizadeh, Morgan Ulinski, Margit Bowler, Jack Crawford, Kenny Harvey,
Alex Klapheke, Gabe Schubiner, Cecilia Schudel, Sam Wiseman, Mi Zhou,
Yen-Han Lin, Yilei Yang, and Victor Soto. This project is supported by a
grant from the National Science Foundation, IIS-0904361.
References
[1] B. Coyne and R. Sproat. WordsEye: An automatic text-to-scene conversion system. In SIGGRAPH Proceedings of the Annual Conference on Computer Graphics, 2001.
[2] B. Coyne, O. Rambow, J. Hirschberg, and R. Sproat. Frame Semantics in Text-to-Scene Generation. In Proceedings of the KES'10 workshop on 3D Visualisation of Natural Language, 2010.
[3] B. Coyne, C. Schidel, M. Bitz, and J. Hirschberg Evaluating a Text-to-Scene Generation System as an Aid to Literacy In Proceedings of ISCA workshop on Speech and Language Technology in Education 2011
If you have comments, corrections, or additions to this article, please contact the author: Svetlana Stoyanchev, sstoyanchev [at] cs [dot] columbia [dot] edu.
Svetlana Stoyanchev is a Postdoctoral Research Fellow at Columbia University. Her interests are in dialog and information presentation.
The Kaldi Speech Recognition Toolkit
Arnab Ghoshal and Daniel Povey
SLTC Newsletter, February 2012
Kaldi is a free open-source toolkit for speech recognition research. It is written in C++ and provides a speech recognition system based on finite-state transducers, using the freely available OpenFst, together with detailed documentation and scripts for building complete recognition systems. The tools compile on commonly used Unix-like systems and on Microsoft Windows. The goal of Kaldi is to have modern and flexible code that is easy to understand, modify, and extend. Kaldi is released under the Apache License v2.0, which is highly nonrestrictive, making it suitable for a wide community of users. Kaldi is available from SourceForge.
Why another speech toolkit?
The work on Kaldi [1] started during the 2009 Johns Hopkins University summer workshop project titled "Low Development Cost, High Quality Speech Recognition for New Languages and Domains," where we were working on acoustic modeling using subspace Gaussian mixture model (SGMM) [2]. In order to develop and test a new acoustic modeling technique, we needed a toolkit that was simple to understand and extend; had extensive linear algebra support; and came with a nonrestrictive license that allowed us to share our work with other researchers in academia or industry. We also preferred to use a finite-state transducer (FST) based framework.
While there were several potential choices for open-source ASR toolkits -- for example, HTK, Julius (both written in C), Sphinx-4 (written in Java), and the RWTH ASR toolkit (written in C++, and closest to Kaldi in terms to design and features) -- our specific requirements meant that we had to write many of the components, including the decoder, by ourselves. Given the amount of effort invested and the continued use of the tools following the JHU workshop, it was a logical choice to extend the codebase into a full-featured toolkit. We had two follow-up summer workshops at the Brno University of Technology, Czech Republic, in 2010 and 2011, and further development of Kaldi is ongoing.
Design of Kaldi
Important aspects of Kaldi include:
Integration with Finite State Transducers: We compile against the OpenFst toolkit (using it as a library).
Extensive linear algebra support: We include a matrix library that wraps standard BLAS and LAPACK routines.
Extensible design: We attempt to provide our algorithms in the most generic form possible. For instance, our decoders work with an interface that provides a score for a particular
frame and FST input symbol. Thus the decoder could work from any suitable source of scores.
Open license: The code is licensed under Apache v2.0, which is one of the least restrictive licenses available.
Complete recipes: We make available complete recipes for building state-of-the art speech recognition systems, that work from widely available databases such as those provided by the Linguistic Data Consortium (LDC).
Thorough testing: The goal is for all or nearly all the code to have corresponding test routines.
Kaldi has an open and distributed development model, with a growing community of users and contributors. The original authors moderate contributions to the project.
Features Supported in Kaldi
We intend Kaldi to support all commonly used techniques in speech recognition. The toolkit currently supports:
MFCC and PLP front-end, with cepstral mean and variance normalization, LDA, STC/MLLT, HLDA, VTLN, etc.
Modeling of context-dependent phones of arbitrary context lengths.
HMM/GMM acoustic models; phonetic decision trees.
Semi-continuous hidden Markov models [4].
Subspace Gaussian mixture models [2].
Speaker adaptation and adaptive training.
WFST-based decoders with lattice generation [3].
Lattice rescoring with acoustic and language models.
Discriminative training with MMI, boosted MMI (fMPE under development).
There is currently no language modeling code, but we support converting ARPA format LMs to FSTSs. In the recipes released with Kaldi, we use the freely available IRSTLM toolkit. However, one could potentially use a more fully-featured toolkit like SRILM. Current strands of development include: discriminative training with MPE, interface for transparent computation on CPUs and GPUs, hybrid ANN/HMM systems, etc.
Acknowledgements
The contributors to the Kaldi project are: Gilles Boulianne, Lukas Burget, Arnab Ghoshal, Ondrej Glembek, Nagendra Goel, Mirko Hannemann, Navdeep Jaitly, Stefan Kombrink, Petr Motlicek, Daniel Povey, Yanmin Qian, Korbinian Riedhammer, Petr Schwarz, Jan Silovsky, Georg Stemmer, Karel Vesely, and Chao Weng.
We would like to thank Michael Riley, who visited us in Brno to deliver lectures on finite state transducers and helped us understand OpenFst; Henrique (Rico) Malvar of Microsoft Research for allowing the use of his FFT code; and Patrick Nguyen for help with WSJ recipes and introducing the participants in the JHU workshop of 2009. We would like to acknowledge the help with coding and documentation from Sandeep Boda and Sandeep Reddy (sponsored by Go-Vivace Inc.) and Haihua Xu. We thank Pavel Matejka (and Phonexia s.r.o.) for allowing the use of feature processing code.
We would like to acknowledge the support of Geoffrey Zweig and Alex Acero at Microsoft Research, and Dietrich Klakow at Saarland University. We are grateful to Jan (Honza) Cernocky for helping us organize the workshop at the Brno University of Technology during August 2010 and 2011. Thanks to Tomas Kasparek for system support and Renata Kohlova for administrative support.
Finally, we would like to acknowledge participants and collaborators in the 2009 Johns Hopkins University Workshop, including Mohit Agarwal, Pinar Akyazi, Martin Karafiat, Feng Kai, Ariya Rastrow, Richard C. Rose and Samuel Thomas; and faculty and staff at JHU for their help during that workshop, including Sanjeev Khudanpur, Desiree Cleves, and the late Fred Jelinek.
References
[1] D. Povey, A. Ghoshal, et al., "The Kaldi Speech Recognition Toolkit," in IEEE ASRU, 2011.
[2] D. Povey, L. Burget et al., "The subspace Gaussian mixture model--A structured model for speech recognition," Computer Speech & Language, 25(2), pp. 404-439, April 2011.
[3] D. Povey, M. Hannemann, et al., "Generating Exact Lattices in the WFST Framework," in IEEE ICASSP, 2012 (to appear).
[4] K. Riedhammer, T. Bocklet, A. Ghoshal and D. Povey, "Revisiting Semi-Continuous Hidden Markov Models," in IEEE ICASSP, 2012 (to appear).
Arnab Ghoshal is a Research Associate at The University of Edinburgh. Email: a.ghoshal@ed.ac.uk
Daniel Povey is an Associate Research Scientist at The Johns Hopkins University Human Language Technology Center of Excellence. Email: dpovey@gmail.com
The INTERSPEECH 2011 Speaker State Challenge - a review
Björn Schuller, Stefan Steidl, Anton Batliner, Florian Schiel, and Jarek Krajewski
SLTC Newsletter, February 2012
The INTERSPEECH 2011 Speaker State Challenge was held in conjunction with INTERSPEECH 2011 in Florence, Italy, 28-31 August 2011. This Challenge was the first open evaluation of speech-based speaker state recognition systems aimed at mid-term speaker states - in this case intoxication and sleepiness. 18 teams participated, previous results were outperformed, and a new reference feature set and corpora were used and are available.
Overview
The INTERSPEECH 2011 Speaker State Challenge was organised by Björn Schuller (TUM, Germany), Stefan Steidl (ICSI, USA), Anton Batliner (FAU, Germany), Florian Schiel (University of Munich, Germany), and Jarek Krajewski (University of Wuppertal, Germany). The Challenge was aimed at mid-term speaker states, which can be contrasted with short-term states such as emotion or interest, and long-term traits such as age or gender.
The mid-term speaker states here were intoxication and sleepiness. As in the first three Challenges organised by previous organisers starting with INTERSPEECH 2009, strict comparability was given: the German Alcohol Language Corpus (provided by the Bavarian Archive for Speech Signals) and the Sleepy Language Corpus both involved speakers who were actually affected by either alcohol intoxication or sleep deprivation. These corpora served as clearly defined test, training, and development partitions incorporating speaker independence as needed in most real-life settings.
The 2011 Speaker State Challenge addressed two Sub-Challenges, each using two classes for classification (above or below a threshold). In the first Sub-Challenge, alcoholisation of speakers had to be determined from acoustics for blood alcohol concentration (BAC) exceeding 0.5 per mill. However, in the training and development partition the actual BAC from 0.28-1.75 per mill was also provided. This information could be used for model construction or for reporting of more precise results in papers submitted about the development partition.
In the Sleepiness Sub-Challenge, the sleepiness of speakers had to be determined for a level exceeding level 7.5 on the Karolinska Sleepiness Scale, reaching from one (extremely alert) to 10 (cannot stay awake).
A new set of 4,368 acoustic features per speech chunk, again computed with TUM's openSMILE toolkit, was provided by the organisers. This set was based on 60 low level descriptors that could be extracted on the frame level by a script provided by the organisers. These features could be used directly or sub-sampled, altered, etc., and combined with other features.
As in the 2009 and 2010 Challenges, the labels of the test set were unknown, and all learning and optimisations needed to be based only on the training material. However, each participant could upload instance predictions to receive the confusion matrix and results up to five times. The format was instance and prediction, and optionally additional probabilities per class. This allowed a final fusion of all participants' results, to demonstrate the potential maximum by combined efforts. As classes were unbalanced, the primary measure to optimise was unweighted accuracy (UA), i.e., unweighted average recall. The choice of unweighted average recall was a necessary step to better reflect imbalance of instances among classes as often given in real-world paralinguistic recognition. Other well-suited and interesting measures were considered; however, these are either not yet common measures in the field or did not fit the evaluation paradigm.
The organisers did not take part in the Sub-Challenges but provided baselines built using the WEKA toolkit as a standard-tool so that the results were reproducible. Support Vector Machines were chosen for classification and optimised on the development partition, and the 2011 openSMILE feature set outperformed the previous ones on these tasks. The baselines were 65.9% UA (intoxication) and 70.3% UA (sleepiness) with a chance level of 50%.
All participants were encouraged to compete in both Sub-Challenges and each participant had to submit a paper to the INTERSPEECH 2011 Speaker State Challenge Special Event. The results of the Challenge were presented in a Special Event of INTERSPEECH 2011 (double session) and the winners were awarded in the closing ceremony by the organisers. Two prizes (each 250.- GBP sponsored by the HUMAINE Association) could be awarded following the pre-conditions that the accompanying paper needed to be accepted to the special event following the INTERSPEECH 2011 general peer-review, that the provided baseline was exceeded, and that a best result in a Sub-Challenge was reached. Overall, 34 sites registered for the Challenge, and 12 papers were accepted for presentations.
Results
The Intoxication Sub-Challenge Prize was awarded to Daniel Bone, Matthew P. Black, Ming Li, Angeliki Metallinou, Sungbok Lee, and Shrikanth S. Narayanan (Signal Analysis and Interpretation Laboratory (SAIL), University of Southern California, Los Angeles) who reached 70.5% UA in their contribution "Intoxicated Speech Detection by Fusion of Speaker Normalized Hierarchical Features and GMM Supervectors".
The Sleepiness Sub-Challenge Prize was awarded to Dong-Yan Huang, Shuzhi Sam Ge, and Zengchen Zhang (Institute for Infocomm Research/A*STAR, Singapore) who reached 71.7% UA in their contribution "Speaker State Classification Based on Fusion of Asymmetric SIMPLS and Support Vector Machines".
Overall, the results of all 18 uploading groups were mostly very close to each other, and significant differences between the results accepted for publication were as seldom as one might expect in such a close competition. However, by late "democratic" fusion of participants' results, new baselines exceeding all individual results could be established: 72.2% UA and 72.5% UA recall for the intoxication and sleepiness tasks. The general lesson learned thus again is "together we are best": Obviously, the different feature representations and learning architectures contribute an added value, when combined. In addition, the Challenge clearly demonstrated the difficulty of dealing with a real-life intoxication and sleepiness recognition scenario - this challenge remains.
The corpora used for the Challenge (ALC, SLC) can be obtained from the owners of the databases. The follow-up to the 2011 Speaker State Challenge is the 2012 Speaker Trait Challenge, which is on-going at the time of writing. It focuses on "perceived" speaker traits - again for the first time in such a public and well-regulated comparative evaluation, featuring the tasks Personality, Likability, and Pathology.
For more information on the 2011 Speaker State Challenge, see the webpage on emotion-research.net.
Björn Schuller is Senior Lecturer at Technische Universität München. His main interests are Computational Paralinguistics and Audio Pattern Recognition. Email: schuller@tum.de
Stefan Steidl is Researcher at the International Computer Science Institute Berkley. His main interest is Affective Speech Analysis. Email: steidl@ICSI.Berkeley.edu
Anton Batliner is Senior Researcher at Friedrich-Alexander-Universität Erlangen-Nürnberg. His main interests are Computational Paralinguistics and Phonetics. Email: batliner@informatik.uni-erlangen.de
Florian Schiel is Senior Researcher at the University of Munich and CEO for BAS Services. His main interests are Phonetics and speech resources. Email: schiel@phonetik.uni-muenchen.de
Jarek Krajewski is Professor at the University of Wuppertal. His main interests are Fatigue Detection and Pattern Recognition. Email: krajewsk@uni-wuppertal.de
Book Review: Stephen Ramsay's "Reading Machines: Toward an Algorithmic Criticism"
Antonio Roque
SLTC Newsletter, February 2012
Stephen Ramsay's book "Reading Machines: Toward an Algorithmic Criticism" provides a humanist's perspectives on computational text analysis as disruptive and performative.
As language technologists we are familiar with coordinating ideas from a variety of disciplines. One discipline that has not yet had much effect on language processing is literary critical theory, such as that developed and practiced in English departments. In part this is because critical theorists are still dealing with the question of exactly how they should be using computers in their work. Ramsay's book hints at the sorts of contributions to computational text analysis that critical theory may one day provide, and in doing so suggests some limitations of the interpretative power of contemporary language technology.
The book's focus is on literary text analysis, which involves close readings by humans of aesthetic written works. This is contrasted with that research in the digital humanities driven by empirical and computational approaches, such as authorship attribution and Roberto Busa's seminal concordances. In empirical digital humanities work, the meaning of a work is assumed to be "knowable and recoverable" and literary questions can be definitively answered. But to many literary critics (from New Critics to Post-Structuralists), authorial intention is not the sole source of textual meaning; in fact, textual interpretation is seen as highly subjective. Ramsay discusses this through the application and interpretation of tf-idf to sets of chapters in Virginia Woolf's The Waves. Ramsay argues that "literary critical arguments... do not stand in the same relationship to facts, claims, and evidence as the more empirical forms of inquiry."
Instead, Ramsay proposes to use computers as tools to "channel the heightened objectivity made possible by the machine into the cultivation of those heightened subjectivities necessary for critical work." He describes a relevant tradition beginning with the 'pataphysics of Alfred Jarry, in which Absurdist narrative is used to imagine the possibilities of scientific realities. This evolves into the mathematically-inspired literature and poetry of Oulipo, in which constraints are used to re-think genres and generate new works. This leads to the algorithmic criticism of the book title, which "attempts to employ the rigid, inexorable, uncompromising logic of algorithmic transformation as the constraint under which critical vision may flourish." This is related to the critical approaches of Jerome McGann and Lisa Samuels, in which the order of lines of poetry are manipulated as "a way of unleashing the potentialities that altered perspectives may reveal" and the entropic poems of Estelle Irazarry in which words and word counts are read in the order the words first appear in the poem. This is criticism as both an artistic performance in its own right, and a deforming of the original text, hence McGann and Samuels' term deformance. Ramsay further discusses this approach in the context of the performative nature of I Ching readings, conjectural research by Ferdinand de Saussure on the structure of pre-classical Latin poetry, and the subjectivity required in interpreting the medieval Anglo-Saxon poem "The Wife's Lament." After discussing subjectivity in the Turing Test and ELIZA, Ramsay continues by describing several humanities tools and projects (WordHoard, TAPoR, HyperPo, and MONK) and the ways in which they could be used for algorithmic criticism.
Clearly this book is presenting an argument directed towards humanists, so as language technologists we might initially approach it with suspicion. We might tell ourselves that meaningful symbols are obviously represented in a human's brain, that our programs try to identify that meaning whether transmitted through text or speech, and that everything else is noise. From this perspective, Ramsay's book is a fun set of stories about research that is more artistic and philosophical than we need, and by its own admission not directly relevant to the concerns of scientists and engineers.
And yet it can be difficult to ignore Ramsay's statement that from a humanist's perspective, "Tools that can adjudicate the hermeneutical parameters of human reading experiences - tools that can tell you whether an interpretation is permissible - stretch considerably beyond the most ambitious fantasies of artificial intelligence." Are our fantasies really that impoverished? It seems that we could cobble together something of that sort from research in language as complex adaptive systems, computational models of culture, societal grounding, semantic alignment, embodied symbol grounding, and user modeling, along with more mainstream AI/CL/NLP techniques. Given a text and models of reader and culture, we could then computationally predict what interpretations are likely to be performed by humans over various reader/culture distributions.
It may seem odd to consider such issues when we already have so many interesting and profitable tasks at hand, but providing such perspectives is a benefit of interdisciplinary research. Ramsay's text analysis is of a humanist nature: "The goal... is not to arrive at the truth, as science strives to do. In literary criticism, as in the humanities more generally, the goal has always been to arrive at the question." Language technology is conducting research on increasingly sophisticated domains, as indicated by recent AI/CL workshops in computational creativity and computational linguistics for literature. Familiarity with the questions posed by literary theorists and other humanists is likely to contribute to these research directions.
Audio and Acoustic Signal Processing Challenges Launch 2012
Patrick A. Naylor
SLTC Newsletter, February 2012
The IEEE Technical Committee for Audio and Acoustic Signal Processing (AASP) will be launching a `Challenges' activity in order to encourage research and development with comparable and repeatable results, and to stimulate new ground-breaking approaches to specific problems in the AASP technical scope.
It's interesting to ask why audio and acoustic signal processing researchers have not so far engaged in common evaluations and competitions. Such evaluation activities have been embraced in other communities including, with notable success, speech processing. With some slight hesitancy, I offer the explanation that perhaps the evaluation of AASP algorithms is often not at all straightforward and almost always multidimensional. This is in part at least due to the need to measure things related to human perception and experience. Those objective metrics that are actually defined may be context specific and inappropriate for universal application. The next consideration is the data. Accessible and comprehensively available datasets have undoubtedly had a hugely beneficial impact on speech processing development and benchmarking. At the present time, the situation in AASP is much more fragmented and few, if any, standard datasets exist for many important AASP tasks.
This new initiative, promoted by the AASP Technical Committee, aims to address these issues. Known as `AASP Challenges', tasks will be defined with appropriate datasets and evaluation methodologies. Researchers will then be able to participate in Challenges and comparative evaluations will follow. The AASP challenges will inherit features from other competitions and challenges including NIST evaluations, the MIREX framework and the Chime Challenge.
In the current plan for Challenges, the scheme's success will depend on pro bono efforts of corporations and universities. We are all hopeful that, with some good will and guidance from the IEEE, the idea will gain traction and, eventually, catch the interest of the broader community.
The first Call for Challenges is published on the IEEE AASP TC Website. The Challenges will be overseen by a subcommittee of the AASP TC involving representatives from industry and academia and spanning the disciplines of audio, music and acoustic signal processing.
For further details: http://www.signalprocessingsociety.org/technical-committees/list/audio-tc/aasp-challenges/.
Patrick A. Naylor is Reader in Speech and Audio Signal Processing at Imperial College London. Email: p.naylor@imperial.ac.uk

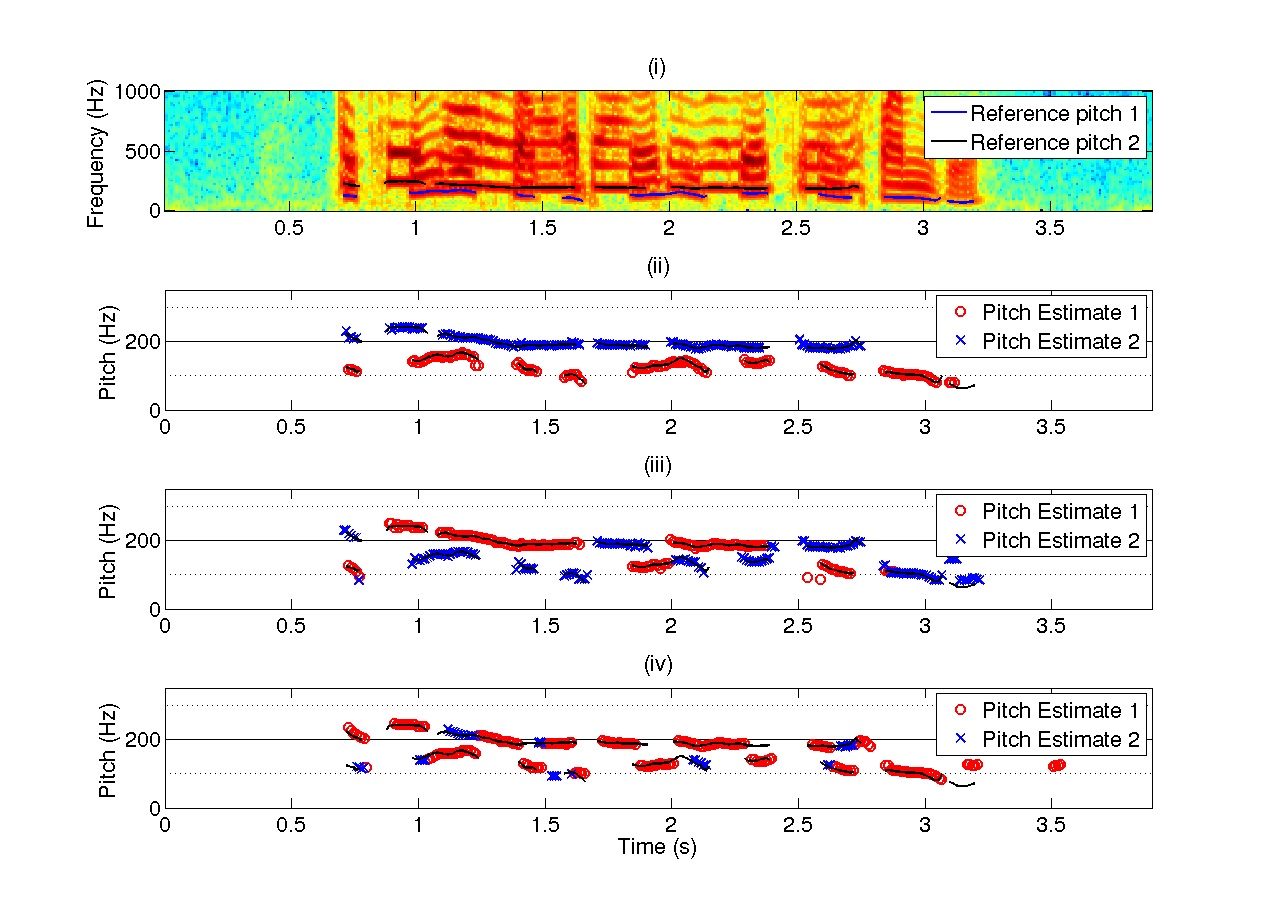
 When reading fiction (or non-fiction), we often use our imagination to visualize described scenes in our minds, creating vivid images from textual narration.
WordsEye aims to do something similar to that.
The goal of WordsEye "is to provide a blank slate
where the user can literally paint a picture with words, where the
description may consist not only of spatial relations, but also actions performed by objects in the scene"[1].
When reading fiction (or non-fiction), we often use our imagination to visualize described scenes in our minds, creating vivid images from textual narration.
WordsEye aims to do something similar to that.
The goal of WordsEye "is to provide a blank slate
where the user can literally paint a picture with words, where the
description may consist not only of spatial relations, but also actions performed by objects in the scene"[1].



