
Welcome to the Winter 2013-2014 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter! This issue of the newsletter includes 7 articles and announcements from 25 contributors, including our own staff reporters and editors. Thank you all for your contributions! This issue includes news about IEEE journals and recent workshops, SLTC call for nominations, and individual contributions.
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions.
To subscribe to the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Dilek
Hakkani-Tür, Editor-in-chief
William Campbell, Editor
Haizhou Li, Editor
Patrick Nguyen, Editor
SLaTE 2013 was the 5th workshop organised by the ISCA Special Interest Group on Speech and Language Technology for Education. It took place between 30th August and 1st September 2013 in Grenoble, France as a satellite workshop of Interspeech 2013. The workshop was attended by 68 participants from 20 countries. Thirty eight submitted papers and 14 demonstrations were presented in oral and poster sessions.
The INTERSPEECH 2013 Computational Paralinguistics Challenge was held in conjunction with INTERSPEECH 2013 in Lyon, France, 25-29 August 2013. This Challenge was the fifth in a series held at INTERSPEECH since 2009 as an open evaluation of speech-based speaker state and trait recognition systems. Four tasks were addressed, namely social signals (such as laughter), conflict, emotion, and autism. 65 teams participated, the baseline as was given by the organisers could be exceeded, and a new reference feature set by the openSMILE feature extractor and the four corpora used are publicly available at the repository of the series.
The goal of the Babel program is to rapidly develop speech recognition capability for keyword search in previously unstudied languages, working with speech recorded in a variety of conditions with limited amounts of transcription. Several issues and observations frame the challenges driving the Babel Program. The speech recognition community has spent years improving the performance of English automatic speech recognition systems. However, applying techniques commonly used for English ASR to other languages has often resulted in huge performance gaps for those other languages. In addition, there are an increasing number of languages for which there is a vital need for speech recognition technology but few existing training resources [1]. It is easy to envision a situation where there is a large amount of recorded data in a language which contains important information, but for which there are very few people to analyze the language and no existing speech recognition technologies. Having keyword search in that language to pick out important phrases would be extremely beneficial.
We are happy to announce the release of the MSR Identity Toolbox: A MATLAB toolbox for speaker-recognition research. This toolbox contains a collection of MATLAB tools and routines that can be used for research and development in speaker recognition. It provides researchers with a test bed for developing new front-end and back-end techniques, allowing replicable evaluation of new advancements. It will also help newcomers in the field by lowering the "barrier to entry," enabling them to quickly build baseline systems for their experiments. Although the focus of this toolbox is on speaker recognition, it can also be used for other speech related applications such as language, dialect, and accent identification. Additionally, it provides many of the functionalities available in other open-source speaker recognition toolkits (e.g., ALIZE [1]) but with a simpler design which makes it easier for the users to understand and modify the algorithms.
The Dialog Research Center at Carnegie Mellon (DialRC) is organizing the REAL Challenge. The goal of the REAL Challenge (dialrc.org/realchallenge) is to build speech systems that are used regularly by real users to accomplish real tasks. These systems will give the speech and spoken dialog communities steady streams of research data as well as platforms they can use to carry out studies. It will engage both seasoned researchers and high school and undergrad students in an effort to find the next great speech applications.
The Workshop on Speech Production in Automatic Speech Recognition (SPASR) was recently held as a satellite workshop of Interspeech 2013 in Lyon on August 30.
The field of speaker recognition has evolved significantly over the past twenty years, with great efforts worldwide from many groups/laboratories/universities, especially those participating in the biannual U.S. NIST SRE - Speaker Recognition Evaluation [1]. Recently, there has been great interest in considering the ability to perform effective speaker identification when speech is not produced in "neutral" conditions. Effective speaker recognition requires knowledge and careful signal processing/modeling strategies to address any mismatch conditions that could exist between the training and testing conditions. This article considers some past and recent efforts, as well as suggested directions when subjects move from a "neutral" speaking style, vocal effort, and ultimately pure "screaming" when it comes to speaker recognition. In the United States recently, there has been discussion in the news regarding the ability to accurately perform speaker recognition when the audio stream consists of a subject screaming. Here, we illustrate a probe experiment, but before that some background on speech under non-neutral conditions.
SLTC Newsletter, November 2013
Welcome to the final SLTC Newsletter of 2013.
I am pleased to announce the results of this year's election to renew the membership of the SLTC. We elected 17 members to replace the 17 members whose term expires next month, as well as a new Vice Chair for the committee, Bhuvana Ramabhadran. She has been a member of the SLTC since 2010, and is a well-known member of our technical community, at IBM's TJ Watson Research Center since 1995. Currently, she manages a team of researchers in the Speech Recognition and Synthesis Research Group and co-ordinates research activities at IBM's labs in China, Tokyo, Prague and Haifa.
She was a technical area chair for ICASSP 2013 and for Interspeech 2012, and was one of the lead organizers and technical chair of IEEE ASRU 2011 in Hawaii. She co-organized the HLT-NAACL workshop on language modeling in 2011, special sessions on Sparse Representations in Interspeech 2010 and on Speech Transcription and Machine Translation at the 2007 ICASSP in Honolulu, and organized the HLT-NAACL 2004 Workshop on Interdisciplinary Approaches to Speech Indexing and Retrieval.
Of the 17 newly-elected members, seven are members continuing for a second term, while ten are new to the SLTC. By areas, we elected members in Speech Recognition (Jasha Droppo, Yifan Gong, Mark Hasegawa-Johnson, John Hershey, Frank Seide, Peder Olsen, George Saon, Hagen Soltau, Andreas Stolcke, Shinji Watanabe), in Speaker Recognition (Nick Evans), in Speech Synthesis (Tomoki Toda), in Natural Language Processing (Larry Heck), in Dialogue Systems (Svetlana Stoyanchev), In Speech Analysis (Gernot Kubin, Deep Sen), and in Speech Enhancement (Maurizio Omologo). The large number in ASR is due to the fact that we have so many papers in this area at ICASSP, and needed a significant increase to help with the reviews. We had been proportionally under-represented in this area.
At this time, we look forward to ASRU-2013 next month (the IEEE Automatic Speech Recognition and Understanding Workshop in the Czech Republic (www.asru2013.org)). In addition to the excellent program of oral and poster papers, as per the accepted papers that were submitted to our committee and others for evaluation this past summer and a nice social program (recall the nice pre-Christmas locale of Merano, Italy for ARSU-2009), there are 14 invited speakers scheduled, grouped on three major topics: Neural Nets, Limited Resources, and ASR in applications:
I remind our speech and language community of the importance of doing reviews for the ICASSP-2014 paper submissions. If you have not signed up to be a reviewer and wish to help, please contact the committee. The reviews should start in a few weeks.
While still a bit distant, we are looking forward to the next IEEE Spoken Language Technology Workshop, to be held at the South Lake Tahoe Resort Hotel in South Lake Tahoe, California (Dec. 6-9, 2014).
In closing, I hope you will consider reviewing ICASSP submissions as well as participating at ASRU-2013, ICASSP-2014 and SLT-2014. We look forward to meeting friends and colleagues in beautiful Olomouc, Florence, and Tahoe.
Best wishes,
Douglas O'Shaughnessy
Douglas O'Shaughnessy is the Chair of the Speech and Language Processing Technical Committee.
SLTC Newsletter, November 2013
SLaTE 2013 was the 5th workshop organised by the ISCA Special Interest Group on Speech and Language Technology for Education. It took place between 30th August and 1st September 2013 in Grenoble, France as a satellite workshop of Interspeech 2013. The workshop was attended by 68 participants from 20 countries. Thirty eight submitted papers and 14 demonstrations were presented in oral and poster sessions.
SLaTE is the ISCA Special Interest Group (SIG) on Speech and Language Technology in Education. SLaTE 2013 was the 5th SLaTE workshop, with previous workshops in Farmington (USA, 2007), Wroxall Abbey (UK, 2009), Tokyo (Japan, 2010) and Venice (Italy, 2011). It was organised by Pierre Badin, Gérard Bailly, Thomas Hueber and Didier Demolin from GIPSA-lab, and Françoise Raby from LIDILEM.
SLaTE 2013 was attended by 68 participants from 20 countries. Thirty eight submitted papers and 14 demonstrations were presented in oral and poster sessions over three days. SLaTE 2013 also featured plenary lectures by invited speakers, each an expert in his or her field. Diane Litman (University of Pittsburgh) presented her work on enhancing the effectiveness of spoken dialogue for STEM (Science, Technology, Engineering and Mathematics) education. Jozef Colpaert (Universiteit Antwerpen) described his work on the role and shape of speech technologies in well-designed language learning environments. The third invited speaker, Mary Beckman (Ohio State University), was unable to attend the workshop and her talk on enriched technology-based annotation and analysis of child speech was presented by Benjamin Munson (University of Minnesota).
Topics covered in the regular technical sessions included speech technologies for children and children's education, computer assisted language learning (CALL), and prosody, phonetics and phonology issues in speech and language in education.
The SLaTE Assembly was held on Saturday 31st August. Martin Russell (University of Birmingham, UK) and Helmer Strik (Radboud University, Nijmegen, the Netherlands) were re-elected as chair and secretary/treasurer of SLaTE, respectively. The assembly felt that SLaTE has become a successful and established SIG, with regular workshops typically attracting 70 attendees and 45 submitted papers. Nevertheless there was an enthusiasm for improving and expanding SLaTE, leading to a discussion about the future locations and frequency of SLaTE workshops - because SLaTE is currently a biennial satellite workshop of Interspeech, it will always be in Europe. The discussion expanded to include special sessions at SLaTE, invited plenary talks, the submitted paper acceptance rate, and possible colocation with other conferences. It was agreed that a questionnaire covering these issues will be circulated to the SLaTE mailing list.
In addition to its technical content, SLaTE 2013 featured an excellent social programme, including a cheese and wine reception in the sunny courtyard of the bar 'Le Saxo' in Grenoble, and a banquet accessed by Grenoble's bastille cable car in the ''Chez le Pèr Gras'' restaurant in the mountains overlooking the city.
The next SLaTE workshop will be held in Leipzig in 2015, as a satellite event of Interspeech 2015.
Pierre Badin (Pierre.Badin@gipsa-lab.grenoble-inp.fr), Thomas Hueber (Thomas.Hueber@gipsa-lab.grenoble-inp.fr) and Gérard Bailly (Gerard.Bailly@gipsa-lab.grenoble-inp.fr) are at GIPSA-lab, CNRS - Grenoble-Alps University, France, Martin Russell (m.j.russell@bham.ac.uk) is at the University of Birmingham, UK, Helmer Strik (w.strik@let.ru.nl) is at Radboud University, the Netherlands
SLTC Newsletter, November 2013
The INTERSPEECH 2013 Computational Paralinguistics Challenge was held in conjunction with INTERSPEECH 2013 in Lyon, France, 25-29 August 2013. This Challenge was the fifth in a series held at INTERSPEECH since 2009 as an open evaluation of speech-based speaker state and trait recognition systems. Four tasks were addressed, namely social signals (such as laughter), conflict, emotion, and autism. 65 teams participated, the baseline as was given by the organisers could be exceeded, and a new reference feature set by the openSMILE feature extractor and the four corpora used are publicly available at the repository of the series.
The INTERSPEECH 2013 Computational Paralinguistics Challenge was organised by Björn Schuller (Université de Genève, Switzerland / TUM, Germany / Imperial College London, England), Stefan Steidl (FAU, Germany), Anton Batliner (TUM/FAU, Germany), Alessandro Vinciarelli (University of Glasgow, Scotland / IDIAP Research Institute, Switzerland), Klaus Scherer (Université de Genève, Switzerland), Fabien Ringeval (Université de Fribourg, Switzerland), and Mohamed Chetouani (UPMC, France). The Challenge dealt with short-term states (emotion in twelve categories) and long-term states (autism in four categories). Moreover, group discussions were targeted to find conflict (in two classes but also given as continuous 'level of conflict' from -10 to +10), and a frame-level task was presented with the detection of the 'social signals' laughter and filler. The area under the receiver operating curve (AUC) was used for the first time as one of the competition measures, besides unweighted average recall (UAR) for the classification tasks. AUC is particularly suited for detection tasks. UAR equals the addition of the accuracies per class (i.e., the recall values) divided by the number of classes. With four tasks, this was the largest Computational Paralinguistics Challenge so far. Also, enacted data alongside naturalistic data had not been considered before this year's edition. A further novelty of this year's Challenge was the provision of a script for re-producing the baseline results on the development set in an automated fashion, including pre-processing, model training, model evaluation, and scoring by the competition and further measures as are outlined below.
The following corpora served as clearly defined test, training, and development partitions incorporating speaker independence as needed in most real-life settings: the Scottish-English SSPNet Vocalisation Corpus (SVC) from mobile phone conversations, the Swiss-French SSPNet Conflict Corpus (SC²) featuring broadcast political debates - both provided by the SSPNet, the Geneva Multimodal Emotion Portrayals (GEMEP) featuring professionally enacted emotions in 16 categories as provided by the Swiss Center for Affective Sciences, and the French Child Pathological Speech Database (CPSD) provided by UPMC including speech of children with Autism Spectrum Condition.
Four Sub-Challenges were addressed: in the Social Signal Sub-Challenge, the non-linguistic events laughter and filler of a speaker had to be detected and localised, based on acoustic information. In the Conflict Sub-Challenge, group discussions had to be automatically evaluated with the aim of recognising conflict as opposed to non-conflict. For training and development data, also continuous level of conflict was given. This information could be used for model construction or for reporting of more precise results in papers when dealing with the development partition. In the Emotion Sub-Challenge, the emotion of a speaker within a closed set of twelve categories had to be determined by a learning algorithm and acoustic features. In the Autism Sub-Challenge, three types of pathology of a speaker had to be determined as opposed to no pathology by a classification algorithm and acoustic features.
A new set of 6,373 acoustic features per speech chunk, again computed with TUM's openSMILE toolkit, was provided by the organisers. This set was based on low level descriptors that can be extracted on the frame level by a script provided by the organisers. For the Social Signals Sub-Challenge that requires localisation, a frame-wise feature set was derived from the above. These features could be used directly or sub-sampled, altered, etc., and combined with other features.
As in the 2009 - 2012 Challenges, the labels of the test set were unknown, and all learning and optimisations needed to be based only on the training material. Each participant could upload instance predictions to receive the results up to five times. The format was instance and prediction, and optionally additional probabilities per class. This allowed a final fusion of all participants' results, to demonstrate the potential maximum by combined efforts. As typical in the field of Computational Paralinguistics, classes were unbalanced. Accordingly, the primary measure to optimise was UAR and unweighted average AUC (UAAUC). The choice of taking the unweighted average is a necessary step to better reflect the imbalance of instances among classes. In addition - but not as competition measure - the correlation coefficient (CC) was given for the continuous level of conflict.
The organisers did not take part in the Sub-Challenges but provided baselines using the WEKA toolkit as a standard-tool so that the results were reproducible. As in previous editions, Support Vector Machines (and Regression for additional information) were chosen for classification and optimised on the development partition. The baselines were 83.3% UAAUC (social signals), 80.8% UAR (2-way conflict class), 40.9% (12-way emotion category), and 67.1% UAR (4-way autism diagnosis) on the test sets with chance levels of 50%, 50%, 8%, and 25% UAR, respectively.
All participants were encouraged to compete in all Sub-Challenges and each participant had to submit a paper to the INTERSPEECH 2013 Computational Paralinguistics Challenge Special Event. The results of the Challenge were presented in a Special Event of INTERSPEECH 2013 (double session) and the winners were awarded in the closing ceremony by the organisers. Four prizes (each 125.- EUR sponsored by the Association for the Advancement of Affective Computing (AAAC) - the former HUMAINE Association) could be awarded following the pre-conditions that the accompanying paper was accepted for the special event following the INTERSPEECH 2013 general peer-review, that the provided baseline was exceeded, and that a best result in a Sub-Challenge was reached in the respective competition measure. Overall, 65 sites registered for the Challenge, 33 groups actively took part in the Challenge and uploaded results, and finally 15 papers of participants were accepted for presentations.
The Social Signals Sub-Challenge was awarded to Rahul Gupta, Kartik Audhkhasi, Sungbok Lee, and Shrikanth Narayanan, all from the Signal Analysis and Interpretation Lab (SAIL), Department of Electrical Engineering, University of Southern California at Los Angeles, CA, U.S.A., who reached 0.915 UAAUC in their contribution "Paralinguistic Event Detection from Speech Using Probabilistic Time-Series Smoothing and Masking".
The Conflict Sub-Challenge Prize was awarded to Okko Räsänen and Jouni Pohjalainen both from the Department of Signal Processing and Acoustics, Aalto University, Finland, who obtained 83.9% UAR in their paper "Random Subset Feature Selection in Automatic Recognition of Developmental Disorders, Affective States, and Level of Conflict from Speech".
The Emotion Sub-Challenge Prize is awarded to Gábor Gosztolya, Róbert Busa-Fekete, and László Tóth, all from the Research Group on Artificial Intelligence, Hungarian Academy of Sciences and University of Szeged, Hungary, for their contribution "Detecting Autism, Emotions and Social Signals Using AdaBoost". Róbert Busa-Fekete is also with the Department of Mathematics and Computer Science, University of Marburg, Germany. They won this Sub-Challenge with 42.3% UAR.
The Autism Sub-Challenge Prize was awarded to Meysam Asgari, Alireza Bayestehtashk, and Izhak Shafran from the Center for Spoken Language Understanding, Oregon Health & Science University, Portland, OR, U.S.A. for their publication "Robust and Accurate Features for Detecting and Diagnosing Autism Spectrum Disorders". They reached 69.4% UAR.
Overall, the results of all 33 uploading groups were mostly very close to each other, and significant differences between the results accepted for publication were as rare as one might expect in such a close competition. However, by late fusion (equally weighted voting of N best participants' results), new baseline scores in terms of UAAUC and AUR exceeding all individual participants' results could be established in all Sub-Challenges except for the Autism Sub-Challenge. The general lesson learned thus again is "together we are best": obviously, the different feature representations and learning architectures contribute an added value, when combined. In addition, the Challenge clearly demonstrated the difficulty of dealing with real-life data - this challenge remains again.
In the last time slot of the 2nd session of the challenge, past and (possible) future of these challenges were discussed, and the audience filled in a questionnaire. The answers from the 35 questionnaires that we received can be summarised as follows and corroborate the pre-conditions and the setting chosen so far: time provided for the experiments (ca. 3 months) and number of possible uploads (5) was considered to be sufficient. Performance measures used (UAR and AUC) are preferred over other possible measures. Participation should be only possible if the paper was accepted in the review process; "additional 2-pages material" papers should not be established for rejected papers but possibly as a voluntary option. There is a strong preference for a "Special Event" at Interspeech, and not for a satellite workshop of Interspeech or an independent workshop. The benefits of these challenges for the community and by that, the adequate criteria for acceptance of a paper, are foremost considered to be interesting/new computational approaches and/or phonetic/linguistic features; boosting of performance (above baseline) was the second most important criterion.
For more information on the 2013 Computational Paralingusitics Challenge (ComParE 2013), see the webpage on emotion-research.net.
The organisers would like to thank the sponsors of INTERSPEECH 2013 ComParE: The Association for the Advancement of Affective Computing (AAAC), SSPNet, and the European Community's Seventh Framework Programme (FP7/2007-2013) under grant agreement no. 289021 (ASC-Inclusion).
Björn Schuller is an Associate of the University of Geneva’s Swiss Center for Affective Sciences and Senior Lecturer at Imperial College London and Technische Universität München. His main interests are Computational Paralinguistics, Computer Audition, and Machine Learning. Email: schuller@IEEE.org
Stefan Steidl is a Senior Researcher at Friedrich-Alexander University Erlangen-Nuremberg. His interests are multifaceted ranging from Computational Paralinguistics to Medical Image Segmentation. Email: steidl@cs.fau.de
Anton Batliner is Senior Researcher at Technische Universität München. His main interests are Computational Paralinguistics and Phonetics/Linguistics. Email: Anton.Batliner@lrz.uni-muenchen.de
Alessandro Vinciarelli is Senior Lecturer at the University of Glasgow (UK) and Senior Researcher at the Idiap Research Institute (Switzerland). His main interest is Social Signal Processing. Email: vincia@dcs.gla.ac.uk
Klaus Scherer is a Professor emeritus at the University of Geneva. His main interest are Affective Sciences. Email: Klaus.Scherer@unige.ch
Mohamed Chetouani is a Professor at University Pierre and Marie Curie-Paris 6. His main interests are Social Signal Processing and Social Robotics. Email: mohamed.chetouani@upmc.fr
Fabien Ringeval is an Assistant-Doctor at Université de Fribourg. His main interest is Multimodal Affective Computing. Email: fabien.ringeval@unifr.ch
SLTC Newsletter, November 2013
The goal of the Babel program is to rapidly develop speech recognition capability for keyword search in previously unstudied languages, working with speech recorded in a variety of conditions with limited amounts of transcription. Several issues and observations frame the challenges driving the Babel Program. The speech recognition community has spent years improving the performance of English automatic speech recognition systems. However, applying techniques commonly used for English ASR to other languages has often resulted in huge performance gaps for those other languages. In addition, there are an increasing number of languages for which there is a vital need for speech recognition technology but few existing training resources [1]. It is easy to envision a situation where there is a large amount of recorded data in a language which contains important information, but for which there are very few people to analyze the language and no existing speech recognition technologies. Having keyword search in that language to pick out important phrases would be extremely beneficial.
The languages addressed in the Babel program are drawn from a variety of different language families (e.g., Afro-Asiatic, Niger-Congo, Sino-Tibetan, Austronesian, Dravidian, and Altaic). Consistent with the differences among language families, the languages have different phonotactic, phonological, tonal, morphological, and syntactic properties.
The program is divided into two phases, Phase I and Phase II, each of which is divided into two periods. In the 28-month Phase I, 75-100% of the data is transcribed, while in the 24-month Phase II, only 50% of the data is transcribed. The first 16-month period of Phase I focuses on telephone speech, while the next 12-month period uses both telephone and non-telephone speech. These channel conditions continue in Phase II.
During each program period, researchers work with a set of development languages to develop new methods. Between 4-7 development languages are provided per period, with the number of languages increasing (and the development time decreasing) as the program progresses. At the end of each period, researchers are evaluated on an unseen surprise language, with constraints on both system build time and amount of available transcribed data. These constraints help to put the focus on developing methods that are robust across different languages, rather than tailored to specific languages. For this reason, the development languages are not identified until kickoff meetings for each program period, and the surprise languages are revealed only at the beginning of the each evaluation exercise.
In addition to challenges associated with limited transcriptions and build time, technical challenges include methods that are effective across languages, robustness to speech recorded in noisy conditions with channel diversity, effective keyword search algorithms for speech, and analysis of factors contributing to system performance.
All research teams are evaluated on a keyword search (KWS) task for both the development and surprise languages. The goal of the KWS task is to find all of the occurrences of a "keyword", i.e., a sequence of one or more words in a language's original orthography, in an audio corpus of unsegmented speech data [1,2].
April 2013 marked the completion of the base period of the Babel program, and teams were evaluated on their KWS performance for the Vietnamese surprise language task. The larger Vietnamese corpus consisted of 100 hours of speech in a training set, using only language resources limited to the supplied language pack (Base LR), and no test audio reuse (NTAR). This condition is known as Full Language Pack (FullLP) + BaseLR + NTAR. The smaller corpus consisted of 10 hours of speech in the training set, again using the Base LR and NTAR conditions. This condition is known as LimitedLP + Base LR + NTAR [2].
The performance of the FullLP and LimitedLP is measured in terms of Actual Term Weighted Value (ATWV) for keyword search and Token Error Rate (% TER) for transcription accuracy.
Below we highlight the system architectures and results of the four teams participating in the program.
The Babelon team consists of BBN (lead), Brno University of Technology, Johns Hopkins University, LIMSI/Vocapia, Massachusetts Institute of Technology, and North-West University. In addition to improving fundamental ASR, the principal focus of the Babelon team is to design and implement the core KWS technology, which goes well beyond ASR technology. The most critical areas for this effort thus far are:
Robust acoustic features using Neural Network (NN) based feature extraction [3] that improved all token error rate (TER) and KWS results by 8-10 points absolute;
A "white listing" method [4] modified for the unknown keyword condition to guarantee very high recall with minimal increase in computation and memory;
Score normalization techniques [5] to make scores consistent across keywords and to optimize performance, resulting in large gains over the unnormalized basic KWS system;
Semi-supervised training methods for use with 10 hours or less of transcribed audio data, which derive significant gains from the untranscribed audio for both the acoustic and language models [6], as well as further improvements in the acoustic feature transforms [7];
Deep Neural Network (DNN) acoustic models [8] that give large improvements within a Hidden Markov Model (HMM) framework, both separately and in combination with the more traditional GMM-based acoustic models.
The primary KWS system is a combination of different recognizers using different acoustic or language models across different sites within the Babelon team, including (1) HMM systems from BBN, (2) DNN and HMM systems from Brno University of Technology, and (3) HMM systems from LIMSI/Vocapia. All three systems use the robust NN based features. The scores of each system output are normalized before combination. We also focused on single systems and the single system result was never more than 10% behind the combined result.
LORELEI is an IBM-led consortium participating in the Babel program, and includes researchers from Cambridge University, Columbia University, CUNY Queens College, New York University, RWTH Aachen, and the University of Southern California. The approach to the Babel problem taken by LORELEI has emphasized combining search results from multiple indexes produced by a diverse collection of speech recognition systems. This team has focused on system combination because it can produce the best performance in the face of limited training data and acoustically challenging material, because it is possible to achieve a wide range of tradeoffs between computational requirements and keyword search performance by varying the number and complexity of the speech recognition systems used in combination, and because the system combination framework provides a good environment which to implement and test new ideas. In addition to fundamental work on speech recognition and keyword search technologies, the consortium is also pursuing work in automatic morphology, prosody, modeling of discourse structure, and machine learning, all with the aim of improving keyword search on new languages.
The primary entries from LORELEI in the surprise language evaluation on Vietnamese used the same general architecture for indexing and search. First, all conversation sides were decoded with a speaker-independent acoustic model, and the transcription output was post-processed to produce a segmentation of the evaluation data. Next, a set of speech transcription systems, most of which were multi-pass systems using speaker adaptation, were run to produce word-level lattices. Then, as the final step in indexing, the lattices from each transcription system were post-processed to produce lexical and phonetic indexes for keyword search. All indexes were structured as weighted finite-state transducers.
The LORELEI primary full language pack evaluation system combined search results from six different speech recognition systems: four using neural-network acoustic models and two GMM acoustic models using neural network features. One of the neural network acoustic models was speaker-independent, while the other five models were speaker-adapted. Three of the models performed explicit modeling of tone and used pitch features, while the other three did not.
Likewise, the LORELEI primary limited language pack evaluation system combined search results from six different speech recognition systems: one conventional GMM system, two GMM systems using neural-network features, and three neural-network acoustic models. One of the neural network acoustic models was speaker-independent, while the other five models were speaker-adapted. A notable feature of the limited language pack system is that one of neural-network features systems used a recurrent neural network for feature extraction.
The RADICAL consortium is the only University-lead consortium in BABEL, consisting of Carnegie Mellon University (lead and integrator, Pittsburgh and Silicon Valley campuses), The Johns Hopkins University, Karlsruhe Institute of Technology, Saarland University, and Mobile Technologies. Systems are developed using the Janus and Kaldi toolkits, which are benchmarked internally and combined at suitable points of the pipeline.
The overall system architecture of the RADICAL submissions to the OpenKWS 2013 evaluation [2] is best described as
A fast HMM-based segmentation and initial decoding pass using a BNF-GMM system trained on the most restricted "LimitedLP-BaseLR" condition, which is then used by all further processing;
A number of individual Kaldi- and Janus-based systems, designed to be complementary to each other;
Confusion network combination and ROVER system combination steps to optimize overall TER;
CombMNZ-based system combination to optimize overall ATWV.
Janus-based systems use a retrieval based on confusion networks, while Kaldi-based systems use an OpenFST-based retrieval. System combination was found to be beneficial on all languages, both development and surprise. While development focused on techniques useful for the LimitedLP conditions, the 2013 evaluation systems were tuned for the primary FullLP condition first and foremost. The evaluation systems used a number of interesting techniques, such as:
A selection of tonal features for Vietnamese (as well as Cantonese, post-evaluation), for example, Fundamental Frequency Variation Features and two different PITCH-based schemes; cross-adaptation and combination between different tonal features provides small additional gains;
Techniques to retrieve and verify hits based on acoustic similarity alone, i.e. using "zero resources", which could slightly improve performance;
Techniques to exploit the observation that keywords tend to (co-)occur in "bursts";
A number of Deep Neural Network acoustic models, using bottle-neck (BNF) features and GMMs, hybrid models, or combinations thereof;
Swordfish is a relatively small team, consisting of ICSI (the lead and system developer), University of Washington, Northwestern University, Ohio State University, and Columbia University.
Given the team size, most of the effort was focused on improving single systems. Swordfish developed two systems that shared many components. One was based on HTK, while the other was based on Kaldi. In each case the front end incorporated hierarchical bottleneck neural networks that used as input both vocal tract length normalized (VTLN)-warped mel-frequency cepstral coefficients (MFCCs) and novel pitch and probability of voicing features that were generated by a neural network that used critical band autocorrelations as input. Speech/nonspeech segmentation is implemented with an MLP-FST approach. The HTK-based system used a cross-word triphone acoustic model, using 16 mixtures/state for the FullLP case and an average of 12 mixtures/state for the LimitedLP. The Kaldi-based system incorporated SGMM models.
For both systems, the primary LM was a standard Kneser-Ney smoothed trigram, but the team also experimented (for the LimitedLP) with sparse plus low rank language modeling and in some cases got small improvements. The HTK-based system learned multiwords from the highest weight non-zero entries in the sparse matrix. For Vietnamese, some pronunciation variants were collapsed across dialects. Swordfish’s keyword search has thus far primarily focused on a word-based index (except for Cantonese, where merged character and word posting lists was done), discarding occurrences where the time gap between adjacent words in more than 0.5 seconds.
The performance of the surprise language full and limited language pack primary systems, measured in terms of Actual Term Weighted Value (ATWV) for keyword search and Token Error Rate (% TER) for transcription accuracy, are summarized below:
Team |
FullLP |
LimitedLP |
||
TER (%) |
ATWV |
TER (%) |
ATWV |
|
Babelon |
45.0 |
0.625 |
55.9 |
0.434 |
LORELEI |
52.1 |
0.545 |
66.1 |
0.300 |
RADICAL |
51.0 |
0.452 |
65.9 |
0.223 |
Swordfish |
55.9* |
0.332* |
71.0* |
0.120* |
Thank you to Mary Harper and Ronner Silber of IARPA for their guidance and support in helping to prepare this article.
[1] "IARPA broad agency announcement IARPA-BAA-11-02," 2011, https://www.fbo.gov/utils/view?id= ba991564e4d781d75fd7ed54c9933599.
[2] OpenKWS13 Keyword Search Evaluation Plan, March 2013 www.nist.gov/itl/iad/mig/upload/OpenKWS13-EvalPlan.pdf.
[3] M. Karafiat, F. Grezl, M. Hannemann, K. Vesely, and J. H. Ceernocky, "BUT BABEL System for Spontaneous Cantonese," in INTERSPEECH, 2013.
[4] B. Zhang, R. Schwartz, S. Tsakalidis, L. Nguyen, and S. Matsoukas, "White listing and score normalization for keyword spotting of noisy speech," in INTERSPEECH, 2012.
[5] D. Karakos et al., "Score Normalization and System Combination for Improved Keyword Spotting," in ASRU, 2013.
[6] R. Hsiao et al., "Discriminative Semi-supervised Training for Keyword Search in Low Resource Languages," in ASRU, 2013.
[7] F. Grezl and M. Karafiat, "Semi-supervised Bootstrapping Approach for Neural Network Feature Extractor Training," in ASRU, 2013.
[8] K. Vesely, A. Ghoshal, L. Burget, and D. Povey, "Sequence-discriminative Training of Deep Neural Networks," in INTERSPEECH, 2013.
If you have comments, corrections, or additions to this article, please contact the author: Tara Sainath, tsainath [at] us [dot] ibm [dot] com.
Tara Sainath is a Research Staff Member at IBM T.J. Watson Research Center in New York. Her research interests are mainly in acoustic modeling. Email: tsainath@us.ibm.com
SLTC Newsletter, November 2013
We are happy to announce the release of the MSR Identity Toolbox: A MATLAB toolbox for speaker-recognition research. This toolbox contains a collection of MATLAB tools and routines that can be used for research and development in speaker recognition. It provides researchers with a test bed for developing new front-end and back-end techniques, allowing replicable evaluation of new advancements. It will also help newcomers in the field by lowering the "barrier to entry," enabling them to quickly build baseline systems for their experiments. Although the focus of this toolbox is on speaker recognition, it can also be used for other speech related applications such as language, dialect, and accent identification. Additionally, it provides many of the functionalities available in other open-source speaker recognition toolkits (e.g., ALIZE [1]) but with a simpler design which makes it easier for the users to understand and modify the algorithms.
The MATLAB tools in the Identity Toolbox are computationally efficient for three reasons: vectorization, parallel loops, and distributed processing. First, the code is simple and easy for MATLAB to vectorize. With long vectors, most of the CPU time is spent in optimized loops, which are the core of the processing. Second, the code is designed for parallelization available through the Parallel Computing Toolbox (i.e., the toolbox codes use "parfor" loops). Without the Parallel Computing Toolbox, these loops execute as normal "for" loops on a single CPU. But when this toolbox is installed, the loops are automatically distributed across all the available CPUs. In our pilot experiments, the codes were run across all 12 cores in a single machine. Finally, the primary computational routines are designed to work as compiled programs. This makes it easy to distribute the computational work to all the machines on a computer cluster, without the need for additional licenses.
In recent years, the design of robust and effective speaker-recognition algorithms has attracted significant research effort from academic and commercial institutions. Speaker recognition has evolved substantially over the past few decades; from discrete vector quantization (VQ) based systems [2] to adapted Gaussian mixture model (GMM) solutions [3], and more recently to factor analysis based Eigenvoice (i-vector) frameworks [4]. The Identity Toolbox, version 1.0, provides tools that implement both the conventional GMM-UBM and state-of-the-art i-vector based speaker-recognition strategies.
Figure 1: Block diagram of a typical speaker-recognition system. A bigger version of the figure
As shown in Fig. 1, a speaker-recognition system includes two primary components: a front-end and a back-end. The front-end transforms acoustic waveforms into more compact and less redundant acoustic feature representations. Cepstral features are most often used for speaker recognition. It is practical to only retain the high signal-to-noise ratio (SNR) regions of the waveform, therefore there is also a need for a speech activity detector (SAD) in the front-end. After dropping the low SNR frames, acoustic features are further post-processed to remove the linear channel effects. Cepstral mean and variance normalization (CMVN) [5] is commonly used for the post-processing. The CMVN can be applied globally over the entire recording or locally over a sliding window. Feature warping [6], which is also applied over a sliding window, is another popular feature-normalization technique that has been successfully applied for speaker recognition. This toolbox provides support for these normalization techniques, although no tool for feature extraction or SAD is provided. The Auditory Toolbox [7] and VOICEBOX [8], which are both written in MATLAB, can be used for feature extraction and SAD purposes.
The main component of every speaker-recognition system is the back-end where speakers are modeled (enrolled) and verification trials are scored. The enrollment phase includes estimating a model that represents (summarizes) the acoustic (and often phonetic) space of each speaker. This is usually accomplished with the help of a statistical background model from which the speaker-specific models are adapted. In the conventional GMM-UBM framework the universal background model (UBM) is a Gaussian mixture model (GMM) that is trained on a pool of data (known as the background or development data) from a large number of speakers [3]. The speaker-specific models are then adapted from the UBM using the maximum a posteriori (MAP) estimation. During the evaluation phase, each test segment is scored either against all enrolled speaker models to determine who is speaking (speaker identification), or against the background model and a given speaker model to accept/reject an identity claim (speaker verification).
On the other hand, in the i-vector framework the speaker models are estimated through a procedure called Eigenvoice adaptation [4]. A total variability subspace is learned from the development set and is used to estimate a low (and fixed) dimensional latent factor called the identity vector (i-vector) from adapted mean supervectors (the term "i-vector" sometimes also refers to a vector of "intermediate" size, bigger than the underlying cepstral feature vector but much smaller than the GMM supervector). Unlike the GMM-UBM framework, which uses acoustic feature vectors to represent the test segments, in the i-vector paradigm both the model and test segments are represented as i-vectors. The dimensionality of the i-vectors are normally reduced through linear discriminant analysis (with Fisher criterion [9]) to annihilate the non-speaker related directions (e.g., the channel subspace), thereby increasing the discrimination between speaker subspaces. Before modelling the dimensionality-reduced i-vectors via a generative factor analysis approach called the probabilistic LDA (PLDA) [10], they are mean and length normalized. In addition, a whitening transformation that is learned from i-vectors in the development set is applied. Finally, a fast and linear strategy [11], which computes the log-likelihood ratio (LLR) between same versus different speaker's hypotheses, scores the verification trials.
The Identity toolbox provides tools for speaker recognition using both the GMM-UBM and i-vector paradigms. It has been attempted to maintain consistency with the naming convention in the code to follow the formulation and symbolization used in the literature. This will make it easier for the users to compare the theory with the implementation and help them better understand the concept behind each algorithm. The tools can be run from a MATLAB command line using available parallelization (i.e., parfor loops), or compiled and run on a computer cluster without the need for a MATLAB license.
The toolbox includes two demos which use artificially generated features to show how different tools can be combined to build and run GMM-UBM and i-vector based speaker recognition systems. In addition, the toolbox contains scripts for performing a small-scale speaker identification experiment using the TIMIT database. Moreover, we have replicated state-of-the-art results on the large-scale NIST SRE-2008 core tasks (i.e., short2-short3 conditions [15]). The list below shows the different tools available in the toolbox, along with a short descriptions of their capabilities:
Feature normalization
GMM-UBM
i-vector-PLDA
EER and DET plot
The Identity Toolbox is available from the MSR website (http://research.microsoft.com/downloads) under a Microsoft Research License Agreement (MSR-LA) that allows use and modification of the source codes for non-commercial purposes. The MSR-LA, however, does not permit distribution of the software or derivative works in any form.
[1] A. Larcher, J.-F. Bonastre, and H. Li, "ALIZE 3.0 - Open-source platform for speaker recognition," in IEEE SLTC Newsletter, May 2013.
[2] F. Soong, A. Rosenberg, L. Rabiner, and B.-H. Juang, "A vector quantization approach to speaker recognition," in Proc. IEEE ICASSP, Tampa, FL, vol.10, pp.387-390, April 1985.
[3] D.A. Reynolds, T.F. Quatieri, R.B. Dunn, "Speaker verification using adapted Gaussian mixture models", Digital Signal Processing, vol. 10, pp. 19-41, January 2000.
[4] N. Dehak, P. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet, "Front-end factor analysis for speaker verification," IEEE TASLP, vol. 19, pp. 788-798, May 2011.
[5] B.S. Atal, "Effectiveness of linear prediction characteristics of the speech wave for automatic speaker identification and verification," J. Acoust. Soc. Am., vol. 55, pp. 1304-1312, June 1974.
[6] J. Pelecanos and S. Sridharan, "Feature warping for robust speaker veri?cation," in Proc. ISCA Odyssey, Crete, Greece, June 2001.
[7] M. Slaney. Auditory Toolbox - A MATLAB Toolbox for Auditory Modeling Work. [Online]. Available: https://engineering.purdue.edu/~malcolm/interval/1998-010/
[8] M. Brooks. VOICEBOX: Speech Processing Toolbox for MATLAB. [Online]. Available: http://www.ee.ic.ac.uk/hp/staff/dmb/voicebox/voicebox.html
[9] K. Fukunaga, Introduction to Statistical Pattern Recognition. 2nd ed. New York: Academic Press, 1990, Ch. 10.
[10] S.J.D. Prince and J.H. Elder, "Probabilistic linear discriminant analysis for inferences about identity," in Proc. IEEE ICCV, Rio de Janeiro, Brazil, October 2007.
[11] D. Garcia-Romero and C.Y. Espy-Wilson, "Analysis of i-vector length normalization in speaker recognition systems," in Proc. INTERSPEECH, Florence, Italy, August 2011, pp. 249-252.
[12] P. Kenny, "A small footprint i-vector extractor," in Proc. ISCA Odyssey, The Speaker and Language Recognition Workshop, Singapore, Jun. 2012.
[13] D. Matrouf, N. Scheffer, B. Fauve, J.-F. Bonastre, "A straightforward and efficient implementation of the factor analysis model for speaker verification," in Proc. INTERSPEECH, Antwerp, Belgium, Aug. 2007, pp. 1242-1245.
[14] P. Kenny, "Bayesian speaker verification with heavy-tailed priors," in Proc. Odyssey, The Speaker and Language Recognition Workshop, Brno, Czech Republic, Jun. 2010.
[15] "The NIST year 2008 speaker recognition evaluation plan," 2008. [Online]. Available: http://www.nist.gov/speech/tests/sre/2008/sre08_evalplan_release4.pdf
[16] "The NIST year 2010 speaker recognition evaluation plan," 2010. [Online]. Available: http://www.itl.nist.gov/iad/mig/tests/sre/2010/NIST_SRE10_evalplan.r6.pdf
Seyed Omid Sadjadi is a PhD candidate at the Center for Robust Speech Systems (CRSS), The University of Texas at Dallas. His research interests are speech processing and speaker identification. Email: omid.sadjadi@ieee.org Malcolm Slaney is a Researcher at Microsoft Research in Mountain View, California, a Consulting Professor at Stanford CCRMA, and an Affiliate Professor in EE at the University of Washington. He doesn’t know what he wants to do when he grows up. Email: malcolm@ieee.org Larry Heck is a Researcher in Microsoft Research in Mountain View California. His research interests include multimodal conversational interaction and situated NLP in open, web-scale domains. Email: larry.heck@ieee.org SLTC Newsletter, November 2013 This is a description of the REAL Challenge for researchers and students to invent new system that have real users.
The Dialog Research Center at Carnegie Mellon (DialRC) is organizing the REAL Challenge. The goal of the
REAL Challenge (dialrc.org/realchallenge) is to build speech systems that are used
regularly by real users to accomplish real tasks. These systems will give the
speech and spoken dialog communities steady streams of research data as well as
platforms they can use to carry out studies. It will engage both seasoned
researchers and high school and undergrad students in an effort to find the
next great speech applications.
Humans greatly rely on spoken language to communicate, so it seems natural that we
would be likely to communicate with objects via speech as well. Some speech
interfaces do exist and they show promise, demonstrating that smart engineering
can palliate indeterminate recognition. Yet the general public has not yet
picked up this means of communication as easily as they have the tiny
keyboards. About two decades ago, many researchers were using the internet,
mostly to send and receive email. They were aware of the potential that it held
and waited to see when and how the general public would adopt it. Practically a
decade later, thanks to providers such as AmericaOnline,
who had found how to create easy access, everyday people started to use the
internet. And this has dramatically changed our lives. In the same way, we all
know that speech will eventually replace the keyboard in many situations when
we want to speak to objects. The big question is what is the interface or
application that will bring us into that era.
Why hasn't speech become a more prevalent interface? Most of today’s speech
applications have been devised by researchers in the speech domain. While they
certainly know what types of systems are “doable”, they may not be the best at
determining which speech applications would be universally acceptable.
We
believe that students who have not yet had their vision limited by knowledge of
the speech and spoken dialog domains and who have grown up with computers as a
given, are the ones that will find new, compelling and universally appealing
speech applications. Along with the good ideas, they will need some guidance to
gain focus. Having a mentor, attending webinars and participating in a research
team can provide this guidance.
The
REAL challenge will combine the talents of these two very different groups.
First it will call upon the speech research community who know what it takes to
implement real applications. Second, it will advertise to and encourage
participation from high school students and college undergrads who love to hack
and have novel ideas about using speech.
The
REAL Challenge is starting with a widely-advertised call for proposals. Students
can propose an application. Researchers can propose to create systems or to
provide tools. A proposal can target any type of application in any language.
The proposals will be lightly filtered and the successful proposers will be
invited to a workshop on June 21, 2014 to show what they are proposing and to
team up. The idea is for students to meet researchers and for the latter to
take one or more students on their team. Students will present their ideas and
have time for discussion with researchers. A year later, a second workshop will
assemble all who were at the first workshop to show the resulting systems
(either WOZ experiments with real users or prototypes), measure success and
award prizes.
Student
travel will be taken care of by DialRC through grants.
Students
will have help from DialRC and from researchers as they formulate their
proposals. DialRC will provide webinars on such topics as speech processing
tool basics and how to present a poster. Students will also be assigned mentors.
Researchers in speech and spoken dialog can volunteer to be a one-on-one
mentor to a student. This consists of being in touch either in person or
virtually. Mentors can tell the students about what our field consists of, what
the state of the art is, and what it is like to work in research. They can
answer questions about how the student can talk about their ideas. If you are a researcher in speech and/or
spoken dialog and you would like to be a mentor, please let us know at realchallenge@speechinfo.org
The
groups will create entries. Here are
the characteristics of a successful entry.
Success
will be judged on the basis of originality, amount of regular users and of data
and on other criteria to be agreed upon by the Challenge scientific committee
and the participants.
Possible
prize areas for an entry include:
Details
of the measures of success will be refined at the workshop with input from the
participants.
The
REAL Challenge was announced at several major conferences during the summer of
2013: SIGDIAL, Interspeech, ACL. It is also being
announced to younger participants through their schools and hacker websites.
March 20, 2014 : Proposals due
April 20, 2014 : Feedback
on proposals and invitations to attend the workshop sent out.
June 21,2014 : Workshop in Baltimore Maryland USA.
Early
summer of 2015 : Resulting systems are presented a year after the first workshop.
For
students, participation in the REAL Challenge will present several unique opportunities:
For
researchers, participation reaps several benefits:
Industrial
research groups should be interested to see:
This
Challenge is run by the Dialog Research Center at Carnegie Mellon (DialRC)
Alan W Black, Carnegie Mellon
University, USA Maxine Eskenazi, Carnegie Mellon University, USA Helen
Hastie, Heriot Watt University, Scotland
Gary Geunbae Lee, Pohang University of Science and Technology, South
Korea
Sungjin Lee, Carnegie Mellon University,
USA
Satoshi Nakamura, Nara Institute of
Science and Technology, Japan
Elmar Noeth, Friedrich-Alexander University Erlangen-Nuremberg, Germany
Antoine Raux, Lenovo, USA
David Traum, University of Southern California, USA
Jason Williams, Microsoft Research, USA
Contact
information: Website :
http://dialrc.org/realchallenge Maxine
Eskenazi is Principal Systems Scientist in the Language
Technologies Institute at Carnegie Mellon University.
Her interests are in dialog systems and computer-assisted language learning.
SLTC Newsletter, November 2013 The Workshop on Speech Production in Automatic Speech Recognition (SPASR) was recently held as a satellite workshop of Interspeech 2013 in Lyon on August 30.
The use of speech production knowledge and data to enhance speech recognition and related technologies is being actively pursued by a number of widely dispersed research groups using different approaches. For example, some groups are using measured or inferred articulation to improve speech recognition in noisy or otherwise degraded conditions; others are using models inspired by articulatory phonology to account for pronunciation variation; still others are using articulatory dimensions in speech synthesis; and finally, many are finding clinical applications for production data and articulatory inversion. The goal of this workshop was to bring together these research groups, as well as other researchers who are interested in learning about or contributing ideas to this area, to share ideas, results, and perspectives in an intimate and productive setting. The range of techniques currently being explored is rapidly growing, and is increasingly benefiting from new ideas in machine learning and greater availability of data.
The SPASR technical program included 5 invited speakers, as well as spotlight talks and a poster session for the 11 contributed papers. The invited talks set the scene with inspiring and thought-provoking presentations on topics such as new opportunities in the collection and use of diverse types of articulatory data (Shri Narayanan), invariance in articulatory gestures (Carol Espy-Wilson), models of dysarthric speech (Frank Rudzicz), new articulatory data collections and acoustic-to-articulatory estimation (Korin Richmond), and silent speech interfaces (Bruce Denby). The contributed papers and abstracts presented new work and reviews of work on related topics including computational models of infant language learning, human-machine comparisons in recognition errors, estimation of articulatory parameters from acoustic and articulatory data, induction of articulatory primitives from data, the use of articulatory classification/inversion in speech recognition, silent speech interfaces, and the use of multi-view learning and discriminative training using limited articulatory data.
The format and content of the workshop, as well as the intimate and comfortable setting at l'Institut des Sciences de l'Homme in Lyon, lent themselves to lively and fruitful discussion. The talk slides and submitted papers and abstracts can be found on the workshop's web site, http://ttic.edu/livescu/SPASR2013.
The workshop was co-organized by Karen Livescu (TTI-Chicago), Jeff Bilmes (U. Washington), Eric Fosler-Lussier (Ohio State U.), and Mark Hasegawa-Johnson (U. Illinois at Urbana-Champaign), with local organization by Emmanuel Ferragne (U. Lyon 2). It was supported by ISCA and Carstens.
Karen Livescu is Assistant Professor at TTI-Chicago in Chicago, IL, USA. Her main interests are in speech and language processing, with a slant toward combining machine learning with knowledge from linguistics and speech science. Email: klivescu@ttic.edu.
SLTC Newsletter, November 2013 The field of speaker recognition has evolved significantly over the past twenty years, with great efforts worldwide from many groups/laboratories/universities, especially those participating in the biannual U.S. NIST SRE - Speaker Recognition Evaluation [1]. Recently, there has been great interest in considering the ability to perform effective speaker identification when speech is not produced in "neutral" conditions. Effective speaker recognition requires knowledge and careful signal processing/modeling strategies to address any mismatch conditions that could exist between the training and testing conditions. This article considers some past and recent efforts, as well as suggested directions when subjects move from a "neutral" speaking style, vocal effort, and ultimately pure "screaming" when it comes to speaker recognition. In the United States recently, there has been discussion in the news regarding the ability to accurately perform speaker recognition when the audio stream consists of a subject screaming. Here, we illustrate a probe experiment, but before that some background on speech under non-neutral conditions.
Some could argue that speech processing, and specifically speech recognition in non-neutral speaking conditions, began with a number of strategic studies in the mid to late 1980's in the area which became known as "speech under stress". Great American Scream Machine Located at Six flags over Georgia (Atlanta, GA; USA)
As part of the effort to advanced speech under stress research, the SUSAS - "Speech Under Simulated and Actual Stress" corpus was developed [7,11,12]. Part of the data collection for the SUSAS corpus included speech collected on two rides at an amusement park (6 Flags Over Georgia Atlanta, GA) named "Free Fall" and a roller coaster ride named "Scream Machine". Through these studies, it is clear speech produced under stress results in significant changes to speech parameters, which directly impact speech technology including speech recognition, speaker ID, speech coding, and other systems. Across these studies however, there remains the question - what about "screams"? Subjects that scream are producing an audio stream, but is there really "speaker content" in this data?
Another issue with screams and speech technology is that they normally are produced with a short duration. In order to be able to focus on just one variability (i.e., the screaming aspect of speech production), it is important that we set aside the problem of short durations which, unfortunately, imposes an unrealistic assumption that long durations of screaming samples are available. The last obstacle in capturing screams, which is also a factor in stressed speech data collection as well as vocal effort, is the issue of clipping - since in controlled settings an automatic gain control may not exist at the input to the A/D converter. For the study conducted by CRSS-UTDallas, this was managed by adjusting the microphones to ensure that the recorded signal was not too weak for neutral speech while accurately representing the waveform without observing any clipping when the subjects scream, which also poses mitigating restrictions on the data.
As we have noted, the changes in speech production have been extensively investigated for stress, Lombard effect, and different emotions in [7,19], and their impact on speech recognition [2-10]. Their effects on speaker recognition have also been measured through experimentation [20]. However, to the best of our knowledge a detailed study is not available on the detrimental effect of screaming speech for speaker recognition. It is reasonable to predict that speech production changes in screams harm both human-based and automatic speaker identification as they do in different stress and emotion conditions [13,14,10].
In this article, we do not intend to propose a technique to compensate for the mismatch between train and test when the available test data consists of screaming, nor do we attempt to improve speaker identification for screaming data. The goal here is to merely raise the question of screaming speaker identification and suggest that further research on the issue is needed. A similar challenge was conducted in alliance with the USA Federal Law Enforcement Training Center (FLETC) which included data recorded while trainees completed a simulated hostage scenario [16]. In that case, law enforcement trainees were put in an unreal but highly stressful situation which consequently included high amounts of screaming [16,20]. The speaker recognition accuracy in experiments for that study dropped from 91.7% to 70% for low and high stress levels, respectively.
Figure 1: (a) Neutral Speech, and (b) Scream from the same speaker
In the present CRSS-UTDallas study, a number of subjects participated in data collection. To illustrate the significant change in speech structure, Fig. 1 shows a sample spectrogram of the same speaker while producing neutral speech (Fig. 1(a)) and when screaming (Fig. 1(b)). Figure 2 shows the CRSS-UTDallas website which includes sample audio clips for interested readers to listen to of subjects screaming.
With respect to the question as to speaker recognition under screaming, a sample probe experiment was performed by CRSS-UTDallas. In the sample experiments, trials consisted of train and test pairs in a speaker verification task. A subset of trials were randomly selected to be evaluated by human subjects (caution was made to ensure that the listeners did not have any prior familiarity with the speakers under neutral/screaming conditions). The recognition system employed was based on maximum a posteriori (MAP) adaptation of Gaussian mixture models (GMMs) trained for each model speaker (more robust speaker ID systems are available, but for the purposes of this exercise, we wanted to simply explore a traditional baseline system performance). The test files in the trials were scored against the GMMs and the resulting scores used to obtain overall system accuracy. Performances were evaluated by computing the equal error rate (EER) for the ensemble trials. Again, it is noted that special care was taken to omit all possible mismatches between development and enrollment data (such as channel, session, microphone, etc.), so performance deviation would only be due to the presence or absence of screaming. For the automatic speaker recognition system, the Speaker ID performance for screaming test files were all in the range of 40-45% depending on which speaker was being evaluated. The condition also affects human listeners, where the highest accuracy obtained by CRSS-UTDallas lab members performing the random listener evaluation was about 25%, despite the fact that listeners were familiar with the subjects.
http://crss.utdallas.edu/Projects/SID_Scream/
Figure 2: CRSS-UTDallas website with sample audio files of subjects under "scream" conditions.
The results here suggest that while using neutral trained speech, effective speaker recognition using "screaming" is simply not effective or reliable. While further research could result in more effective solutions, the current technology suggests that sufficient speaker identity information is not contained within a scream audio stream for either automatic speaker ID systems, as well as for human listeners. One final note to all speech researchers in the field wanting to explore this question on speaker ID and screaming (particularly if you are on a University campus!) - be sure to notify your neighboring labs as well as your campus police beforehand if you are plan on collecting such data, just in case someone hears people screaming down the hallways at your institutions!
1http://shawnliv.com/index.php/perform-well-under-stress/ 2http://archive.constantcontact.com/fs129/1109991857457/archive/1111496386120.html 3https://www2.sixflags.com/overgeorgia/attractions/great-american-scream-machine 4http://en.wikipedia.org/wiki/The_Scream [1] NIST SRE - Speaker Recognition Evaluation: http://www.nist.gov/itl/iad/mig/sre.cfm
[2] P.K. Rajasekaran, G. Doddington, J. Picone, "Recognition of speech under stress and in noise," IEEE ICASSP-1986, pp. 733 - 736, Tokyo, Japan, April 1986.
[3] R. Lippmann, E. Martin, D. Paul, "Multi-style training for robust isolated-word speech recognition," IEEE ICASSP-1987, pp. 705 - 708, Dallas, TX, April 1987.
[4] D. Paul, "A speaker-stress resistant HMM isolated word recognizer," IEEE ICASSP-1987, pp. 713 - 716, Dallas, TX, April 1987.
[5] D. Paul, E. Martin, "Speaker stress-resistant continuous speech recognition," IEEE ICASSP-1988, pp. 283 - 286, New York, NY, April 1988.
[6] Y. Chen, "Cepstral domain talker stress compensation for robust speech recognition," IEEE Trans. Acoustics, Speech and Signal Processing, pp. 433 - 439, April 1988.
[7] J.H.L. Hansen, "Analysis and Compensation of Stressed and Noisy Speech with Application to Robust Automatic Recognition," PhD. Thesis, 429pgs, School of Electrical Engineering, Georgia Institute of Technology, July 1988.
[8] J.H.L. Hansen, M. Clements, "Stress Compensation and Noise Reduction Algorithms for Robust Speech Recognition,'' IEEE ICASSP-1989, pp. 266-269, Glasgow, Scotland, May 1989
[9] J.H.L. Hansen, "Adaptive Source Generator Compensation and Enhancement for Speech Recognition in Noisy Stressful Environments,'' IEEE ICASSP-1993, pp. 95-98, Minneapolis, Minnesota, April 1993
[10] J.H.L. Hansen, "Morphological Constrained Enhancement with Adaptive Cepstral Compensation (MCE-ACC) for Speech Recognition in Noise and Lombard Effect," IEEE Trans. Speech & Audio Processing, SPECIAL ISSUE: Robust Speech Recognition, pp. 598-614, Oct. 1994.
[11] LDC - Linguistics Data Consortium: the SUSAS Speech Under Simulated and Actual Stress database: http://catalog.ldc.upenn.edu/LDC99S78
[12] J.H.L. Hansen, S. Bou-Ghazale, "Getting Started with SUSAS: A Speech Under Simulated and Actual Stress Database," EUROSPEECH-97, vol. 4, pp. 1743-1746, Rhodes, Greece, Sept. 1997.
[13] J.H.L. Hansen, "Analysis and Compensation of Speech under Stress and Noise for Environmental Robustness in Speech Recognition," Speech Communication, Special Issue on Speech Under Stress, pp. 151-170, Nov. 1996
[14] J.H.L. Hansen, C. Swail, A.J. South, R.K. Moore, H. Steeneken, E.J. Cupples, T. Anderson, C.R.A. Vloeberghs, I. Trancoso, P. Verlinde, "The Impact of Speech Under `Stress' on Military Speech Technology," NATO Research & Technology Organization RTO-TR-10, AC/323(IST)TP/5 IST/TG-01, March 2000 (ISBN: 92-837-1027-4).
[15] D.S. Finan, J.H.L. Hansen, "Toward a Meaningful Model of Speech Under Stress," 12th Conference on Motor Speech (Speech Motor Control Track), Albuquerque, NM, March 2004.
[16] E.Ruzanski, J.H.L. Hansen, D. Finan, J. Meyerhoff, "Improved 'TEO' Feature-based Automatic Stress Detection Using Physiological and Acoustic Speech Sensors," ISCA INTERSPEECH-2005, pp. 2653-2656, Lisbon, Portugal, Sept. 2005
[17] C. Ross. (2013, June 6). Fla. judge to decide on whether 911 scream analysis is admissible in Zimmerman trial [The Daily Caller]. Available: http://dailycaller.com/2013/06/06/fla-judge-to-decide-on-whether-911-scream-analysis-is-admissible-in-zimmerman-trial/
[18] S. Skurka. (2013, July 2). Day 6 of the Zimmerman Trial: Murder or Self-Defence? - The FBI Audio Voice Analyst [The Huffington Post-Canada]. Available: http://www.huffingtonpost.ca/steven-skurka/zimmerman-trial_b_3532604.html
[19] J.H.L. Hansen, "Evaluation of Acoustic Correlates of Speech Under Stress for Robust Speech Recognition.'' IEEE Proc. 15th Annual Northeast Bioengineering Conference, pp. 31-32, Boston, Mass., March 1989
[20] J. H. L. Hansen, E. Ruzanski, H. Boril, J. Meyerhoff,, "TEO-based speaker stress assessment using hybrid classification and tracking schemes," Inter. Journal of Speech Technology (Springer), vol. 15, issue 3, pp 295-311, Sept., 2012
[21] B. Womack and J. H. L. Hansen, "N-channel hidden Markov models for combined stress speech classification and recognition," IEEE Trans. on Speech and Audio Processing, 7, pp 668-677, 1999
[22] G. Zhou, J.H.L. Hansen, and J.F. Kaiser, "Nonlinear Feature Based Classification of Speech under Stress," IEEE Transactions on Speech & Audio Processing, vol. 9, no. 2, pp. 201-216, March 2001
John H.L. Hansen serves as Associate Dean for Research, Erik Jonsson School of Engineering & Computer Science, as well as Professor in Electrical Engineering and the School of Brain and Behavioral Sciences at The University of Texas at Dallas (UTDallas). At UTDallas, he leads the Center for Robust Speech Systems (CRSS). His research interests are in speech processing, speaker modeling, and human-machine interaction.
Navid Shokouhi is a PhD candidate at the Department of Electrical Engineering at the University of Texas at Dallas, Erik Jonsson School of Engineering. He works under supervision of Dr. John Hansen in the Center of Robust Speech Systems. His research interests are speech and speaker recognition in co-channel speech signals.
The REAL Challenge
Maxine Eskenazi
Overview
Why have a REAL Challenge?
How can we combine these two types of talent?
Preparing students
What is an entry?
How can we assess success?
Timeline
What advantage is there for a
student to participate?
What does this Challenge
contribute to the speech community?
Why should industrial research
groups be interested in the Challenge?
Organization
REAL Challenge Scientific Committee
SPASR workshop brings together speech production and its use in speech technologies
Karen Livescu
Speaker Identification: Screaming, Stress and Non-Neutral Speech, is there speaker content?
John H.L. Hansen, Navid Shokouhi
 A number of these studies focused on evaluating small vocabulary based speech recognition algorithms in multiple "speaking styles" or "stress" [2-5]. This included a number of advancements from researchers at MIT Lincoln Laboratory in an approach that was termed "multi-style training", where training speech was captured in a range of speaking styles, and models were trained with these simulated speaking conditions in order to anticipate variations seen in actual input speech data [3,4,5].
A number of these studies focused on evaluating small vocabulary based speech recognition algorithms in multiple "speaking styles" or "stress" [2-5]. This included a number of advancements from researchers at MIT Lincoln Laboratory in an approach that was termed "multi-style training", where training speech was captured in a range of speaking styles, and models were trained with these simulated speaking conditions in order to anticipate variations seen in actual input speech data [3,4,5].  Some of the earliest forms of cepstral feature or cepstral mean compensation were first formulated in this domain by Chen [6], Hansen , et. al [7-10], and others in the area to address speech under stress. Detection of speech under stress [21,22] has also motivated interest in exploring non-neutral speech processing.
Some of the earliest forms of cepstral feature or cepstral mean compensation were first formulated in this domain by Chen [6], Hansen , et. al [7-10], and others in the area to address speech under stress. Detection of speech under stress [21,22] has also motivated interest in exploring non-neutral speech processing.

 This portion of the SUSAS corpus was collected in the mid 1980's and while the research which followed focused on speech under stress, one component of this corpus which remained un-explored was the fact that all subjects who produced the required set of words during rides on the coaster also produced many uncontrollable screams. Research studies in this area concentrated on formulating stress compensation methods for speech recognition of speech under stress - which included speaking styles, emotion, Lombard effect, and task stress [8,9,10,13]. Further work in the area of "interoperability of speech technology under stress" was addressed by the NATO Research Study Group RSG.10 [14]. A study was performed using the SUSAS corpus and reported in [14] to consider the impact of stress/Lombard effect or emotion on speaker recognition systems, and while only a limited amount of speech was available for testing, that study did illustrate how speech under "non-neutral" speaking conditions were impacted by stress (emotion or Lombard effect) [results from [14] shown here in this plot for matched vs. mismatched speaker ID conditions using a default neutral trained speaker ID models].
This portion of the SUSAS corpus was collected in the mid 1980's and while the research which followed focused on speech under stress, one component of this corpus which remained un-explored was the fact that all subjects who produced the required set of words during rides on the coaster also produced many uncontrollable screams. Research studies in this area concentrated on formulating stress compensation methods for speech recognition of speech under stress - which included speaking styles, emotion, Lombard effect, and task stress [8,9,10,13]. Further work in the area of "interoperability of speech technology under stress" was addressed by the NATO Research Study Group RSG.10 [14]. A study was performed using the SUSAS corpus and reported in [14] to consider the impact of stress/Lombard effect or emotion on speaker recognition systems, and while only a limited amount of speech was available for testing, that study did illustrate how speech under "non-neutral" speaking conditions were impacted by stress (emotion or Lombard effect) [results from [14] shown here in this plot for matched vs. mismatched speaker ID conditions using a default neutral trained speaker ID models].
 Work continued in this domain with the goals of improved modeling of speech under stress, which augmented a traditional acoustic microphone with a physiological microphone (again, speech was collected on roller-coaster rides! - see subject with close-talk microphone and p-mic positioned at his larynx with the black Velcro strap around his neck) [15,16]. Again, the focus was on analysis of speech motor characteristics of speech under stress, illustrating how g-force, motion, as well as physical/cognitive stress impacts speech production.
Work continued in this domain with the goals of improved modeling of speech under stress, which augmented a traditional acoustic microphone with a physiological microphone (again, speech was collected on roller-coaster rides! - see subject with close-talk microphone and p-mic positioned at his larynx with the black Velcro strap around his neck) [15,16]. Again, the focus was on analysis of speech motor characteristics of speech under stress, illustrating how g-force, motion, as well as physical/cognitive stress impacts speech production.
Can We Identify Speaker Content While Screaming?
 Recently, the controversial question of whether speaker identification technology is mature enough to be used for screaming audio recordings has come into the spotlight [17], along with subsequent forensic analysis of screams for use in recent courtroom testimony [18]. While many changes in production have been documented in earlier studies on speech under stress, unique abnormalities come to the picture when dealing with "screaming speech". In this part of this letter, we intend to point out the difficulty in recognizing speaker identities when the speech used in testing consists of instances of the speaker screaming. A number of subjects from the Center for Robust Speech Systems at the University of Texas at Dallas participated in a small "screaming" data collection. Both spontaneous and text-dependent neutral speech was recorded for each subject. The subjects were also asked to scream during recording sessions.
Recently, the controversial question of whether speaker identification technology is mature enough to be used for screaming audio recordings has come into the spotlight [17], along with subsequent forensic analysis of screams for use in recent courtroom testimony [18]. While many changes in production have been documented in earlier studies on speech under stress, unique abnormalities come to the picture when dealing with "screaming speech". In this part of this letter, we intend to point out the difficulty in recognizing speaker identities when the speech used in testing consists of instances of the speaker screaming. A number of subjects from the Center for Robust Speech Systems at the University of Texas at Dallas participated in a small "screaming" data collection. Both spontaneous and text-dependent neutral speech was recorded for each subject. The subjects were also asked to scream during recording sessions.
Issues with collecting scream data:
 One of the challenges faced in capturing audio data for this domain is that there is no unique way to define a scream. Even when subjects are asked to imagine they are in a particular situation described to them in detail, it is sometimes difficult for them to scream naturally. The "flavors" of a scream could include (not comprehensive!):
One of the challenges faced in capturing audio data for this domain is that there is no unique way to define a scream. Even when subjects are asked to imagine they are in a particular situation described to them in detail, it is sometimes difficult for them to scream naturally. The "flavors" of a scream could include (not comprehensive!):
Prior studies:

Experiments and results:

References
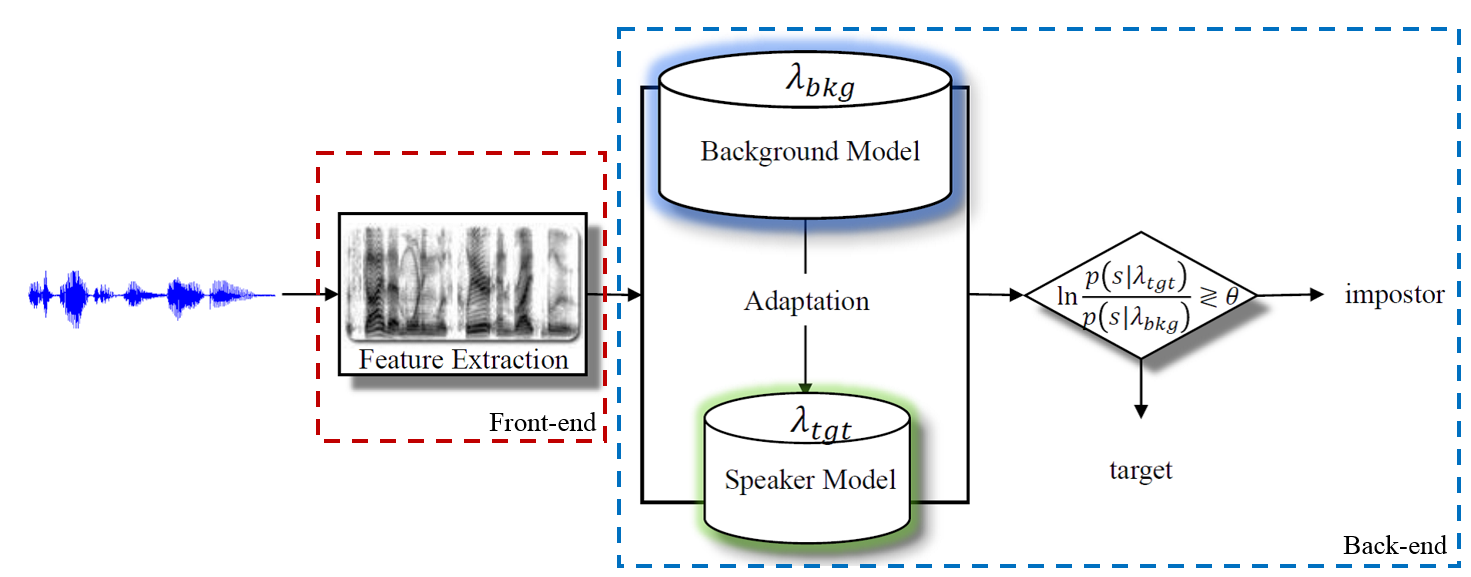{kind=link}