Figure 1: Reconstruction of a sentence.
Welcome to the Winter 2014 edition of the IEEE Speech and Language Processing Technical Committee's Newsletter! This issue of the newsletter includes 8 articles and announcements from 10 contributors, including our own staff reporters and editors. Thank you all for your contributions! This issue includes news about IEEE journals and recent workshops, SLTC call for nominations, and individual contributions.
We believe the newsletter is an ideal forum for updates, reports, announcements and editorials which don't fit well with traditional journals. We welcome your contributions, as well as calls for papers, job announcements, comments and suggestions.
To subscribe to the Newsletter, send an email with the command "subscribe speechnewsdist" in the message body to listserv [at] listserv (dot) ieee [dot] org.
Florian Metze, Editor-in-chief
William Campbell, Editor
Haizhou Li, Editor
Patrick Nguyen, Editor
Douglas O'Shaughnessy
ASRU 2015 welcomes proposals for challenge tasks. In a challenge task, participants compete or collaborate to accomplish a common or shared task. The results of the challenge will be presented at the ASRU workshop event in the form of papers reporting the achievements of the participants, individually and/or as a whole. We invite organizers to concretely propose such challenge tasks in the form of a 1-2 page proposal.
On behalf of the IEEE SLT-2014 organizing committee, we welcome you to the 2014 IEEE Workshop on Spoken Language Technology (SLT) in South Lake Tahoe, Nevada December 7-10, 2014. This is the fifth biannual SLT workshop – which first began in Aruba (2006), then Goa, India (2008), Berkeley, California (USA) (2010), and most recently Miami, Florida (USA) (2012). This year we will be hosting the IEEE SLT in South Lake Tahoe at the Harvey’s Lake Tahoe Resort, with beautiful views of Lake Tahoe and minutes from Heavenly Valley Ski area. The SLT-2014 Organizing Committee has worked extensively on all aspects of the technical and social programs, and we promise this to be a memorable experience with an outstanding collection of quality papers and talks, along with the breathtaking location of Lake Tahoe.
The 15th Interspeech Conference was recently hosted in Singapore from September 14-18th, 2014. In this article, we highlight a few interesting papers and themes from the conference.
Cortana is the most personal assistant who learns about her user to provide a truly personalized experience. Behind the scenes, there's a wide range of speech and language technology components which make the natural interaction with Cortana possible. Personalization of the speech experience happens seamlessly while the user simply experiences better speech recognition accuracy and a more natural interface. Here are a few examples of recent research from our labs.
The Spectrogram Inversion Toolbox allows one to create spectrograms from audio, and, more importantly, estimate the audio that generates any given spectrogram. This is useful because often one wants to think about, and modify sounds in the spectrogram domain.
The aim of this special issue is to provide a forum for in-depth, journal-level work on dialogue state tracking. This issue welcomes papers covering any topic relevant to dialogue state tracking.
We would like to invite you to attend our one-day workshop on "assistive speech and signal processing" which we are organising on Monday 24 November 2014 in Leuven, Belgium. Information about program and registration can be found here.
The development of automatic speech recognition able to perform well across a variety of acoustic environments and recording scenarios on natural conversational speech is a holy grail of the speech research community. Previous work in the literature has shown that automatic speech recognition (ASR) performance degrades on microphone recordings especially when data used for training is mismatched with data used in testing. IARPA is announcing a challenge, with monetary awards, to develop approaches to mitigate the effects of these conditions. Participants will have the opportunity to evaluate their techniques on a common set of challenging data that includes significant room noise and reverberation.
MediaEval is a benchmarking initiative dedicated to developing and evaluating new algorithms and technologies for multimedia access and retrieval. It offers tasks to the research community that related to human and social aspects of multimedia. MediaEval is now calling for proposals for tasks to run in the 2015 benchmarking season. The proposal consists of a description of the motivation for the task, and challenges that task participants must address, as well as information on the data and evaluation methodology to be used. The proposal also includes a statement of how the task is related to MediaEval (i.e., its human or social component), and how it extends the state of the art in an area related to multimedia indexing, search or other technologies that support users in access multimedia collections.
SLTC Newsletter, August 2014
Welcome to the final SLTC Newsletter of the year. This is also my last column as Chair, as January 2015 will see Vice-Chair Bhuvana Ramabhadran take over as the new Chair of SLTC for the next two years.
We just finished a successful election to renew our committee. We may well have had the largest number of candidates ever this year – 70 running for only 18 open positions. As a result, the competition was quite high. To all those who submitted a nomination, I thank you, and hope that some of the disappointed will try again next autumn when we have our 2015 election.
The incoming members elected for 2015-2017 are 5 re-elected and 13 newcomers:
Please recall that we elect members by area (i.e., the ten areas noted above), in order to ensure that we have a good breadth of expertise for evaluating papers submitted to ICASSP. We adjust our member numbers periodically to match the areas of submissions.
As for ICASSP-2015, our speech and langauge areas received 547 papers to evaluate. Our areas usually form the domain with the highest number of papers for all of ICASSP. Each submission will be reviewed by four experts, of which one will be a current (or newly elected) SLTC member. Each member, after reviewing a paper, will do a “meta-review” of that paper, examining all four reviews, to help arrive at a recommendation to accept the paper or not. We have six “Area Chairs” on the SLTC (Björn Schuller, Bowen Zhou, Tim Fingscheidt, Michiel Bacchiani, Haizhou Li, and Karen Livescu), who will supervise the review assignments and decision-making process, along with the Chair and the Vice-Chair.
As the weather turns cooler (at least for the majority of us who live in the Northern Hemisphere), we look forward to the upcoming IEEE Spoken Language Technology (SLT) Workshop, to be held at held at Harvey’s Lake Tahoe Hotel in scenic Lake Tahoe, Nevada (Dec. 7-10, 2014; www.slt2014.org). The main theme of the workshop is machine learning in spoken language technologies. With so many recent and fuiture speech and language meetings being held outside the US, this is a golden opportunity to visit a beautiful American location and keep up-to-date technically at the same time. For next year’s ICASSP (April 19-24, 2015 in Brisbane, our first return to Australia, since Adelaide in 1994), if you have not signed up as reviewer, and wish to participate, send me a request. Papers will be sent out for review in mid-November (with a deadline in mid-December).
Next year’s IEEE Automatic Speech Recognition and Understanding (ASRU) Workshop will be held in Scottsdale, Arizona, Dec. 13-17, 2015. Also, please note the next Interspeech conference in Dresden, Germany, Sept. 6-10, 2015.
Lastly, if you have any interest in helping to organize SLT-2016, let us know. The SLTC will consider bids early next year.
In closing, please consider participating at SLT this year in Tahoe and at next year’s ICASSP in Brisbane. We look forward to meeting friends and colleagues at these exciting locations.
Best wishes,
Douglas O'Shaughnessy
Douglas O'Shaughnessy is the Chair of the Speech and Language Processing Technical Committee.
SLTC Newsletter, August 2014
ASRU 2015 welcomes proposals for challenge tasks. In a challenge task, participants compete or collaborate to accomplish a common or shared task. The results of the challenge will be presented at the ASRU workshop event in the form of papers reporting the achievements of the participants, individually and/or as a whole. We invite organizers to concretely propose such challenge tasks in the form of a 1-2 page proposal. The proposal should include a description of
Participants will report their achievements in the form of regular format paper submissions to the ASRU workshop. These submissions will undergo the normal ASRU review process, but the organizers can suggest reviewers that would be particularly insightful for the challenge subject matter. Accepted papers will be organized in a special session at the conference (in poster format; the only format used at ASRU). The accepted papers will appear in the ASRU proceedings. Given the possibly lengthy process of organizing and executing a special challenge, prospective organizers are encouraged to submit proposals as soon as possible. The ASRU technical program committee will make acceptance decisions based on a rolling schedule -- i.e., proposals are reviewed as soon as they come in. Challenge proposals should be sent to Technical Program co-chair Michiel Bacchiani at michiel@google.com, and will be accepted until the end of 2014.
Michiel Bacchiani is Challenge Chair for ASRU 2015.
SLTC Newsletter, November 2014
On behalf of the IEEE SLT-2014 organizing committee, we welcome you to the 2014 IEEE Workshop on Spoken Language Technology (SLT) in South Lake Tahoe, Nevada December 7-10, 2014. This is the fifth biannual SLT workshop – which first began in Aruba (2006), then Goa, India (2008), Berkeley, California (USA) (2010), and most recently Miami, Florida (USA) (2012). This year we will be hosting the IEEE SLT in South Lake Tahoe at the Harvey’s Lake Tahoe Resort, with beautiful views of Lake Tahoe and minutes from Heavenly Valley Ski area. The SLT-2014 Organizing Committee has worked extensively on all aspects of the technical and social programs, and we promise this to be a memorable experience with an outstanding collection of quality papers and talks, along with the breathtaking location of Lake Tahoe.
The main theme of the workshop is “machine learning in spoken language technologies”. Every effort has also been made to increase both intra and inter community interactions. We have reached out to both ISCA – (International Speech Communications Association), and ACL – (American Computational Linguistics society) for co-technical sponsorship including allowing BOTH ISCA and ACL members to register at the same rate as IEEE members. ISCA has also generously provided support for several student travel grants. We have also targeted members of NIPS (Neural Information Processing Systems foundation) to encourage their participation as well.
The second goal reflects our interest for “increased intra communication interaction”. Here, panel discussions have been initiated before the conference to capture attendees’ interests/questions/comments, to be included in panel discussions. In addition, two miniSIGs (special interest group discussion/activity) have been organized for small discussion to allow SLT attendees to organize themselves in smaller groups and have more involved discussions.
We have arranged for a very exciting technical program this year. We received 208 paper submissions and after a rigorous review process, accepted 103 papers. These papers cover a wide range of topics in spoken language technology. We would like to thank the technical program co-chairs, Steve Young, Pascale Fung, Dilek Hakkani-Tur, and Haizhou Li for their careful work in overseeing the paper reviews and putting together an excellent program. We are also grateful for all the 127 reviewers for their timely work, which allowed for at least 3 blind reviews for all papers.
The technical program for SLT begins with two tutorials on Sunday afternoon (included in your registration fees), the first being on Deep Learning and Continuous Representations for Language Processing (Xiaodong He and Scott Wen-Tau Yih), the second is on Multi-View Learning of Representations for Speech and Language (Karen Livescu, Raman Arora, Kevin Gimpel). The special interest group (SIG) discussion meetings are set for Sunday (21:30-23:00) and Monday evenings (20:00-23:00) – focused on Dialog State Tracking Challenge (Matthew Henderson, Blaise Thomson, Jason Williams) with summary reports which will be made available online to all attendees after the workshop. The technical program includes three keynote talks each morning by Jure Leskovec: Language as Window into Social Dynamics of Online Communities, Stephen Clark: The Theory and Practice of Compositional Distributed Semantics, and Tara Sainath: Deep Learning Advances, Challenges and Future Directions for Speech and Language Processing. There are two invited talks by Fei Sha (Monday) and Lukas Burget (Tuesday), as well as two organized panels organized by Panel Chair Yang Liu: “Machine learning and big data in SLT: past, current, and the future" (Monday) and "Next generation SLT scientists and engineers" (Tuesday). A total of 10 poster sessions have been organized that span the range of topics in spoken language technology. Tuesday afternoon will also include the SLT DEMO Session, organized by Demo Session co-Chairs Alex Rudnicky and Sachin Kajarekar, which includes 22 demonstrations all of which went through formal proposal evaluation before being accepted for presentation. The closing ceremony will be 11:45-12:45 on Wed.
The social program includes the Welcome Reception on Sunday evening (18:30-20:00), and the workshop Banquet on Tuesday evening (19:00 – 21:00) – with additional social events and skiing options for Wed. afternoon. We also would like to express our gratitude to the local organization co-chairs Asli Celikyilmaz, Yun Lei, Stephanie Pancoast for helping with the ground work and logistics. They were instrumental in the success of the workshop. We would like to extend our sincere thanks to Ozlem Kalinli who served as Finance chair, publicity chairs (Julia Hirschberg and Agustin Gravano) for help in online webpage content and helping to advertise the workshop and increase the paper submissions/participation, publication chair (Shri Narayanan) for the workshop abstract book and memory stick program, our Europe and Asia liaisons (Isabel Trancoso, Hermann Ney, Lin Shan Lee, Sadaoki Furui) for helping to promote the workshop globally, and finally Gokhan Tur and Bhuvana Ramabhadran for their time in providing answers/feedback for countless questions. We would not have done it without the help of Lance Cotton, Michael Simon, and Billene Mercer from CMS, as well as Vita Feuerstein and Nicole Allen from IEEE – Signal Processing Society for their extensive help and support.
Finally, and maybe most importantly, the SLT workshop would not be possible without the generous contributions of our sponsors. The Sponsorship Co-chairs (Jerome Bellagarda, Xiao Li, Ananth Sankar) worked extensively with corporate partners to build a truly comprehensive industrial sponsor program. With larger conferences such as IEEE ICASSP and ISCA INTERSPEECH, it is generally possible to achieve a good fiscal balance due to the large attendance. While this SLT has seen a record number of attendees with over 200, workshops such as SLT and ASRU generally have a restricted limit on attendance, so without the generous support of external sponsors, it would not be possible to meet the fiscal constraints in holding the workshop. We would like to express our sincere thanks to Microsoft (Platinum Sponsor), Nuance and Google (Gold Sponsors), Sony, Amazon and Facebook (Silver Sponsors), IBM Research, Bosch, and ETS (Bronze Sponsors) for their support of SLT-2014.
We look forward to seeing you in South Lake Tahoe, and hope this workshop and your stay will be a memorable one.
John H. L. Hansen (University of Texas at Dallas) and Murat Akbacak (Microsoft) are the General Chairs of SLT2014.
SLTC Newsletter, November 2014
The 15th Interspeech Conference was recently hosted in Singapore from September 14-18th, 2014. In this article, we highlight a few interesting papers and themes from the conference.
Deep Learning continues to remain a hot research area in the speech community. Google published a paper on using Long Short-Term Memory (LSTM) Recurrent Neural Networks for Voice Search [1]. This is the first application of LSTMs to large vocabulary tasks. The authors reported gains of 10% relative in WER, which is one of the largest gains to date since DNNs were introduced for acoustic modeling.
In addition, Microsoft published a paper on quantizing gradients to one-bit during stochastic gradient descent training. This allows SGD to be parallelized on GPUs. The authors report that this method allows for speedups of up to 10 times, with a small loss in accuracy.
One of the attractive properties of DNNs is that they perform “feature learning” at different hierarchical layers. This questions if a DNN can be trained directly from the raw-waveform, instead of using MFCC or log-mel features. A paper from RWTH-Aachen showed that by using more training data and a stronger non-linearity with rectified linear units, DNNs trained with the raw-signal can come very close in performance to DNNs trained with log-mel features [3].
Papers related to the IARPA Babel program, including keyword spotting and low-resource ASR, were also a hot topic at the conference.
One of the challenges in the Babel program is the lack of supervised training data. To increase the amount of data used for acoustic model training, researchers at Cambrige University [4] looks at augmenting training data through semi-supervised training and vocal tract length perturbation. Given only 10 hours of transcribed data, the paper shows that using data augmentation techniques, KWS results can be improved.
Traditional front-ends for speech recognition often use features that map speech from speakers with varying vocal tract lengths into a canonical space. Speaker-id tasks, however, look at use features that carry information about the vocal-source. Low-resource languages, such as Zulu and Lao, have sounds whose generation co-occur with voice quality. Thus, research from IBM looked at augmenting traditional ASR features with vocal-source features [5], and show gains compared to just traditional ASR features on both Zulu and Lao.
Tara N. Sainath is a staff writer for the SLTC Newsletter. She is a research scientist at Google.
SLTC Newsletter, November 2014
Cortana is the most personal assistant who learns about her user to provide a truly personalized experience. Behind the scenes, there's a wide range of speech and language technology components which make the natural interaction with Cortana possible. Personalization of the speech experience happens seamlessly while the user simply experiences better speech recognition accuracy and a more natural interface. Here are a few examples of recent research from our labs.
Speaker independent models are designed to work well across the span of the user demographic but each interaction represents an individual use case with characteristics in accent, articulation, context, devices and acoustic environment. This means that there is significant potential gain in recognition accuracy from personalized models. However, with tens of millions of parameters in the DNN models, storing personalized models in a large-scale deployment becomes a challenge of practical limitations and scalability. Xue et al. [1] describes the method of singular value decomposition (SVD) bottleneck adaptation where a matrix containing the speaker information is inserted between low-rank matrices in each layer. With this approach, adaptation can happen by updating only a few small matrices for each speaker. With only a small number of speaker-specific parameters to maintain, the storage requirement for the personalized model is less than 1% of the original model thus dramatically reducing the cost of personalized models while maintaining accuracy gains.
One of the key sources for improving language models is data from real live usage. Automated unsupervised language model (LM) adaptation based on anonymized live service data can provide significant recognition accuracy improvements without the cost of manual transcriptions if you can suppress the error attractors and retain the most valuable data. In [2], a framework for discriminatively filtering adaptation training data is presented. An initial updated LM is generated by incorporating live user data. The framework then learns recognition regression patterns between the recognition results from the baseline LM and the initial adapted LM focusing on differences in LM scores. Error attractor n-grams with their frequencies are computed from the regression pairs and applied to the data filtering process and a new adapted LM is trained on the filtered adaptation data leading to substantial recognition error reduction.
With the wider adoption of our devices and services, Cortana is exposed to more variation of accents from a diverse set of users. Accented speech is challenging because of the large number of possible pronunciation variants and the mismatch between the reference model and the incoming speech. [3] presents a multi-accent deep neural network acoustic model targeted at improving speech recognition accuracy for accented speakers. Kullback-Leibler divergence (KLD) regularized model adaptation is applied to train an accent-specific top layer while avoiding overfitting. This top layer models the accent specific information whereas the bottom hidden layers are shared across accents. This allows for maximum data sharing of speech across accents. Building on top of this work, we have now taught Cortana how to better understand non-native accented speech.
Fil Alleva and Michael Tjalve are with Microsoft’s speech technology group.
SLTC Newsletter, November 2014
The Spectrogram Inversion Toolbox allows one to create spectrograms from audio, and, more importantly, estimate the audio that generates any given spectrogram. This is useful because often one wants to think about, and modify sounds in the spectrogram domain.
Spectrograms are important for speech. Not only do spectrograms make it easy to visualize speech, they are at the core of many different kinds of processing algorithms: e.g. speech enhancement, de-noising, computational auditory scene analysis, and audio morphing. In each case we compute a spectrogram, modify it, and then for debugging or further analysis we want to convert it back into a waveform so we can listen to the result.
There are two big problems with spectrogram inversion: most importantly, one (generally) drops the phase when computing a spectrogram, and two not every (spectrogram) image corresponds to a valid waveform. When modifying a spectrogram, even something as simple as attenuating portions of it, one is left with an array of data which might not correspond to the spectrogram of any real waveform. With overlapping windows, a spectrogram is a redundant representation,
This toolbox finds the waveform that has a magnitude spectrogram most like the input spectrogram. There are three different kinds of solutions to the spectrogram inversion problem: zero phase, iterative, and initializing with linear phase.
The easiest solution is to do the spectrogram inversion assuming some phase (like 0). Back in the time domain you get an answer, but there is a lot of destructive interference because the segments of adjacent frames do not have consistent phase. Some people advocate starting with a random phase.
A better solution to this problem is to use an iterative algorithm proposed by Griffin and Lim many decades ago. It does converge, but slowly.
An even better solution is to do the inversion, explicitly looking for a good set of phases. This toolbox does that, after the inverse Fourier transform of each slice, by finding the best time delay so the new frame and the summed frames to now are consistent. This is equivalent to starting with some arbitrary linear phase. The effect of this is to reduce the reconstruction error by an order of magnitude. Hurray.
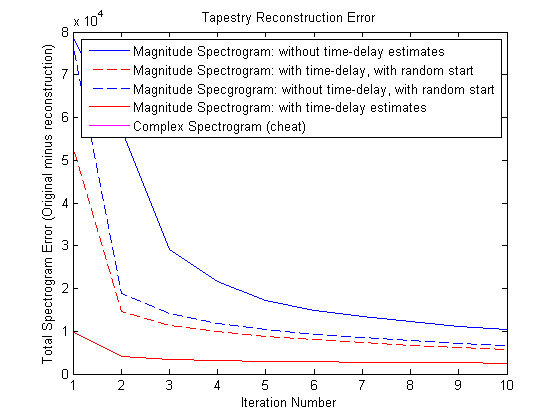
The attached graph demonstrates the algorithm’s performance. The plot uses a sentence (from the TIMIT database.)
Figure 1: Reconstruction of a sentence.
The goal is to find a waveform whose magnitude spectrogram is as close as possible to the original one. The error is the difference between the original and the reconstructed spectrogram. Lower is better.
The no-iteration solution is the first point on the upper line. But with iterations the error goes down dramatically. Starting with a random phase does better. The best results are possible with the phase-finding heuristic.
The basic iterative algorithm for this code is based on
An important efficiency improvement is based on estimating a most harmonious linear phase when doing the first iteration (Griffin and Lim assumes zero phase). This idea was first used in:
and later more formally described in this paper:
This idea is very similar to the approach used in PSOLA. Each new frame of the waveform is slid left and right along the existing waveform to look for the best fit.
The Spectogram Inversion Toolbox is available for download at http://research.microsoft.com/en-US/downloads/5ee40a69-6bf1-43df-8ef4-3fb125815856/default.aspx
This code was written during the 2014 Telluride Neuromorphic Congition Engineering Workshop.
Malcolm Slaney is with Microsoft Research.
SLTC Newsletter, November 2014
Conversational systems are increasingly becoming a part of daily life, with examples including Apple's Siri, Google Now, Nuance Dragon Go, Xbox and Cortana from Microsoft, and numerous new entrants. Many conversational systems include a dialogue state tracking function, which estimates relevant aspects of the interaction such as the user's goal, level of frustration, trust towards the system, etc, given all of the dialogue history so far. For example, in a tourist information system, the dialogue state might indicate the type of business the user is searching for (pub, restaurant, coffee shop), their desired price range and type of food served. Dialogue state tracking is difficult because automatic speech recognition (ASR) and spoken language understanding (SLU) errors are common, and can cause the system to misunderstand the user. At the same time, state tracking is crucial because the system relies on the estimated dialogue state to choose actions -- for example, which restaurants to suggest.
Most commercial systems use hand-crafted heuristics for state tracking, selecting the SLU result with the highest confidence score, and discarding alternatives. In contrast, statistical approaches consider many hypotheses for the dialogue state. By exploiting correlations between turns and information from external data sources -- such as maps, knowledge bases, or models of past dialogues -- statistical approaches can overcome some SLU errors.
Although dialogue state tracking has been an active area of study for more than a decade, there has been a flurry of new work in the past 2 years. This has been driven in part by the availability of common corpora and evaluation measures provided by a series of three research community challenge tasks called the Dialogue State Tracking Challenge. With these resources, researchers are able to study dialogue state tracking without investing the time and effort required to build and operate a spoken dialogue system. Shared resources also allow direct comparison of methods across research groups. Results from the Dialogue State Tracking Challenge have been presented at special sessions in SIGDIAL 2013, SIGDIAL 2014, and IEEE SLT 2014.
The aim of this special issue is to provide a forum for in-depth, journal-level work on dialogue state tracking. This issue welcomes papers covering any topic relevant to dialogue state tracking. Specific examples include (but are not limited to):
Submissions should report on new work, or substantially expand on previously published work with additional experiments, analysis, or important detail. Previously-published aspects may be included but should be clearly indicated.
All data from the dialogue state tracking challenge series continues to be available for use, including the dialogue data itself, scripts for evaluation and baseline trackers, raw output from trackers entered in the challenges, and performance summaries. If your work is on dialogue state tracking for information-seeking dialogues and/or you think the data is appropriate, you are strongly encouraged to report results on these data, to enable comparison. The dialogue state tracking challenge data is available here:
Papers should be submitted on the Dialogue & Discourse journal website, following instructions and formatting guidelines given there: http://www.dialogue-and-discourse.org/submission.shtml
Submitted papers will be reviewed according to the Dialogue & Discourse reviewing criteria and appropriateness to the topic of the special issue.
Contact Jason Williams (jason.williams@microsoft.com) for further information about this call for papers.
SLTC Newsletter, November 2014
Dear colleague,
We would like to invite you to attend our one-day workshop on "assistive speech and signal processing" which we are organising on Monday 24 November 2014 in Leuven, Belgium.
Information about program and registration can be found here.
Feel free to share this invitation!
Participation is free, but registration is required (see link). Note we can still add a few posters or demo to the program if you are interested to present your work.
The venue is Faculty Club in Leuven (http://www.facultyclub.be/en/), located in Leuven's historic beguinage. There are plenty of hotels in Leuven, but the Begijnhof Hotel (http://www.bchotel.be/) is conveniently right next to the venue. Leuven's railway station is easily reached by train from Brussels airport (15 minute trip, up to 4 trains per hour) as well as from the Thalys, ICE, Eurostar and TGV terminals at Brussels South (25 minute trip).
Hope to see you on 24 November,
Hugo Van hamme on behalf of the ALADIN team.
Hugo Van hamme is with KU Leuven - Dept. ESAT.
SLTC Newsletter, November 2014
The development of automatic speech recognition able to perform well across a variety of acoustic environments and recording scenarios on natural conversational speech is a holy grail of the speech research community. Previous work in the literature has shown that automatic speech recognition (ASR) performance degrades on microphone recordings especially when data used for training is mismatched with data used in testing. IARPA is announcing a challenge, with monetary awards, to develop approaches to mitigate the effects of these conditions. Participants will have the opportunity to evaluate their techniques on a common set of challenging data that includes significant room noise and reverberation.
Further Information To learn more about ASpIRE, including rules and eligibility requirements, visit http://www.iarpa.gov/ or follow @IARPAnews on Twitter (Reference #ASpIRE) for updates.
Mary Harper is with the Intelligence Advance Research Projects Activity.
SLTC Newsletter, November 2014
MediaEval is a benchmarking initiative dedicated to developing and evaluating new algorithms and technologies for multimedia access and retrieval. It offers tasks to the research community that related to human and social aspects of multimedia. MediaEval emphasizes the 'multi' in multimedia and seeks tasks involving multiple modalities, including speech, audio, visual content, tags, users, and context.
The MediaEval benchmarking year culminates with a workshop at which task results are presented and discussed. The MediaEval 2015 Workshop will be held 14-15 September 2015 as a Satellite Workshop of Interspeech 2015.
MediaEval is now calling for proposals for tasks to run in the 2015 benchmarking season. The proposal consists of a description of the motivation for the task, and challenges that task participants must address, as well as information on the data and evaluation methodology to be used. The proposal also includes a statement of how the task is related to MediaEval (i.e., its human or social component), and how it extends the state of the art in an area related to multimedia indexing, search or other technologies that support users in access multimedia collections.
For more detailed information about the content of the task proposal, please see: http://multimediaeval.org/mediaeval2015
Task proposals are chosen on the basis of their feasibility, their match with the topical focus of MediaEval, and also according to the outcome of a survey circulated to the wider multimedia research community. First data release for MediaEval 2015 tasks is due May 1.
For more information about MediaEval see http://multimediaeval.org or contact Martha Larson m.a.larson@tudelft.nl.
Martha Larson is an Assistant Professor in the Multimedia Computing Group at TU Delft.