
Machine Learning Techniques for Head-Related Transfer Function Individualization: A Comprehensive Survey

By Davide Fantini, Michele Geronazzo, Federico Avanzini, Stavros Ntalampiras
Contributed by Davide Fantini and co-authors, based on the IEEEXplore® article, “A Survey on Machine Learning Techniques for Head-Related Transfer Function Individualization”, published in the IEEE Open Journal of Signal Processing in January 2025, and the SPS Webinar titled “Machine Learning Techniques for Head-Related Transfer Function Individualization: A Comprehensive Survey”, available on the SPS Resource Center.
The Individualization Problem
Immersive spatial audio is essential for virtual reality, assistive devices [1], and the rising hearablestechnologies. Central to this experience are Head-Related Transfer Functions (HRTFs) [2], which enable headphone-based spatial audio by modeling the acoustic interactions between sound waves and individual human anatomy to provide spatial hearing cues.
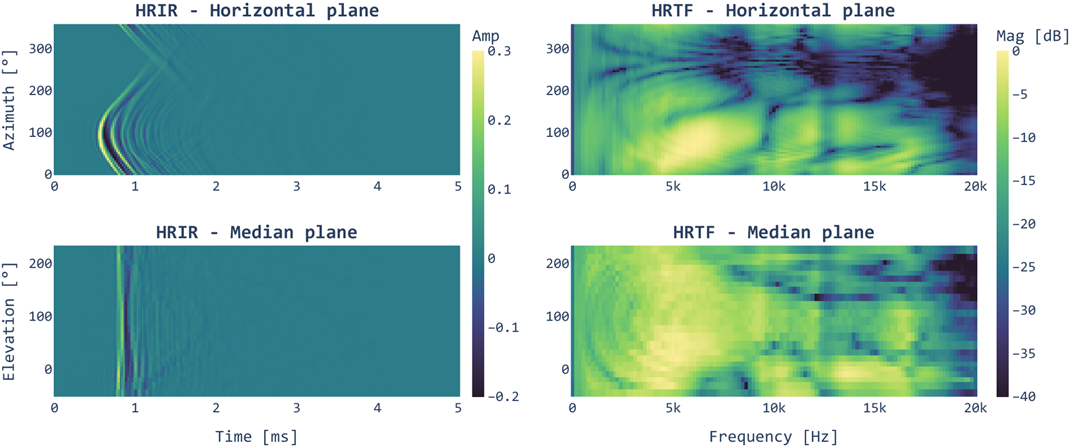
Figure 1: Example of HRIRs (left) and HRTFs (right) in the horizontal (top) and median (bottom) planes from the SONICOM dataset [5]
Because HRTFs depend on individual anatomy, using a generic HRTF often degrades the auditory experience, leading to poor localization accuracy, front-back confusion, and lack of sound externalization [3]. However, HRTF acoustic measurement is impractical, requiring expensive equipment (e.g., anechoic chambers), time-consuming sessions, and experienced personnel. To bridge this gap, researchers are turning to machine learning (ML) for signal processing to personalize HRTFs.
Surveying the Literature
To map the rapidly evolving landscape, our survey leverages the PRISMA methodology [4] to extensively search academic databases and identify relevant peer-reviewed journal and conference papers. After carefully screening articles against predetermined criteria, we included 76 studies on ML-based HRTF individualization. We systematically analyzed and categorized these papers to identify trends and challenges, and propose future research directions.
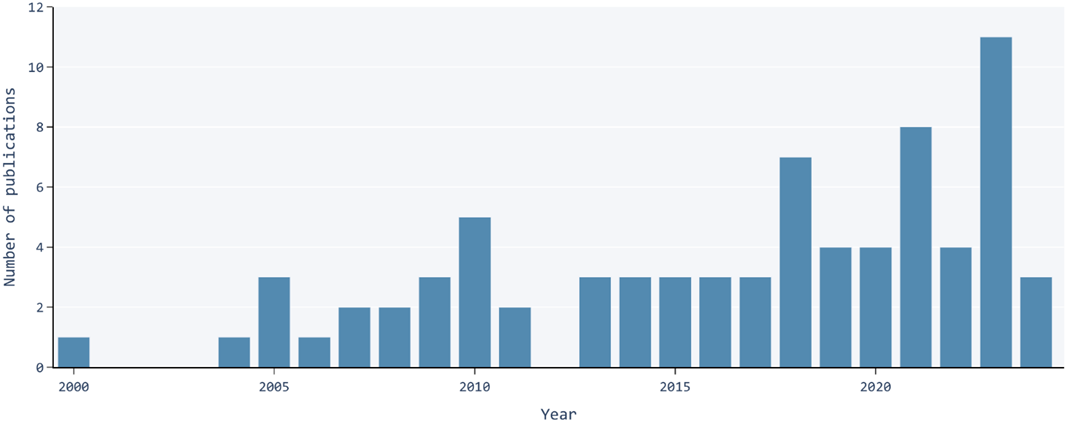
Figure 2: Temporal distribution of the studies identified in the survey.
Machine Learning for HRTF Individualization
Our survey categorizes ML-based HRTF individualization into the standard stages of the ML workflow.
The Inputs
The first crucial step is acquiring input data meaningful for HRTFs. Data types can be categorized into:
- Morphological Data: The most common approach, utilizing anthropometric parameters defined by distances between body points. Preprocessing involves feature scaling and selection, with occasional dimensionality reduction.
- Visual Data: Driven by computer vision advances, head images and 3D scans are gaining traction. Preprocessing include resolution scaling, data augmentation, edge detection, and voxelization.
- Perceptual Feedback: Some methods personalize the HRTF based on listener feedback, though this is uncommon in ML approaches.
- Binaural Recordings: A rare but emerging approach utilizes in-the-wild recordings captured via in-ear microphones to estimate HRTFs.
The Outputs
While ML models typically output HRTF magnitude, researchers also explored Head-Related Impulse Response (HRIR), Directional Transfer Functions (DTF), and Pinna-Related Transfer Function (PRTF). For a simplified learning, output is often constrained in spatial and frequency dimensions. Because HRTFs are highly dimensional, dimensionality reduction techniques (e.g., Principal Component Analysis (PCA), Autoencoders, spherical harmonics) are adopted to map data into manageable feature space.
The Models
The field includes a diverse spectrum of ML models. Early methods leveraged linear regression, but its limitations drove a shift toward advanced algorithms, ranging from tree-based models to neural networks. The adoption of the latter have evolved from shallow networks to deeper and sophisticated architectures, like Recurrent and Convolutional Neural Networks (RNNs and CNNs), and transformers. These advancements favored the adoption of visual data to capture the complex relationships between anatomy and HRTFs. However, a tension remains: deep learning thrives on massive datasets, which are notably missing in the HRTF field.
The Training
Standard ML models are unable to handle the multidimensional HRTFs structure. Researchers address this by training multiple models or a single model with additional input features. Partitioning strategies like holdout and cross-validation are standard, but hyperparameter tuning is underreported in the literature. To combat data scarcity and prevent overfitting, dataset combination strategies [5] are effective, provided that cross-dataset differences are harmonized.
The Evaluation
Evaluating personalized HRTFs is multifaceted. While Spectral Distortion (SD) dominates as objective metric, subjective evaluation remains essential given the perceptual HRTF nature. However, only a minority of studies implemented headphone-based localization tests. To mitigate the practical hurdles of listening tests, researchers leverage auditory computational models (see the Auditory Modeling Toolbox, AMT).
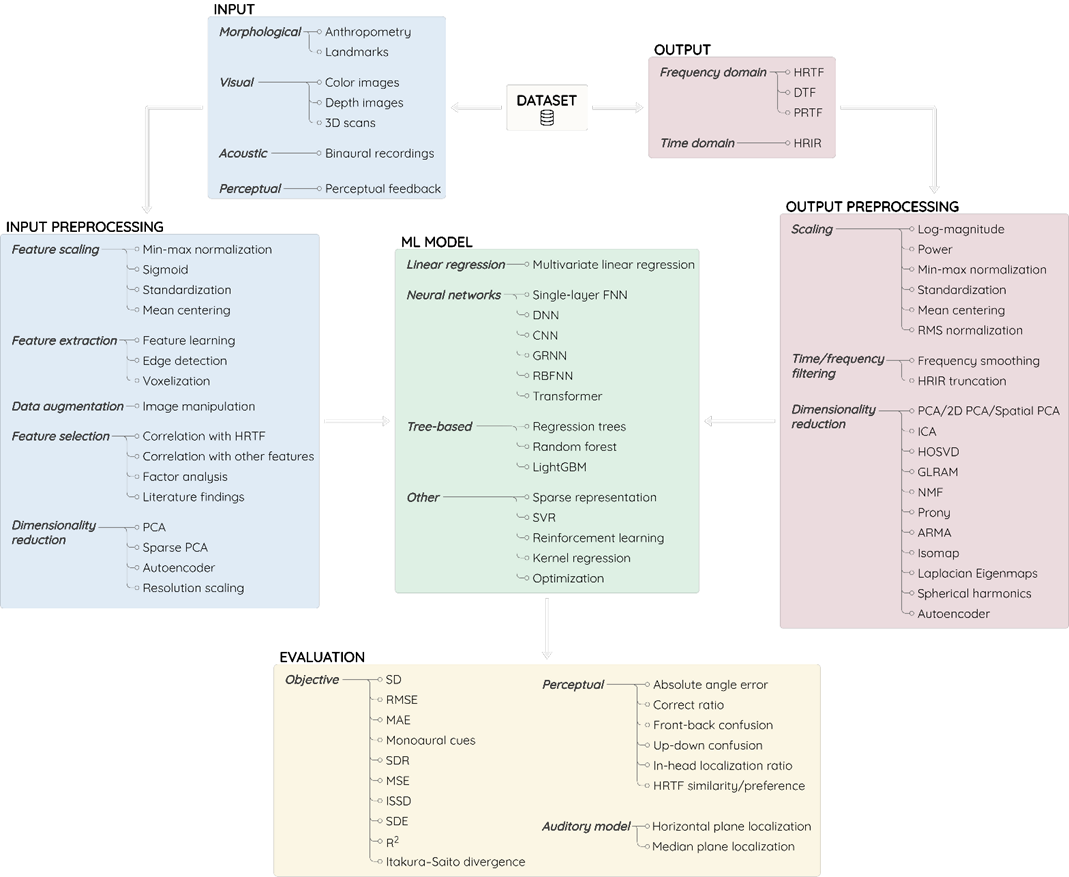
Figure 3: ML workflow for HRTF individualization with the main options adopted by the identified studies.
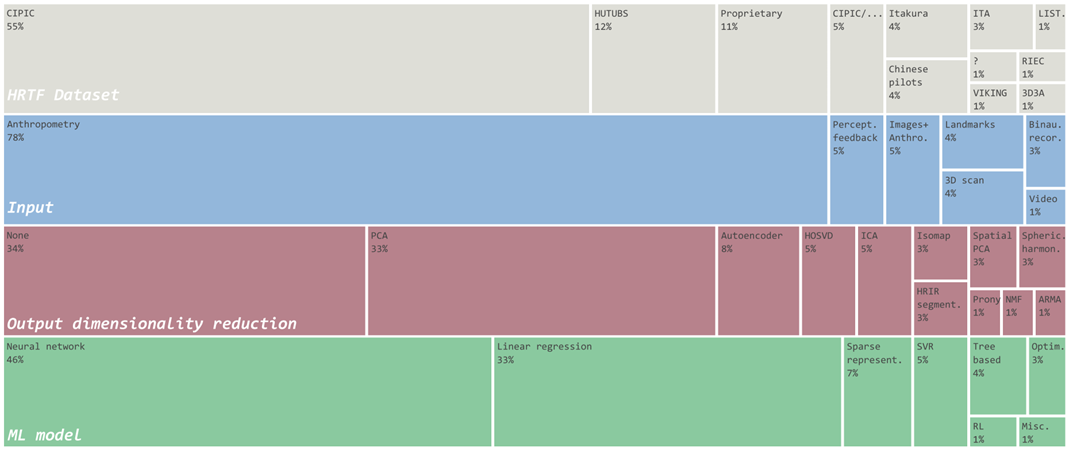
Figure 4: Distribution of HRTF datasets, input types, output dimensionality reduction techniques, and ML models for the identified studies.
Trends, Bottlenecks, and the Road Ahead
Moving beyond individual studies, our survey highlights broader trends, bottlenecks, and future research directions.
The Need for Standardization
Despite commonalities across the studies—CIPIC dataset [6], anthropometry, neural networks, and SD—the field suffers from severe fragmentation. Unlike related fields that thrive on common benchmarks, HRTF individualization lacks standardized protocols, preventing reliable comparisons. Efforts like the Listener Acoustic Personalization (LAP) challenge—including HRTF individualization on its roadmap—are paving the way for community-driven standardization.
Data Scarcity
Limited HRTF datasets restrict the potential of data-hungry ML models. Future progress requires collecting more data, exploring numerically simulated HRTFs [7], and adopting transfer learning and data augmentation/combination strategies.
Anthropometry Limitations
Anthropometry remains the prevalent input, despite notable limitations—debated comprehensiveness, repeatability errors, ambiguous definitions, and impractical manual measurement. Researchers are addressing these limitations via improved anthropometric specifications [8], automated extraction algorithms [9], and the use of images and 3D scans.
Performance Comparison
While standardization issues complicate systematic comparisons, our survey reports a qualitative analysis of SD distributions suggesting that neural networks generally outperform other methods. Tree-based models also show untapped potential despite the scarce adoption.
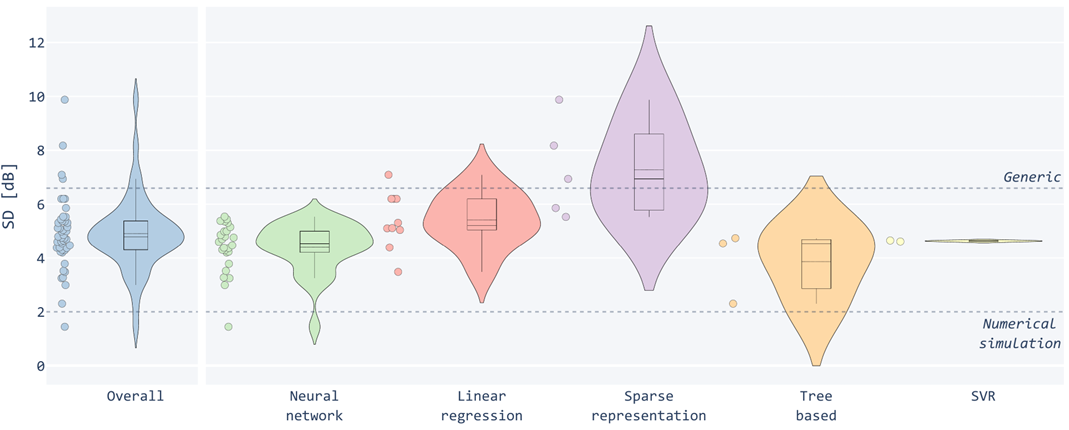
Figure 5: Distributions of SD values reported in the identified studies grouped by ML model.
Rethinking HRTF Evaluation
SD has imperfect correlation with localization performance [10]. Future research should focus on perceptually-driven metrics and establish protocols for subjective evaluation. Furthermore, localization tests only scratch the surface of the spatial audio experience. Future research must evaluate individualized HRTFs in ecological virtual environments, measuring broader perceptual aspects like externalization, immersion, and realism. Additionally, HRTF personalization must be studied alongside other critical factors, including head tracking, Headphone Transfer Functions (HpTFs), reverberation, real-virtual acoustic mismatch, visual stimuli, and HRTF accommodation [11].
Latest Updates
Following the survey publication (January 2025), some notable updates occurred, including the publication of related surveys [12], and tools [13]. The LAP challenge concluded, with winning solutions leveraging ML, stressing its potential benefits and current limitations for HRTF individualization [14, 15]. Finally, the egocentric eHRTF framework was proposed, distinguishing between strong HRTFs—aiming at acoustic fidelity—and weak HRTFs—prioritizing task-specific perceptual adequacy—thereby moving from static measurements to auditory representations updated on listener's feedback [16].
References
[1] J. M. Loomis, R. G. Golledge, and R. L. Klatzky, “Navigation system for the blind: Auditory display modes and guidance,” Presence, vol. 7, no. 2, pp. 193–203, 1998. DOI: 10.1162/105474698565677
[2] B. Xie, Head-Related Transfer Function and Virtual Auditory Display, 2nd ed. New York, NY, USA: J. Ross Publishing, 2013.
[3] E. M. Wenzel, M. Arruda, D. J. Kistler, and F. L. Wightman, “Localization using nonindividualized head-related transfer functions,” J. Acoustical Soc. Amer., vol. 94, no. 1, pp. 111–123, 1993. DOI: 10.1121/1.407089
[4] M. J. Page et al., “PRISMA 2020 explanation and elaboration: Updated guidance and exemplars for reporting systematic reviews,” BMJ, vol. 372, pp. 1–36, 2021. DOI: 10.1136/bmj.n160
[5] A. Andreopoulou and A. Roginska, “Towards the creation of a standardized HRTF repository,” in Audio Engineering Society Convention 131, Audio Engineering Society, 2011.
[6] V. R. Algazi, R. O. Duda, D. M. Thompson, and C. Avendano, “The CIPIC HRTF database,” in Proc. 2001 IEEE Workshop Appl. Signal Process. Audio Acoust., 2001, pp. 99–102. DOI: 10.1109/ASPAA.2001.969552
[7] C. Guezenoc and R. Seguier, “A wide dataset of ear shapes and pinna-related transfer functions generated by random ear drawings,” J. Acoustical Soc. Amer., vol. 147, no. 6, pp. 4087–4096, 2020. DOI: 10.1121/10.0001461
[8] D. Fantini, S. Ntalampiras, G. Presti, and F. Avanzini, “Toward a novel set of pinna anthropometric features for individualizing head-related transfer function,” in Proc. 21th Sound Music Comput. Conf., Porto, Portugal, Jul. 2024, pp. 285–292. DOI: 10.5281/zenodo.14338958
[9] D. Fantini, F. Avanzini, S. Ntalampiras, and G. Presti, “HRTF individualization based on anthropometric measurements extracted from 3D head meshes,” in Proc. 2021 IEEE Immersive 3D Audio: From Architecture Automot., 2021, pp. 1–10. DOI: 10.1109/I3DA48870.2021.9610904
[10] F. C. Tommasini, O. A. Ramos, M. X. Hüg, and F. Bermejo, “Usage of spectral distortion for objective evaluation of personalized HRTF in the median plane,” Int. J. Acoust. Vib., vol. 20, no. 2, pp. 81–89, 2015.
[11] L. Picinali and B. F. G. Katz, System-to-User and User-to-System Adaptations in Binaural Audio. Cham, Switzerland: Springer, 2023, pp. 115–143. DOI: 10.1007/978-3-031-04021-4_4
[12] V. Bruschi, L. Grossi, N. A. Dourou, A. Quattrini, A. Vancheri, T. Leidi, and S. Cecchi, “A review on head-related transfer function generation for spatial audio,” Applied Sciences, vol. 14, no. 23, 11242, 2024. DOI: 10.3390/app142311242
[13] K.C. Poole, J. Meyer, V. Martin, R. Daugintis, N. Marggraf-Turley, J. Webb, L. Pirard, N. La Magna, O. Turvey, and Picinali, L., “HRTF modeling using physical features,” in Proceedings of the 11th Convention of the European Acoustics Association Forum Acusticum / EuroNoise 2025, 2025, pp. 6483–6486. DOI: 10.61782/fa.2025.0864
[14] A. O. T. Hogg, R. Barumerli, R. Daugintis, K. C. Poole, F. Brinkmann, L. Picinali, and M. Geronazzo, “Listener Acoustic Personalization Challenge - LAP24: Head-Related Transfer Function Upsampling,” IEEE Open Journal of Signal Processing, vol. 6, pp. 926-941, 2025, DOI: 10.1109/OJSP.2025.3588776
[15] R. Daugintis, R. Barumerli, M. Geronazzo, J. Pauwels, L. Picinali, and K. C. Poole, “Listener Acoustic Personalization Challenge—LAP24: Head-Related Transfer Function Dataset Harmonization,” IEEE Open Journal of Signal Processing, vol. 6, pp. 950–964, 2025, doi: 10.1109/OJSP.2025.3592601
[16] Geronazzo, M., “Strong and weak Head-related transfer functions: The eHRTF analytical framework,” JASA Express Letters, vol. 5, no. 8, 2025. DOI: 10.1121/10.0038961
