
Contributed by Yingfan Tao based on the IEEEXplore® article "Frontal-Centers Guided Face: Boosting Face Recognition by Learning Pose-Invariant Features" published in IEEE Transactions on Information Forensics and Security, 2022.
Introduction
In recent years, face recognition has made a remarkable breakthrough due to the emergence of deep learning. However, compared with frontal face recognition, plenty of deep face recognition models still suffer serious performance degradation when handling profile faces. To address this issue, we propose a novel Frontal-Centers Guided Loss (FCGFace) to obtain highly discriminative features for face recognition. Most existing discriminative feature learning approaches project features from the same class into a separated latent subspace. These methods only model the distribution at the identity-level but ignore the latent relationship between frontal and profile viewpoints. Different from these methods, FCGFace takes viewpoints into consideration by modeling the distribution at both the identity-level and the viewpoint-level. At the identity-level, a softmax-based loss is employed for a relatively rough classification. At the viewpoint-level, centers of frontal face features are defined to guide the optimization conducted in a more refined way. Specifically, our FCGFace is capable of adaptively adjusting the distribution of profile face features and narrowing the gap between them and frontal face features during different training stages to form compact identity clusters. Extensive experimental results on popular benchmarks, including cross-pose datasets (CFP-FP, CPLFW, VGGFace2-FP, and Multi-PIE) and non-cross-pose datasets (YTF, LFW, AgeDB-30, CALFW, IJB-B, IJB-C, and RFW), have demonstrated the superiority of our FCGFace over the SOTA competitors.
Frontal-Centers Guided Loss
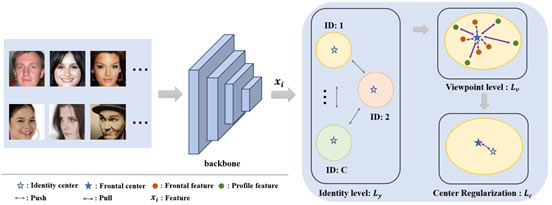
Fig. 1. An overview of the proposed method. A mini-batch input consists of samples from two views, i.e., frontal and profile.
Backbone is used to extract features (xi). The proposed method first projects features into the hypersphere to form C identity-level clusters. Then, the viewpoint-level loss enforces features to close to their corresponding frontal centers.
Finally, the center regularization term is used to pull the identity center and the frontal center of the same class together.
Most discriminative feature learning methods only model the distribution at the identity-level by pulling samples from the same identity closer and pushing samples from different identities far away. However, these methods may ignore the latent relationship between frontal and profile viewpoints. To this end, we propose a novel loss function, termed FCGFace, to explore the relationship between different viewpoints. As shown in Fig. 1, motivated by [1], we model the feature distribution at both the identity-level and viewpoint-level. At the identity-level, different identities are pushed far away from each other to form identity clusters, and each cluster has one identity center. At the viewpoint-level, we define a frontal center for each identity to guide the optimization during training. Our purpose is to enforce the profile face features to be distributed as compactly as frontal features in the hypersphere. To realize this aim, a novel loss is proposed to optimize intra-class (features with positive frontal centers) and inter-class (features with negative frontal centers) distances. Inspired by SFace [2], two sigmoid curves are introduced as the weights of intra-class and inter-class terms, respectively. Moreover, we not only optimize intra-class and inter-class objectives but also adaptively adjust the distribution of side-view features to obtain more compact clusters. Finally, a center regularization term is employed to connect the identity-level centers and their corresponding frontal centers.
In addition, to illustrate the effectiveness of our method, we show the similarity distributions of baseline (ArcFace [3]) and FCGFace in Fig. 2. One can observe that our method virtually increases the expectation margin by 0.03 (0.67-0.64) and 0.11 (0.39-0.28) on Frontal-Frontal and Frontal-Profile verification, respectively. The larger expectation margin typically indicates better performance, since it means more discriminative features are learned.

Fig. 2. Illustration of similarity distributions about ArcFace and our method.
Cosine similarity distributions of positive pairs and negative pairs on CFP-FF and CFP-FP are shown in the first two pictures (FF) and the last two pictures (FP), respectively. The vertical dashed line indicates the expectation of this distribution. Compared with ArcFace, our method increases the expectation differences between positive pairs and negative pairs on both CFP-FF and CFP-FP.
The models we use to extract features are trained on CASIA-WebFace with ResNet50.
Conclusion
In this paper, we propose a novel Frontal-Centers Guided Loss for the task of face recognition. Our key idea is to learn pose-invariant features by narrowing the distribution gap between frontal features and profile features. To carry out this idea, we make a relatively rough classification of the training dataset at the identity-level and exploit frontal centers at the viewpoint-level to guide the feature learning implemented in a more refined way. Our FCGFace encourages greater intra-class compactness and inter-class separability and further enhances the discriminative ability of deep features. Extensive experiments on popular face recognition benchmarks have demonstrated the superiority of our approach over the state-of-the-art competitors.
References:
[1] Z. Zhu, X. Jiang, F. Zheng, X. Guo, F. Huang, X. Sun, and W. Zheng, “Aware loss with angular regularization for person re-identification,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 13 114–13 121.
[2] Y. Zhong, W. Deng, J. Hu, D. Zhao, X. Li and D. Wen, "SFace: Sigmoid-Constrained Hypersphere Loss for Robust Face Recognition," in IEEE Transactions on Image Processing, vol. 30, pp. 2587-2598, 2021, doi: https://dx.doi.org/10.1109/TIP.2020.3048632.
[3] J. Deng, J. Guo, N. Xue and S. Zafeiriou, "ArcFace: Additive Angular Margin Loss for Deep Face Recognition," 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 4685-4694, doi: https://dx.doi.org/10.1109/CVPR.2019.00482.
