



Popular Pages
Today's:
- Information for Authors
- IEEE Transactions on Information Forensics and Security
- (ASRU 2025) 2025 IEEE Automatic Speech Recognition and Understanding Workshop
- (ICME 2026) 2026 IEEE International Conference on Multimedia and Expo
- IEEE Transactions on Multimedia
- IEEE Signal Processing Letters
- Information for Authors-SPL
- IEEE Transactions on Image Processing
- Submit a Manuscript
- Submit Your Papers for ICASSP 2026!
- (ICASSP 2026) 2026 IEEE International Conference on Acoustics, Speech, and Signal Processing
- Conference Call for Papers
- IEEE Transactions on Audio, Speech and Language Processing
- IEEE JSTSP Special Issue on Advanced AI and Signal Processing for Low-Altitude Wireless Networks
- (CAI 2026) IEEE Conference on Artificial Intelligence 2026
All time:
- Information for Authors
- Submit a Manuscript
- IEEE Transactions on Image Processing
- IEEE Transactions on Information Forensics and Security
- IEEE Transactions on Multimedia
- IEEE Transactions on Audio, Speech and Language Processing
- IEEE Signal Processing Letters
- IEEE Transactions on Signal Processing
- Conferences & Events
- IEEE Journal of Selected Topics in Signal Processing
- Information for Authors-SPL
- Conference Call for Papers
- Signal Processing 101
- IEEE Signal Processing Magazine
- Guidelines
Last viewed:
- IEEE Transactions on Image Processing
- (CAI 2026) IEEE Conference on Artificial Intelligence 2026
- Guidelines
- (ICIP 2026) 2026 IEEE International Conference on Image Processing
- Submit Your Papers for ICASSP 2026!
- (MMSP 2025) 2025 IEEE 26th International Workshop on Multimedia Signal Processing
- Information for Authors
- Professional Development
- (ICASSP 2025) 2025 IEEE International Conference on Acoustics, Speech and Signal Processing
- (ASRU 2025) 2025 IEEE Automatic Speech Recognition and Understanding Workshop
- SPS SPTM TC Webinar: Unlimited Sensing: Redefining Digital Acquisition, Representation and Signal Processing
- SPS Webinar: BYOL for Audio: Exploring Pre-Trained General-Purpose Audio Representations
- IEEE Journal of Selected Topics in Signal Processing (JSTSP) Special Series on AI in Signal & Data Science -- Toward Large Language Model (LLM) Theory and Applications
- Guidelines for Preparing Electronic Graphics
- Members
Deep Learning for Visual Understanding: Part 2




Top Reasons to Join SPS Today!
1. IEEE Signal Processing Magazine
2. Signal Processing Digital Library*
3. Inside Signal Processing Newsletter
4. SPS Resource Center
5. Career advancement & recognition
6. Discounts on conferences and publications
7. Professional networking
8. Communities for students, young professionals, and women
9. Volunteer opportunities
10. Coming soon! PDH/CEU credits
Click here to learn more.
Deep Learning for Visual Understanding: Part 2
Visual perception is one of our most essential and fundamental abilities that enables us to make sense of what our eyes see and interpret the world that surrounds us. It allows us to function and, thus, our civilization to survive. No sensory loss is more debilitating than blindness as we are, above all, visual beings. Close your eyes for a moment after reading this sentence and try grabbing something in front of you, navigating your way in your environment, or just walking straight, reading a book, playing a game, or perhaps learning something new. Of course, please do not attempt to drive a vehicle. As you would realize again and appreciate profoundly, we owe so much to this amazing facility. It is no coincidence that most of the electrical activity in the human brain and most of its cerebral cortex is associated with visual understanding.
Computer vision is the field of study that develops solutions for visual perception. In other words, it aims to make computers understand the seen data in the same way that human vision does. It incorporates several scientific disciplines such as signal processing, machine learning, applied mathematics, sensing, geometry, optimization, statistics, and data sciences to name a few. It is concerned with the extraction, modeling, analysis, and use of information from a single image or a sequence of images across a spectrum of modalities for building intelligent systems.
As our visual perception of the world is reflected in our ability to make decisions through what we see, providing such analytical capabilities to computers makes it possible to design remarkable applications that enhance our lives. Computer vision solutions are acting everywhere, including in our:
- computer mouse, determining its motion
- phones, reading our fingerprints
- cameras, controlling lenses
- mail centers, sorting parcels
- warehouse robots, retrieving packages
- gateways, recognizing faces
- vehicles, assisting drivers
- hospitals, diagnosing medical problems
- factories, performing inspections
- farmlands, harvesting produce
- dressers, checking the style of our outfits.
As well as revolutionizing technologies for autonomous vehicles and virtual reality devices, it will soon unfold a transformative and disruptive impact on our culture and economy.
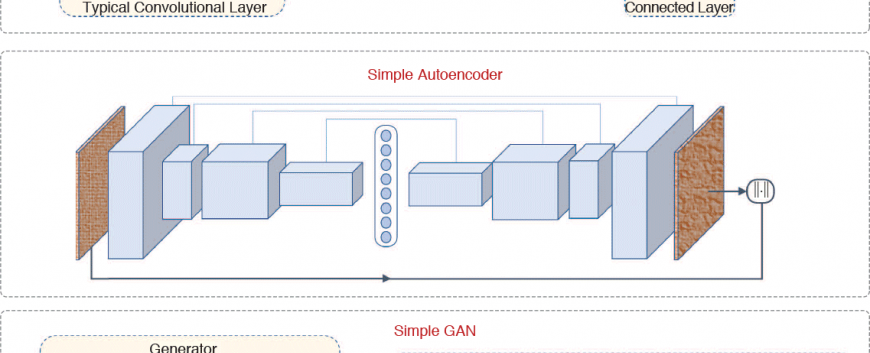
On the journey of developing algorithms that can match human visual perception, most of the progress happened within the last decade with the rebirth of artificial neural networks in computer vision, in particular, convolutional architectures. Ascribing to their complex and layered structures, a broader family of data-driven machine-learning methods based on neural network models today is called deep learning. An illustration of common deep-learning networks such as convolutional neural networks, autoencoders, and generativeadversarial networks (GANs) can be seen in Figure 1, and a very comprehensive discussion of different deep-learning techniques for visual understanding also can be found in the tutorial articles in the first part of this special issue in the November 2017 issue of IEEE Signal Processing Magazine (SPM).
There are many compelling advantages of deep-learning methods. In their cascaded layers that can contain hundreds of millions of parameters, they can model highly nonlinear functions. With their pooling layers that can generate multiple levels of representations corresponding to different levels of abstraction, they can coalesce the information from local and global receptive fields. They can run efficiently on parallel processors with their feed-forward characteristics. Since they learn what part of the data is relevant and discriminative from training samples automatically, they are not limited to handcraft - ed descriptors and manually defined transformations. Most importantly, they can learn from their mistakes when provided with such cases and become superior as the amount of training data increases. The success of deeplearning methods also reflects on the volume of the scientific publications. Deep-learn - ing-related articles in main computer vision venues boosted from fewer than 100 in 2012 to an astounding level of more than 1,000 in 2017.
The November 2017 special issue of SPM on deep learning for visual understanding surveyed deep-learning solutions under reinforcement; weakly supervised and multimodal settings, investigated their robustness; and presented overviews of their applications in domain adaptation, hashing, semantic segmentation, metric learning, inverse problems in imaging, image-to-text generation, and picture-quality assessment.
SPS Social Media
- IEEE SPS Facebook Page https://www.facebook.com/ieeeSPS
- IEEE SPS X Page https://x.com/IEEEsps
- IEEE SPS Instagram Page https://www.instagram.com/ieeesps/?hl=en
- IEEE SPS LinkedIn Page https://www.linkedin.com/company/ieeesps/
- IEEE SPS YouTube Channel https://www.youtube.com/ieeeSPS
IEEE SPS Educational Resources
IEEE SPS Resource Center

IEEE SPS YouTube Channel
