
Contributed by Dr. Qian Huang, based on the IEEEXplore® article, “Deep Learning for Camera Autofocus” published in the IEEE Transactions on Computational Imaging in February 2021 and the SPS Webinar, “Deep Learning for All-in-Focus Imaging” available on the SPS Resource Center.
Introduction
Defocusing is inevitable for lens-based imaging. Better lenses associated with larger apertures and longer focal lengths are more prone to defocusing. As the defocusing can be modeled as convolution, a classic solution for restoring all-in-focus images is deconvolution. The method is straightforward yet prone to noise. Another and perhaps more favorable strategy is focus stacking, i.e., capturing multiple frames with regard to distinct focal planes and exporting the composites from the stack. As the high-frequency information of the whole scene is preserved by the stack, we can expect a better quality of all-in-focus estimates.
Conventional focus stacking approaches like [1] assume a static scene. Typically the focus range is required to be thoroughly swept at least once to form the focal stack, and the final composite is achieved by weighted combining the frames in the stack. Instead, we expect an intelligent all-in-focus imaging pipeline that can 1) adaptively control the focal planes with the awareness of the environment and 2) seamlessly composite the stack with minimum artifacts incurred. The pipeline should also extend focus stacking to dynamic settings.
Pipeline
We propose an all-in-focus imaging pipeline based on deep learning. Our code is available on GitHub.
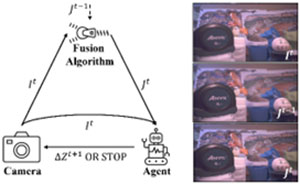
Fig. 1. All-in-focus imaging pipeline (left) and image demonstrations (right). Dashed arrows denote previous information at timestamp t-1. Images from top to bottom are the current captured frame It, the previous fused frame J(t-1), and the current fused frame Jt.
As illustrated in Figure 1, the camera, focus control agent and fusion algorithm in our system dynamically collaborate in a loop. At the timestamp t, the sensor data It is captured and first fed into the fusion algorithm. The fusion algorithm produces its best estimate Jt by merging the in-focus regions of It and the last fused frame J(t-1). The dynamic control agent investigates the focus state of Jt and It using the autofocus algorithm and provides a distance ΔZ(t+1) for the focus motor of the camera to travel. In the tasks where only the final composite of a static scene is needed, the agent also has the option to terminate the loop if further capture does not improve the quality of the fused image. The pipeline is intelligent in the sense that it can evaluate the environment and provide feedback to optimize the all-in-focus estimates.
Fusion
On observing the similarity in problem settings between multifocal fusion and reference-based super-resolution (RefSR), we applied transfer learning techniques to adapt a state-of-the-art RefSR neural architecture AWnet [2] for all-in-focus fusion under static or dynamic scenes. The training dataset for the fusion algorithm was synthetic, where we regarded high-quality videos from DAVIS dataset [3] as the ground truth and generated defocused images through the depth-aware defocusing model. Figure 2 shows a sample frame and its synthetic defocused frames. The data were used to train the fusion network and the dynamic control agent.

Fig. 2. A sample frame and its synthetic defocused frames. (a): a sample frame from DAVIS dataset [3] and its depth estimated by [4]. (b): the synthetic defocused frames regarding different focus positions.
The trained network performed well on training data and test data as shown here. And we expect improved fusion quality when we have better dynamic control.
Autofocus (AF)
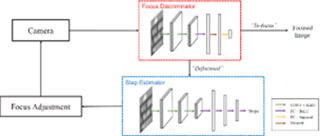
Fig. 3. Overview of proposed autofocus pipeline. The discriminator and the estimator require 512x512 patches.
We propose an AF pipeline that relies on the image solely. We trained a convolutional neural network (CNN) estimator to determine the absolute motor travel distance to the optimal focus position by observing a single defocused image patch, and a CNN discriminator to evaluate if the patch is out-of-focus. Two CNNs were trained on data synthesized via the calibrated defocusing forward model. The neural AF pipeline operated the estimator and discriminator in a loop as shown in Figure 3, addressing the ambiguity of searching direction and allowing efficient and effective AF in comparison with conventional methods, as shown in Table 1 and Table 2.
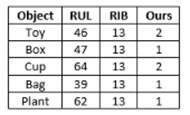
Tab. 1. Steps to reach the in-focus state for real objects. RUL represents the Rule-based search [5] and FIB represents the Fibonacci search [6], both equipped with Tenegrad metric.
Tab. 2. Latency of one step in different AF pipelines based on 512x512 image patches. The GPU and CPU were NVIDIA GeForce GTX 1070 and 2.7 GHz Intel Core i5, respectively.

Focus Control
The neural estimator was extended to a global estimator that can densely predict motor travel distances. Using that as a tool, we developed a reinforcement learning agent that can dynamically estimate the physical environment from the observed frames, take the feedback of the focus state in the region of interest, and control the focus trajectory in response. The pipeline is shown in Figure 4.
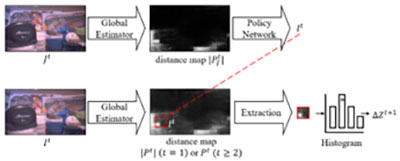
Fig. 4. Reinforcement focus control. Distance maps generated via the global step estimator were visualized in grayscale, where whiter regions indicate larger motor travel distances. The location of the focus window (red bounding box) is estimated by the policy network.
The criterion to train the policy network is based on the reward function. As we encourage the camera to focus on the defocused region of the fusion result, the reward for each timestamp will be 1 if ΔZ^(t+1) is larger than a predefined threshold, and 0 otherwise. The training of the reinforcement agent is to maximize the expected reward of the focus trajectory.
We tested the performance of the all-in-focus imaging and displayed our results here. In a static scene, full-range scanning was no longer required. Instead, the agent captured the minimum number of frames that cover the range of objects. We see the pipeline also works well in a dynamic scene where the camera was moving.
References:
[1] C. Zhou, D. Miau, and S. K. Nayar. “Focal Sweep Camera for Space-Time Refocusing.” Technical Report, Department of Computer Science, Columbia University, 2012.
[2] M. Cheng, Z. Ma, M Salman Asif, Y. Xu, H. Liu, W. Bao, and J. Sun. "A Dual Camera System for High Spatiotemporal Resolution Video Acquisition," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 10, pp. 3275-3291, 1 Oct. 2021, doi: https://dx.doi.org/10.1109/TPAMI.2020.2983371.
[3] F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross and A. Sorkine-Hornung, "A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation," 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016, pp. 724-732, doi: https://dx.doi.org/10.1109/CVPR.2016.85.
[4] Z. Li, T. Dekel, F. Cole, R. Tucker, N. Snavely, C. Liu, and W. T. Freeman. "Learning the Depths of Moving People by Watching Frozen People," 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 2019, pp. 4516-4525, doi: https://dx.doi.org/10.1109/CVPR.2019.00465.
[5] E. Krotkov. “Focusing,” International Journal of Computer Vision, 1(3):223–237, 1988, https://doi.org/10.1007/BF00127822.
[6] N. Kehtarnavaz, H.-J. Oh, “Development and real-time implementation of a rule-based auto-focus algorithm, Real-Time Imaging, Volume 9, Issue 3, 2003, Pages 197-203, OSSN 1077-2014, https://doi.org/10.1016/S1077-2014(03)00037-8.
[7] C. Wang, Q. Huang, M. Cheng, Z. Ma and D. J. Brady, "Deep Learning for Camera Autofocus," in IEEE Transactions on Computational Imaging, vol. 7, pp. 258-271, 2021, doi: https://doi.org/10.1109/TCI.2021.3059497.
