



Popular Pages
Today's:
- Information for Authors
- (ICME 2026) 2026 IEEE International Conference on Multimedia and Expo
- Submit Your Papers for ICASSP 2026!
- IEEE Transactions on Image Processing
- Call for Papers for ICASSP 2026 Now Open!
- IEEE Transactions on Information Forensics and Security
- (ICASSP 2026) 2026 IEEE International Conference on Acoustics, Speech, and Signal Processing
- Submit a Manuscript
- IEEE Transactions on Multimedia
- Conference Call for Papers
- Unified EDICS
- IEEE JSTSP Special Issue on Advanced AI and Signal Processing for Low-Altitude Wireless Networks
- IEEE Signal Processing Letters
- (ASRU 2025) 2025 IEEE Automatic Speech Recognition and Understanding Workshop
- Information for Authors-SPL
All time:
- Information for Authors
- Submit a Manuscript
- IEEE Transactions on Image Processing
- IEEE Transactions on Information Forensics and Security
- IEEE Transactions on Multimedia
- IEEE Transactions on Audio, Speech and Language Processing
- IEEE Signal Processing Letters
- IEEE Transactions on Signal Processing
- Conferences & Events
- IEEE Journal of Selected Topics in Signal Processing
- Information for Authors-SPL
- Conference Call for Papers
- Signal Processing 101
- IEEE Signal Processing Magazine
- Guidelines
Last viewed:
- Membership Board
- Editorial Board
- 2025 59th Asilomar Conference on Signals, Systems, and Computers
- IEEE Transactions on Multimedia
- Overview Articles
- 3 Industries That Will Be Transformed By AI, Machine Learning And Big Data In The Next Decade
- (ICME 2019) 2019 IEEE International Conference on Multimedia and Expo
- Affiliates
- Join a Technical Committee
- Technical Working Groups
- Membership
- Community & Involvement
- Contact Technical Committee
- Technical Committees
- IFS TC Home
A Guide to Computational Reproducibility in Signal Processing and Machine Learning







Top Reasons to Join SPS Today!
1. IEEE Signal Processing Magazine
2. Signal Processing Digital Library*
3. Inside Signal Processing Newsletter
4. SPS Resource Center
5. Career advancement & recognition
6. Discounts on conferences and publications
7. Professional networking
8. Communities for students, young professionals, and women
9. Volunteer opportunities
10. Coming soon! PDH/CEU credits
Click here to learn more.
A Guide to Computational Reproducibility in Signal Processing and Machine Learning
A computational experiment is deemed reproducible if the same data and methods are available to replicate quantitative results by any independent researcher, anywhere and at any time, granted that they have the required computing power. Such computational reproducibility is a growing challenge that has been extensively studied among computational researchers as well as within the signal processing and machine learning research community [1] , [2] .
Introduction
Signal processing research is in particular becoming increasingly reliant on computational experiments to test hypotheses and validate claims, which is in contrast to the past, when one typically used computational experiments to elucidate rigorous theory and mathematical proofs. Therefore, it has become more important than ever to ensure the reproducibility of computational experiments as this is the first step in confirming the validity of research claims supported through the outcomes of computational experiments. But this is not turning out to be an easy task. The paradigm shift from theory-driven research to compute-driven claims in signal processing and machine learning has been facilitated by powerful computing resources; the accessibility of massive datasets; and a myriad of new libraries and frameworks (such as NumPy [3], Scikit-learn [4], MATLAB Toolboxes [5], and TensorFlow [6]) that provide a layer of abstraction allowing for rapid implementation of complex algorithms. Unfortunately, this changing research landscape is also bringing with it new obstacles and unseen challenges in developing reproducible experiments.
Computational experiments today often incorporate various scripts for preprocessing data, running algorithms, and plotting results, all while utilizing huge datasets that require computing clusters that often take days or weeks to finish computing with multiple manual interventions needed to successfully produce the desired results. This is contrary to the way computational experiments used to be conducted and the way new researchers are introduced to computational resources in the classroom, where they typically use simple and intuitive interactive computing software consisting of a single script that runs locally on one’s computer [7]. This new paradigm of computational experiments is now requiring the scientific community to rethink how we publicize and share our code to encapsulate all the necessary information about our experiments and make computational reproducibility practically possible (see “The Evolution of Computational Experiments”).
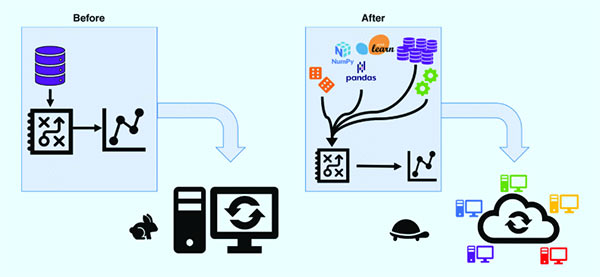
Figure S1.
Components of traditional computational experiments (left). Modern computational experiments which are far more complex and slower to run (right).
SPS Social Media
- IEEE SPS Facebook Page https://www.facebook.com/ieeeSPS
- IEEE SPS X Page https://x.com/IEEEsps
- IEEE SPS Instagram Page https://www.instagram.com/ieeesps/?hl=en
- IEEE SPS LinkedIn Page https://www.linkedin.com/company/ieeesps/
- IEEE SPS YouTube Channel https://www.youtube.com/ieeeSPS
IEEE SPS Educational Resources
IEEE SPS Resource Center

IEEE SPS YouTube Channel
