
Deep-learning-based audio-visual speech enhancement

Contributed by Dr. Daniel Michelsanti, based on the IEEEXplore® article, “An Overview of Deep-Learning-Based Audio-Visual Speech Enhancement and Separation”, published in the IEEE/ACM Transactions on Audio, Speech, and Language Processing in March 2021, and the SPS webinar, “Audio-visual Speech Enhancement and Separation Based on Deep Learning,” available on the SPS Resource Center.
We all experienced the discomfort of communicating with our friends at a cocktail party or in a pub with loud background music. When difficult acoustic scenarios like these occur, we tend to rely on several visual cues, such as lips and mouth movement of the speaker, in order to understand the speech of interest. In fact, visual information is essentially unaffected by the acoustic background noise. The design of an automatic system that can effectively extract the speech of interest from both acoustic and visual information is a challenging task that can benefit several applications.
Applications
Audio-visual speech enhancement and separation systems can be particularly useful in a range of different applications.
When using a videoconference system, users might be speaking from noisy environments (such as a cafe or a hall with talkers in the background). Adopting a speech enhancement method to suppress the background noise would benefit the communication among the users.
Audio-visual speech enhancement and separation may also be important for noise reduction in video post-production or in live videos (consider, for example, the scenario where a news correspondent is speaking from a busy square).
In the future, audio-visual speech enhancement systems can also be used in hearing aid applications, where multimodal wearable devices can be connected to a hearing instrument and improve its noise reduction capabilities.
Terminology
Let x[n] and d[n] indicate the clean speech of interest and an additive noise signal, respectively, where n denotes a discrete-time index. It is possible to model the acoustic speech signal as y[n]=x[n]+d[n]. The task of determining an estimate x^[n] of x[n] given y[n] is known as audio-only speech enhancement. When a visual signal, generally consisting of video frames capturing the mouth region of the target speaker, is provided as input to the system, we talk about audio-visual speech enhancement. If the acoustic signal, y[n], is not accessible, then the task of estimating the target speech signal solely from visual information of the speaker is known as speech reconstruction from silent videos.
Sometimes, the observed acoustic signal is a mixture of several speech signals from different speakers. The task of extracting each of these speech signals from the acoustic mixture and visual information of the speakers is known as audio-visual speech separation.
A representation of the difference between the aforementioned tasks is shown in Figure 1.
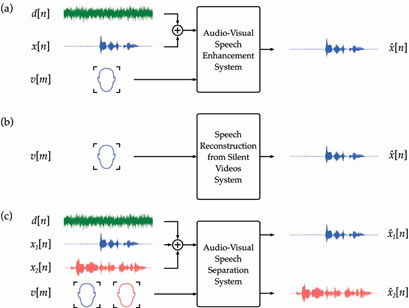
Figure 1. Difference between audio-visual speech enhancement, speech reconstruction from silent videos and audio-visual speech separation. [1]
System Elements
Audio-visual speech enhancement and separation have recently been addressed with deep learning methods. In most cases, a supervised learning framework is adopted: a deep learning model is trained to find a mapping between pairs of degraded and clean speech signals, together with the video of the speakers. During inference, an audio-visual signal is used as input of the system and an estimated clean speech (or multiple clean speech signals in the case of speech separation) is provided as output. Deep-learning-based audio-visual speech enhancement and separation systems usually consists of six main elements: acoustic features; visual features; deep learning methods; fusion techniques; training targets; objective functions.
Figure 2 shows how these elements are interconnected in a typical audio-visual system. For further details, please refer to [2].

Figure 2. Main elements of a speech enhancement and separation system.
Audio-Visual Speech Datasets
Datasets have a central role in the development of deep learning-based audio-visual speech enhancement and separation systems. Most of the audio-visual speech datasets contain clean speech signals of several speakers, which are then used to create synthetic ones with overlapping speakers and/or acoustic background noise.
It is possible to divide the datasets into two categories: data collected in controlled environment and data gathered in the wild. For data collected in controlled, we usually have a complete control of the experimental setup in terms of recording equipment, speakers (language, gender etc.), environment, and linguistic content. This data is good to investigate specific topics such as the effect of different angles of view on the system performance, the impact of Lombard effect and how a system can preserve a speaker emotion through the enhancement or separation process. On the other hand, datasets in the wild are characterised by a vast variety of speakers, sentences, languages, and auditory/visual environments. They are particularly suitable to train large deep learning models that generalise well to real-world situations.
Figure 3 shows some of the datasets that can be used for audio-visual speech enhancement and separation. A more detailed list can be found in https://github.com/danmic/av-se.
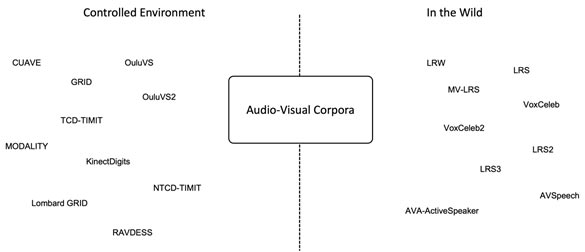
Figure 3. Non-exhaustive list of datasets in a controlled environments and datasets in the wild.
Performance Assessment
The performance of speech enhancement and separation approaches are usually assessed using two perceptual aspects: speech quality, which consists of all the attributes concerning how a speaker produces an utterance, and speech intelligibility, which is related to what a speaker says.
Ideally, subjective listening tests with a panel of subjects are conducted to assess the speech quality and intelligibility performance of a system. However, they are often costly and time consuming. Therefore, objective measures are used to estimate the results of listening tests.
Some of the most used evaluation methods are reported in Figure 4. A more detailed list can be found in https://github.com/danmic/av-se.
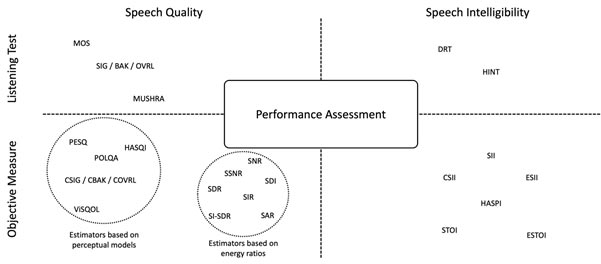
Figure 4. Non-exhaustive list of evaluation methods for speech enhancement and separation.
References:
[1] D. Michelsanti (2021). Audio-Visual Speech Enhancement Based on Deep Learning. Aalborg Universitetsforlag. Ph.d.-serien for Det Tekniske Fakultet for IT og Design, Aalborg Universitet https://doi.org/10.54337/aau422930170.
[2] D. Michelsanti, Z.-H. Tan, S.-X. Zhang, Y. Xu, M. Yu, D. Yu, & J. Jensen. (2021). An overview of deep-learning-based audio-visual speech enhancement and separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, 1368-1396. https://doi.org/10.1109/TASLP.2021.3066303.
