



Popular Pages
Today's:
- Signal Processing Cup
- Information for Authors
- IEEE Transactions on Information Forensics and Security
- Submit Your Papers for ICASSP 2026!
- Call for Papers for ICASSP 2026 Now Open!
- Video & Image Processing Cup
- MLSP TC Home
- Distinguished Lecturer Program
- Women in Signal Processing
- Login Error
- IEEE Transactions on Multimedia
- Editorial Board
- Information for Authors-SPL
- (ICIP 2026) 2026 IEEE International Conference on Image Processing
- Editorial Board
All time:
- Information for Authors
- Submit a Manuscript
- IEEE Transactions on Image Processing
- IEEE Transactions on Information Forensics and Security
- IEEE Transactions on Multimedia
- IEEE Transactions on Audio, Speech and Language Processing
- IEEE Signal Processing Letters
- IEEE Transactions on Signal Processing
- Conferences & Events
- IEEE Journal of Selected Topics in Signal Processing
- Information for Authors-SPL
- Conference Call for Papers
- Signal Processing 101
- IEEE Signal Processing Magazine
- Guidelines
Last viewed:
- (ACSSC 2018) 2018 Asilomar Conference on Signals, Systems and Computers
- IEEE Transactions on Information Forensics and Security
- IEEE Open Journal of Signal Processing
- (ICIP 2025) 2025 IEEE International Conference on Image Processing
- MLSP TC Home
- Distinguished Industry Speakers
- Membership
- SPS Webinar: An Anomaly Detection Framework with Compressed Transformer Architecture for Tiny ML
- SPS Webinar: Signal Processing for Expressive Neural Networks: Toward Lightweight Intelligence
- SAM TC Home
- Signal Processing Cup
- Synthetic Aperture Technical Working Group
- Our Story
- Jobs in Signal Processing
- Research Assistant
Robust Subspace Learning







Top Reasons to Join SPS Today!
1. IEEE Signal Processing Magazine
2. Signal Processing Digital Library*
3. Inside Signal Processing Newsletter
4. SPS Resource Center
5. Career advancement & recognition
6. Discounts on conferences and publications
7. Professional networking
8. Communities for students, young professionals, and women
9. Volunteer opportunities
10. Coming soon! PDH/CEU credits
Click here to learn more.
Robust Subspace Learning
Principal component analysis (PCA) is one of the most widely used dimension reduction techniques. A related easier problem is termed subspace learning or subspace estimation. Given relatively clean data, both are easily solved via singular value decomposition (SVD). The problem of subspace learning or PCA in the presence of outliers is called robust subspace learning (RSL) or robust PCA (RPCA). For long data sequences, if one tries to use a single lower-dimensional subspace to represent the data, the required subspace dimension may end up being quite large. For such data, a better model is to assume that it lies in a low-dimensional subspace that can change over time, albeit gradually. The problem of tracking such data (and the subspaces) while being robust to outliers is called robust subspace tracking (RST). This article provides a magazine-style overview of the entire field of RSL and tracking. In particular, solutions for three problems are discussed in detail:
- RPCA via sparse+low-rank (S+LR) matrix decomposition
- RST via S+LR
- robust subspace recovery (RSR).
RSR assumes that an entire data vector is either an outlier or an inlier. The S+LR formulation instead assumes that outliers occur on only a few data vector indices and, hence, are well modeled as sparse corruptions.
PCA finds application in a variety of scientific and data analytics’ problems ranging from exploratory data analysis and classification, e.g., image retrieval or face recognition, to a variety of modern applications such as video analytics, recommendation system design, and understanding social networks 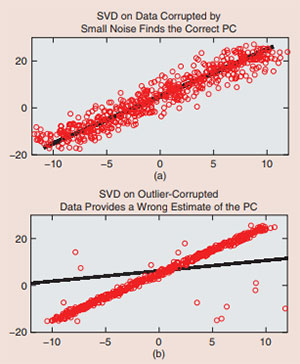 dynamics. PCA finds a small number of orthogonal basis vectors, called principal components (PCs), along which most of the variability of the data set lies. In most applications, only the subspace spanned by the PCs (principal subspace) is of interest. For example, this is all that is needed for dimension reduction. This easier problem is typically called subspace learning or subspace estimation: the two terms are sometimes used interchangeably. Given a matrix of clean data, PCA is easily accomplished via SVD on the data matrix. The same problem becomes much harder if the data is corrupted by even a few outliers. The reason is that SVD is sensitive to outliers. We show an example of this in Figure 1. In today’s big data age, since data is often acquired using a large number of inexpensive sensors, outliers are becoming even more common. They occur due to various reasons such as node or sensor failures, foreground occlusion of video sequences, or abnormalities or other anomalous behavior on certain nodes of a network. The harder problem of PCA or subspace learning for outlier corrupted data is called RPCA or RSL.
dynamics. PCA finds a small number of orthogonal basis vectors, called principal components (PCs), along which most of the variability of the data set lies. In most applications, only the subspace spanned by the PCs (principal subspace) is of interest. For example, this is all that is needed for dimension reduction. This easier problem is typically called subspace learning or subspace estimation: the two terms are sometimes used interchangeably. Given a matrix of clean data, PCA is easily accomplished via SVD on the data matrix. The same problem becomes much harder if the data is corrupted by even a few outliers. The reason is that SVD is sensitive to outliers. We show an example of this in Figure 1. In today’s big data age, since data is often acquired using a large number of inexpensive sensors, outliers are becoming even more common. They occur due to various reasons such as node or sensor failures, foreground occlusion of video sequences, or abnormalities or other anomalous behavior on certain nodes of a network. The harder problem of PCA or subspace learning for outlier corrupted data is called RPCA or RSL.
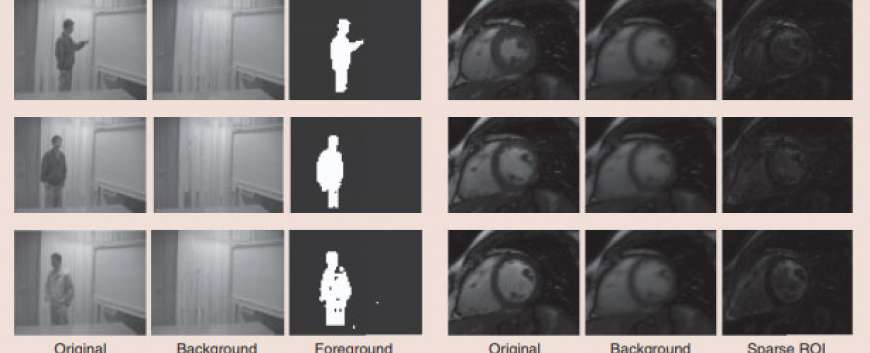
dynamics. PCA finds a small number of orthogonal basis vectors, called principal components (PCs), along which most of the variability of the data set lies. In most applications, only the subspace spanned by the PCs (principal subspace) is of interest. For example, this is all that is needed for dimension reduction. This easier problem is typically called subspace learning or subspace estimation: the two terms are sometimes used interchangeably. Given a matrix of clean data, PCA is easily accomplished via SVD on the data matrix. The same problem becomes much harder if the data is corrupted by even a few outliers. The reason is that SVD is sensitive to outliers. We show an example of this in Figure 1. In today’s big data age, since data is often acquired using a large number of inexpensive sensors, outliers are becoming even more common. They occur due to various reasons such as node or sensor failures, foreground occlusion of video sequences, or abnormalities or other anomalous behavior on certain nodes of a network. The harder problem of PCA or subspace learning for outlier corrupted data is called RPCA or RSL.Since the term outlier does not have a precise mathematical meaning, the RPCA problem was, until recently, not well defined. Even so, many classical heuristics existed for solving it, e.g., see [1] and [2] and references therein. In recent years, there have been multiple attempts to qualify this term. Most popular among these is the idea of treating an outlier as an additive sparse corruption, which was popularized in the work of Wright and Ma [3]. This is a valid definition because it models the fact that outliers occur infrequently and allows them to have any magnitude. In particular, their magnitude can be much larger than that of the true data points. Using this definition, the recent work by Candès et al. [4] defined RPCA as the problem of decomposing a given data matrix, M, into the sum of a low-rank matrix, L, whose column subspace gives the PCs and a sparse matrix (outliers’ matrix), S. This definition, which is often referred to as the S+LR formulation, has led to numerous interesting new works on RPCA solutions, many of which are provably correct under simple assumptions, e.g., [4]–[10]. A key motivating application is video analytics: decomposing a video into a slowly changing background video and a sparse foreground video [2], [4]; see an example in Figure 2(a). The background changes slowly, and the changes are usually dense (not sparse). It is thus well modeled as a dense vector that lies in the low-dimensional subspace of the original space [4]. The foreground usually consists of one or more moving objects, and is thus correctly modeled as the sparse outlier.
SPS Social Media
- IEEE SPS Facebook Page https://www.facebook.com/ieeeSPS
- IEEE SPS X Page https://x.com/IEEEsps
- IEEE SPS Instagram Page https://www.instagram.com/ieeesps/?hl=en
- IEEE SPS LinkedIn Page https://www.linkedin.com/company/ieeesps/
- IEEE SPS YouTube Channel https://www.youtube.com/ieeeSPS
IEEE SPS Educational Resources
IEEE SPS Resource Center

IEEE SPS YouTube Channel
