



Popular Pages
Today's:
- SA-TWG Webinar: Channel Estimation for Beyond Diagonal RIS via Tensor Decomposition
- Unified EDICS
- France Chapter
- Inside Signal Processing Newsletter
- Information for Authors
- A beloved horse dies in the night, and a startup is born bringing AI and machine learning to animals
- Submit a Manuscript
- Information for Authors-SPM
- (ICME 2026) 2026 IEEE International Conference on Multimedia and Expo
- Call for Nominations for Fellow Evaluation Committee Member Extended
- Award Recipients
- 3 ways machine learning will improve your marketing
- Statistical and Deep Learning Schemes for Maritime RADAR Detection and Surveillance
- Membership
- IEEE Transactions on Multimedia
All time:
- Information for Authors
- Submit a Manuscript
- IEEE Transactions on Image Processing
- IEEE Transactions on Information Forensics and Security
- IEEE Transactions on Multimedia
- IEEE Transactions on Audio, Speech and Language Processing
- IEEE Signal Processing Letters
- IEEE Transactions on Signal Processing
- Conferences & Events
- IEEE Journal of Selected Topics in Signal Processing
- Information for Authors-SPL
- Conference Call for Papers
- Signal Processing 101
- IEEE Signal Processing Magazine
- Guidelines
Last viewed:
- Information for Authors-SPM
- Submit a Manuscript
- Editorial Board Nominations
- IEEE Signal Processing Magazine
- SPS Staff
- France Chapter
- Call for Nominations for Fellow Evaluation Committee Member Extended
- Exploiting Cellular Signals for Navigation: 4G to 5G
- Unified EDICS
- A beloved horse dies in the night, and a startup is born bringing AI and machine learning to animals
- Nominate an IEEE Fellow today!
- Conferences & Events
- SA-TWG Webinar: Channel Estimation for Beyond Diagonal RIS via Tensor Decomposition
- SPS Resource Center
- Postdoc in Statistical Signal Processing, Network Science, and Deep Learning Applied to Brain Imaging Data at the University of Maryland, College Park
IEEE ICASSP 2018 Conference Review
Top Reasons to Join SPS Today!
1. IEEE Signal Processing Magazine
2. Signal Processing Digital Library*
3. Inside Signal Processing Newsletter
4. SPS Resource Center
5. Career advancement & recognition
6. Discounts on conferences and publications
7. Professional networking
8. Communities for students, young professionals, and women
9. Volunteer opportunities
10. Coming soon! PDH/CEU credits
Click here to learn more.
IEEE ICASSP 2018 Conference Review
The 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2018) was held on April 15-20, 2018 in Calgary, Alberta, Canada.
The technical program was very strong with 1,406 papers presented in 187 oral or poster sessions. The technical committee for speech and language processing included 636 papers, having a strong presence in the conference. There were many papers on speech recognition, where the main theme was end-to-end systems. The areas of speaker recognition/verification, and speech synthesis were also dominant in the conference. The program also had three sessions on speech emotion recognition, an area that I am particularly interested. This area has steadily increased its presence in recent ICASSP. In many of these areas, the key themes for me were sequential modeling and unsupervised learning. For sequential modeling a key challenge is to capture the temporal dependencies in the data, where the trends were attention model, connectionist temporal classification, recurrent neural network (RNN) and convolutional neural network (CNN). For unsupervised learning, the key challenge is to leverage unlabeled data commonly collected in different environments. A popular framework for this task was the teacher-student model.
The conference had four keynotes. Prof. Julia Hirschberg presented the first keynote, discussing the effort on her group to detect deception from speech. This is a hard problem, which was illustrated by playing examples where the audience had no idea whether the subjects were lying or telling the truth. Her group has collected corpora to evaluate acoustic features that are discriminative for this task, obtaining accuracies that are above human performance level. The second keynote was presented by Dr. Alex Acero, where he discussed the transformative role of deep learning, especially in the area of automatic speech recognition (ASR). His presentation mentioned different technologies that revolutionized the world, suggesting that deep learning is one of them. Dr. Acero highlighted the important role of advances in hardware in this revolution to process and storage big data. The third keynote was presented by Prof. Yann LeCun who summarized his journey, highlighting the contributions of CNN. He presented his view about the next transformative technologies in machine-learning, describing the need for prediction-based self-supervised learning. The last keynote was presented by Dr. Luc Vincent, who discussed advances on transportation, emphasizing the developments at Lyft. His keynote addressed the challenges in signal processing and machine-learning to have a hybrid network with self-driving cars and cars operated by human.
The first ICASSP that I attended was in 2007 in Honolulu, Hawaii (nice location to start my journey!). The most common words in the name of the sessions were (in order): processing, signal, analysis, speech, coding, image, estimation, modeling, video, methods, applications, and topics. In ICASSP 2018, most of these words were still very common: processing, signal, learning, speech, image, applications, deep, analysis, recognition, estimation, video, and modeling. The new words that appeared this year in the title of multiple technical sessions were learning, deep and recognition. While this exercise provides an oversimplified view of the focus of the conference, it reveals an important shift in signal processing toward machine-learning. This shift was clear in the keynotes in the conference, especially the presentations by Dr. Yann LeCun (Power and Limits of Deep Learning for Signal Understanding) and Dr. Alex Acero (The Deep Learning Revolution).
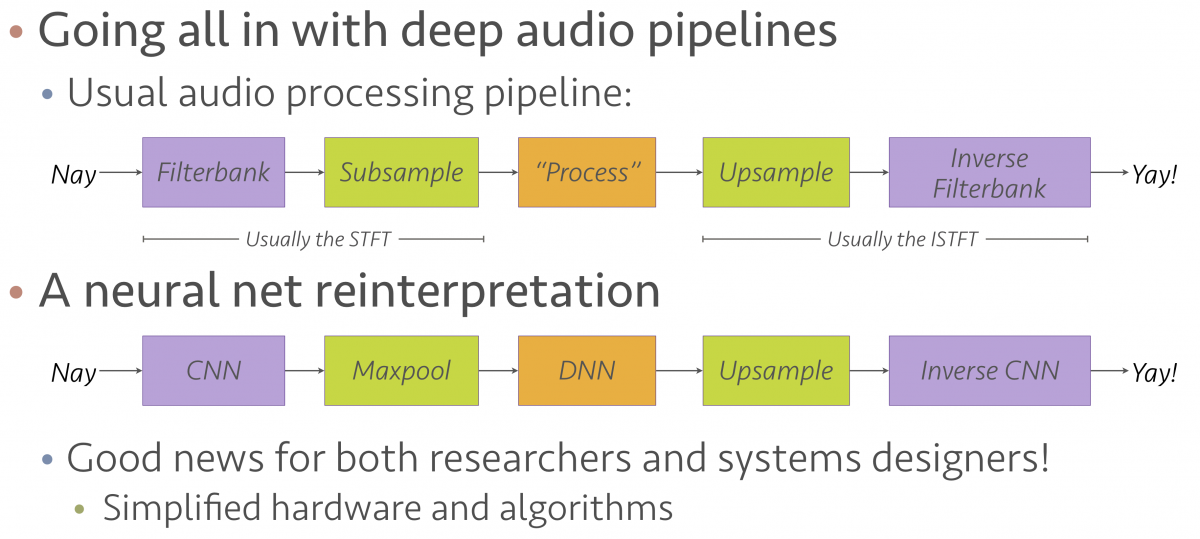
I attended an interesting panel discussion on Innovation Forum on “Signal Processing and Artificial Intelligence: Challenges and Opportunities”. The panel brought valuable insights on the role of signal processing in this era dominated by machine-learning. Prof. Paris Smaragdis made an interesting analogy between a classical signal processing pipeline and current machine-learning based pipeline (see Figure 1). He suggested that the steps in deep learning closely resemble the building blocks that we have used for many years in signal processing. Today, we have better tools. Prof. LeCun mentioned that a researcher with background in signal processing has clear advantages over other researchers, especially in the formulation and understanding of new problems. The overall message in the panel was that our community has a golden opportunity to continue making contributions in this new AI revolution. We may need to do a better job in advertising our work to broader and strengthen our community so our conferences can have the same grow experienced by other AI conferences.
Figure 1: Analogy between classical signal processing pipeline and current machine-learning based pipeline. Credit to Prof. Paris Smaragdis.
SPS Social Media
- IEEE SPS Facebook Page https://www.facebook.com/ieeeSPS
- IEEE SPS X Page https://x.com/IEEEsps
- IEEE SPS Instagram Page https://www.instagram.com/ieeesps/?hl=en
- IEEE SPS LinkedIn Page https://www.linkedin.com/company/ieeesps/
- IEEE SPS YouTube Channel https://www.youtube.com/ieeeSPS
IEEE SPS Educational Resources
IEEE SPS Resource Center

IEEE SPS YouTube Channel
